Conversational flow in Oxford-style debates
Public debates are a common platform for presenting and juxtaposing diverging views on important issues. In this work we propose a methodology for tracking how ideas flow between participants throughout a debate. We use this approach in a case study of Oxford-style debates—a competitive format where the winner is determined by audience votes—and show how the outcome of a debate depends on aspects of conversational flow. In particular, we find that winners tend to make better use of a debate’s interactive component than losers, by actively pursuing their opponents’ points rather than promoting their own ideas over the course of the conversation.
💡 Research Summary
The paper introduces a computational framework for tracking the flow of ideas in Oxford‑style public debates and demonstrates that these flow patterns are predictive of which side will win. Using transcripts from the Intelligence Squared (IQ2) series, the authors compile a dataset of 108 debates spanning 2006‑2015, each consisting of three rounds: an opening statement, a highly interactive discussion, and a concluding summary. Audience votes taken before and after each debate provide a clear binary outcome (the side with the larger vote‑share increase wins). Additional metadata such as recorded laughter and applause serve as auxiliary signals of audience reaction.
To capture the core arguments each team brings to the debate, the authors first identify “talking points” from the opening statements. They compute word‑frequency differences between the two sides using a log‑odds ratio with a Dirichlet prior, then select the 20 words with the most extreme z‑scores for each side. These word sets represent the salient concepts each team intends to promote.
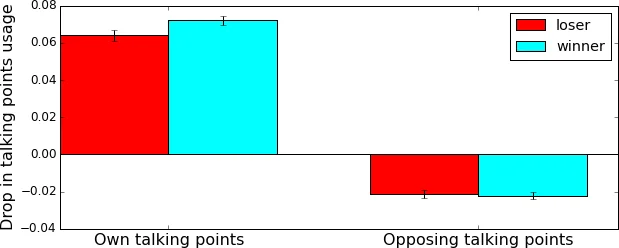
During the discussion round, every utterance is treated as a bag of content words (stopwords removed, stemming applied). Two coverage metrics are defined: self‑coverage f Disc(X,X) – the proportion of a side’s words that belong to its own talking points – and opponent‑coverage f Disc(X,Y) – the proportion that belong to the opponent’s talking points. The authors find that, as soon as the interactive phase begins, self‑coverage drops sharply while opponent‑coverage rises, indicating a shift from monologic exposition to dialogic engagement. Importantly, the magnitude of the self‑coverage decline is larger for the eventual winners (p≈0.08), and winners also tend to reduce overall reliance on any pre‑defined talking points, suggesting a strategic move away from the opening script.
Beyond pre‑defined points, the authors model “discussion points”: words that first appear in the discussion and are subsequently adopted by the opposite side at least twice. Only about 3 % of newly introduced words meet this criterion, roughly ten per debate. Winners adopt significantly more opponent‑originated discussion points than losers (p < 0.01) and, in a manual inspection, 78 % of valid discussion points are later used by the opponent to challenge the original claim. This pattern implies that successful debaters are not merely imposing their own topics but are actively engaging with and contesting the opponent’s ideas.
For predictive evaluation, the authors construct a feature set (“Flow features”) comprising self‑coverage, opponent‑coverage, their changes from introduction to discussion, and the count of adopted discussion points. Baselines include simple length measures (word and turn counts) and a unigram bag‑of‑words model, while an “Audience” baseline uses applause and laughter counts. Using a leave‑one‑out cross‑validation with logistic regression (hyper‑parameters tuned via 3‑fold CV), the Flow model achieves 63 % accuracy; a version with univariate feature selection (Flow*) reaches 65 %, both significantly above the 50 % random baseline (binomial test p < 0.05) and comparable to the Audience baseline (60 %). The most frequently selected Flow* features are: number of adopted discussion points (positive coefficient), recall of own talking points during discussion (negative coefficient), and the drop in usage of own talking points from introduction to discussion (positive coefficient). These results highlight that audience persuasion aligns more with interactive, opponent‑focused strategies than with sheer verbosity or static argumentation.
The paper contributes (1) a richly annotated debate dataset with speaker turns, talking‑point annotations, and audience reaction metadata; (2) a novel method for quantifying idea flow via coverage metrics and discussion‑point adoption; and (3) empirical evidence that conversational dynamics, rather than content volume, drive persuasion in a controlled debate setting. Limitations include treating each team as a single speaker (ignoring intra‑team dynamics) and relying on word‑level representations, which may miss nuanced semantic shifts. Future work could incorporate richer semantic embeddings, dialogue‑act tagging, and fine‑grained turn‑by‑turn interaction modeling to further unravel the mechanisms of persuasive discourse.
Comments & Academic Discussion
Loading comments...
Leave a Comment