Data Cleaning for XML Electronic Dictionaries via Statistical Anomaly Detection
Many important forms of data are stored digitally in XML format. Errors can occur in the textual content of the data in the fields of the XML. Fixing these errors manually is time-consuming and expensive, especially for large amounts of data. There i…
Authors: Michael Bloodgood, Benjamin Strauss
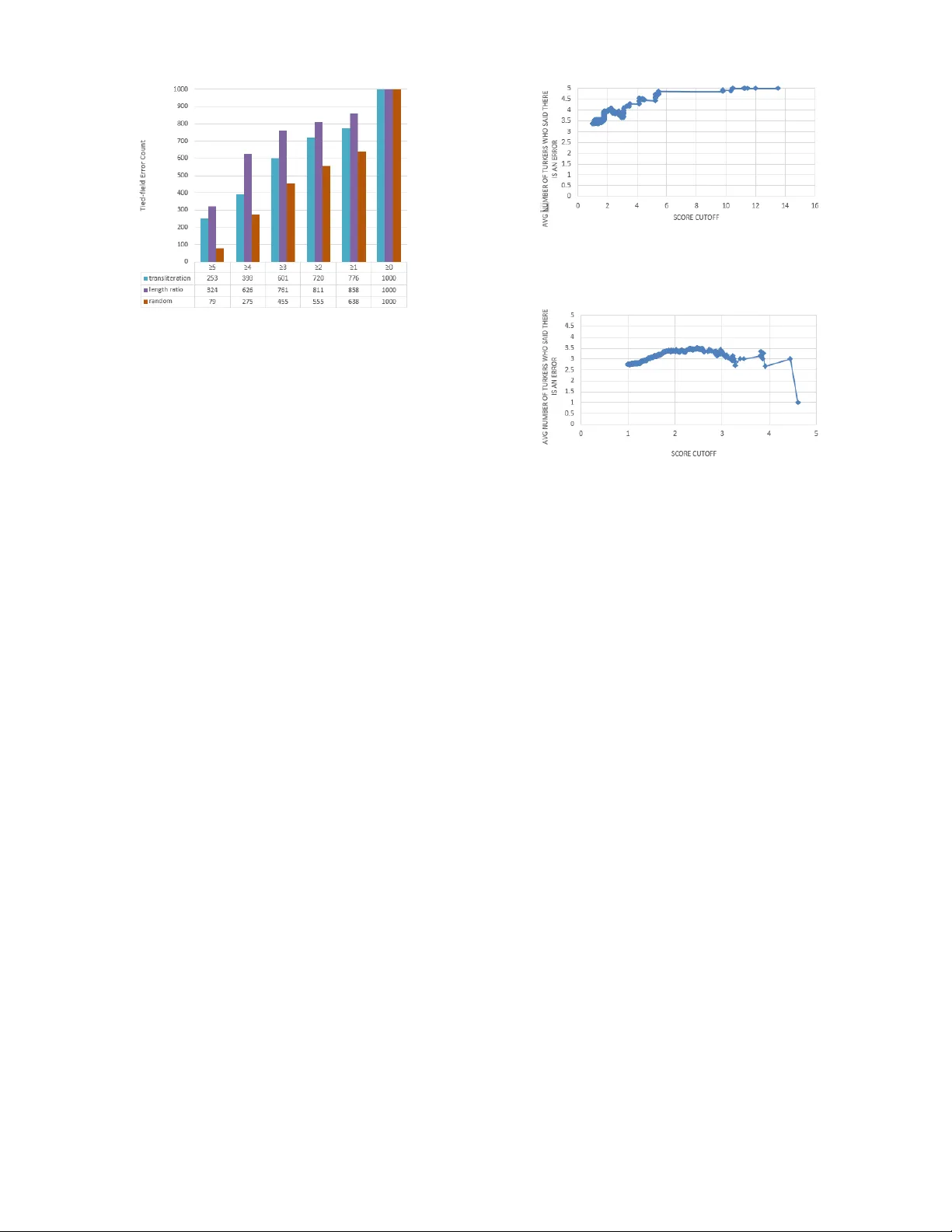
Data Cleaning for XML Electronic Dictionaries via Statistical Anomaly Detection Michael Bloodgood Center for Advanced Study of Language Univ ersity of Maryland College P ark, MD 20742 meb@umd.edu Benjamin Strauss † Department of Computer Science and Engineering The Ohio State Univ ersity Columbus, OH 43210 strauss.105@osu.edu Abstract —Many important forms of data are stor ed digitally in XML f ormat. Errors can occur in the textual content of the data in the fields of the XML. Fixing these errors manually is time-consuming and expensive, especially for large amounts of data. There is increasing interest in the research, development, and use of automated techniques for assisting with data cleaning. Electronic dictionaries are an important f orm of data frequently stored in XML format that frequently have errors introduced through a mixture of manual typographical entry errors and optical character recognition errors. In this paper we describe methods for flagging statistical anomalies as likely errors in elec- tronic dictionaries stor ed in XML f ormat. W e describe six systems based on different sources of inf ormation. The systems detect errors using various signals in the data including uncommon characters, text length, character -based language models, word- based language models, tied-field length ratios, and tied-field transliteration models. Four of the systems detect errors based on expectations automatically inferr ed from content within elements of a single field type. W e call these single-field systems. T wo of the systems detect errors based on correspondence expectations automatically inferred from content within elements of multiple related field types. W e call these tied-field systems. For each system, we provide an intuitive analysis of the type of error that it is successful at detecting. Finally , we describe two larger- scale evaluations using cr owdsourcing with Amazon’ s Mechanical T urk platf orm and using the annotations of a domain expert. The evaluations consistently show that the systems are useful for impro ving the efficiency with which errors in XML electronic dictionaries can be detected. I . I N T RO D U C T I O N There is increasing interest in the research, development, and use of automated techniques for assisting with data cleaning , also called data cleansing or scrubbing , which deals with detecting and removing errors and inconsistencies from data in order to improve the quality of data [1]. In this paper we deal with data cleaning of electronic dictionaries stored in Extensible Markup Language (XML) format. XML is a markup language that defines a set of rules for encoding doc- uments in a format that is both human-readable and machine- readable. Defined by free open standards, XML is a textual data format with strong support via Unicode for dif ferent human languages. It is widely used for the representation of † This research was conducted while this author was a Faculty Research Assistant at the Uni versity of Maryland Center for Advanced Study of Language. electronic dictionaries and other forms of structured data [2], [3]. Electronic dictionaries are a fundamentally important se- mantic computing resource. They are a core resource con- sumed by downstream processes in the provision of various human language technologies as well as consumed directly by human language learners and as reference materials more generally . When dictionaries are digitized, whether via manual entry , Optical Character Recognition (OCR), or a mixture of these methods, it is inevitable that errors are introduced into the digitized version that is produced. Prior work has focused on providing editing tools to assist with manual curation of the data and on providing tools for automatically detecting structural errors using only structural information. Although these systems hav e had success in finding dictionary errors, there are many errors that cannot be detected without analyzing the text content of the dictionary . For example, suppose that in some dictionary a lexical entry requires a headword, a part of speech, and a definition. Suppose there is an error in which the definition for some entry appears in the part of speech field, and the definition field contains the headword of the next entry . These errors will not be found by examining only the structure. Unlike previous work, in this paper we present methods for flagging statistical anomalies as likely errors in the textual content itself in electronic dictionaries in XML format using information from the textual content of the data. W e present six systems that detect errors using various signals in the data. The types of data quality problems that our systems are designed to detect are single-source instance lev el data quality problems [1]. Four of our systems detect errors based on information automatically inferred from content within elements of a single field type. W e call these systems single-field systems. T w o of the systems detect errors based on correspondence information automatically inferred from content within elements of multiple related field types. W e call these latter systems tied-field systems. For each system, we provide an intuitiv e analysis of the type of error that it is successful at detecting. Finally , we describe two larger -scale ev aluations using crowdsourcing with Amazon’ s Mechanical T urk platform and using domain expert annotations. The ev aluations consistently sho w that the systems are useful for This paper was published in the Pr oceedings of the 2016 IEEE T enth International Conference on Semantic Computing (ICSC), pages 79-86, Laguna Hills, CA, USA, F ebruary 2016. c 2016 IEEE Link to article abstract in IEEE Xplore: http://dx.doi.org/10.1109/ICSC.2016.38 improving the efficiency with which errors in XML electronic dictionaries can be detected. In the next section we situate our work with respect to previous related work. In section III we describe the error detection systems in detail and provide intuiti ve examples of the sorts of errors that each error detection system finds. In section IV we describe our experimental tests and provide experimental results and discussion of results. Finally , in section V we conclude. I I . R E L A T E D W O R K A categorization of data quality problems addressed by data cleaning and an overvie w of data cleaning methods is provided in [1]. Many data cleaning methods are based on identifying discrepancies for user auditing, e.g., [4], [5]. The system in [4] is highly interactiv e; discrepancy detection is not their sole main focus. The discrepancy detection approach they outline is for users to define domains and then for discrepancies to be located through checking against the user-defined domains for constraint violation. In contrast, the methods in the current paper do not require user specification of domains and the methods in the current paper operate on the basis of dif- ferent sources and indicators of discrepancies. In particular , the methods in the current paper are fundamentally different in that they operate on the basis of statistically anomalous ev ents instead of constraint violations. In [5], a similar overall workflo w is presented whereby the most suspicious examples are flagged for a human operator to inspect and annotate as clean or “garbage. ” In contrast to the current paper , there is only one method in [5], which is to flag the examples with the highest information gain for inspection by a human operator . The work in [5] assumes the context of construction of an automated classifier in the computation of the information gain. The method in [5] is ev aluated on the task of handwritten digit recognition by seeing how well classifier performance improv es with the addition of the data cleaning approach. In contrast, the current paper uses different methods for detecting suspicious examples and does not assume the context of construction of automated classifiers. Also in contrast, the methods in the current paper are ev aluated on XML electronic dictionaries by measuring how many and what percentages of the detected anomalies are annotated as data errors by domain experts. The methods in the current paper may be able to be used in a complementary fashion with the methods from [4] and [5] in future work. Past work presented a method for repairing a digital dictio- nary in an XML format using a dictionary markup language called DML [6]. It remains time-consuming and error-prone howe ver to have a human e xhaustiv ely read through and manually correct a digital version of a dictionary , ev en with languages such as DML a vailable for making corrections once errors are detected. The methods we present in the current paper automatically scan through and detect errors in dictionaries. The methods in the current paper can be used in concert with error correction techniques such as dictionary markup languages. Previous approaches hav e been presented for detecting structural errors in digitized dictionaries [7], [8]. The method in [8] works by linearizing the lexicon structure, conv erting the opening tags in XML into tokens and then considering the likelihoods of v arious strings of tokens using a language modeling approach. Anomalous branches of XML tags are flagged as structural errors. The method ignores the underlying text data within the dictionary and only detects structural errors. The methods in [7] outperform the method from [8]. The methods in [7] use a mixture of unsupervised methods, supervised machine learning methods, and system combination approaches. The highest-performing method uses a random forest system combination approach. The methods in [7] only detect structural errors. Errors in the textual data content within the XML elements are not detected. In contrast, the current paper presents methods that detect errors in the text (data) content of XML elements. The methods in the current paper also use different approaches and different sources of information than were used in [7], [8] and do not require training data, which is often not av ailable. The error detection methods in the current paper can be used in concert with structural error detection methods. I I I . M E T H O D S This section describes ho w our methods work. W e cate- gorize our methods into two types: single-field methods and tied-field methods. Single-field methods work by utilizing information within the data content of a single XML field type in order to detect errors. T ied-field methods work by utilizing information within the data content of multiple XML field types, exploiting various relationships between the data in the different fields, in order to detect errors. For each candidate error, all of our methods return a numeric score indicating the system’ s confidence that the candidate is an error . A threshold can be set for each method to control which candidates are detected as errors. The threshold for each method can be adjusted according to recall-precision 1 preferences and dictionary characteristics. In general, higher thresholds will return results with higher precision and lower recall whereas lower thresholds will return results with lower precision and higher recall. The optimal threshold for each method depends on data characteristics and user preferences. W e are not aware of a method for determining optimal thresholds. W e set our thresholds to a lev el that yielded a reasonable number of error candidates for human revie w . The exact thresholds for each e xperiment are giv en in the following subsections. Subsection III-A describes how the single-field methods work and subsection III-B describes how the tied-field meth- ods work. Subsection III-C provides examples of anomalies detected by the various methods. 1 Recall and precision are standard measures for systems that perform search. For the case of detecting dictionary errors, recall is the percentage of true errors that are found by the system. Precision is the percentage of system-proposed errors that are in fact true errors in the dictionary . A. Single-Field Methods The single-field error detection systems do not require any advance kno wledge about the structure of the electronic dictionary . The only structural context information they use is the tag name of the elements containing the te xt data to be checked. Single-field methods can be used to check for errors in elements of any individual tag name. All single-field methods work according to the following high-level descrip- tion: all entries of an individual tag name are processed and then any entries that are anomalous are flagged as errors. Each single-field method processes the entries and flags anomalies in different ways based on different aspects of the data. The rest of this subsection describes four single-field methods in detail. 1) Uncommon Character s Method: Uncommon characters can be a frequent source of errors in electronic dictionaries. They can arise due to OCR errors, author typographical errors, and mislabeled and/or incorrectly merged fields. T exts that contain uncommon characters are reported as potential errors. For each element in the dictionary with a particular tag, we consider the texts inside those elements to be a collection of documents D , and the characters in the texts as the tokens. W e calculate the in verse document frequency of each character c observed in D as follows: id f ( c, D ) = log 10 N |{ d ∈ D : c ∈ d }| , (1) where N is the number of documents in the collection. When id f ( c, D ) > thr eshold , we consider c to be an uncommon character . The threshold is configurable; we use a default value of four . Users can adjust the threshold ac- cording to their recall-precision preferences and according to dictionary characteristics. The elements containing uncommon characters are flagged by the system as potential errors. 2) T ext Length Method: When two text fields are inappro- priately combined into one field, the result can be text that is unusually long. When a single text unit is inappropriately truncated, or split across tw o fields, the result can be te xt that is unusually short. T exts with unusually long or unusually short length are reported as potential errors. For each element in the dictionary with a giv en tag, we treat the lengths of the texts inside those elements as a sample of a normally distributed population. W e calculate the mean and standard deviation of the sample, and for each value, we calculate the z-score, i.e., the signed number of standard deviations the value is abov e or belo w the mean. If the absolute value of the z-score of the length of a text is abov e a threshold, we flag the text as a possible error . The threshold is configurable; we use a default value of four . As the threshold is raised, only the most unusually long, or short, fields will be returned as errors. 3) W or d Sequence Method: Language modeling can capture the probability of a sequence of words occurring in textual content. This giv es us the capability to flag unlikely sequences of words. These unlikely sequences can often be indicativ e of typographical errors, OCR errors, incorrect field joining and splitting, etc. T exts that are unlikely given a word-le vel language model of texts in the same context are reported as potential errors. For each element in the dictionary with a giv en tag, we build a language model of the text content of all the elements using n-grams of words. W e calculate the entropy of the model with respect to each individual element’ s text, and treat the entropies as a sample of a normally distributed population. W e calculate the z-score of each entropy score. High z-scores indicate texts that are unlikely in the language model. The texts with entropy z-scores abov e a threshold are flagged as errors. The size of the n-grams in the language model and the threshold are configurable. W e use 4-grams and threshold five by default. Using a larger n-gram size in the language model allows one to potentially capture more nuanced sequence characteristics, howe ver , it would require a much larger amount of data to estimate properly and av oid introducing spurious estimates due to data sparsity . Also, larger n-gram sizes are more computationally intensiv e. The entropy z-score thresholds can be adjusted according to recall- precision preferences and dictionary characteristics. 4) Character Sequence Method: This method is similar to the W ord Sequence Method, except that instead of n- grams of words, we build language models using n-grams of characters. The size of the n-grams in the language model and the threshold are configurable. W e use 4-grams and a threshold of five by default. Larger n-gram sizes could potentially capture more nuanced character sequence models, howe ver , they would require a much larger amount of data to estimate properly and av oid introducing spurious estimates due to data sparsity . The n-gram size can also be adjusted based on the language of the field’ s textual content. The entropy z- score thresholds can be adjusted according to recall-precision preferences and dictionary characteristics. Note that the error detection system based on character sequences will in some cases find errors that the Uncommon Character system also detects, but the Character Sequence Method is also capable of finding some errors that the Uncommon Character system is not able to find. This is because the Character Sequence Method can find errors in which none of the characters in the textual content is particularly uncommon, but in which the ordering of those characters is incorrect. B. T ied-F ield Methods In many structured data sets, there are pairs of fields that are related to each other in predictable ways. For example, in dictionaries a word in a language’ s nati ve orthography and a phonetic transcription of the word are related because in many languages there are predictable relationships between spelling and pronunciation. Another related pair of fields in bilingual dictionaries is an example sentence demonstrating usage of a word and its translation. W e call these sorts of related fields tied fields and we call error detection methods that exploit relationships between content in different field types tied-field methods. It is possible for there to be errors in a single field where the data value in that field is not anomalous in the context of only other v alues in that field type. Howe ver , the value might be anomalous in the context of data T ABLE I E X AM P L E S O F O RTH O G R AP H Y - P RO NU N C I A TI O N PA I RS . S HO RT S TR I N GS H A VE A D I FF E RE N T D I S TR I B UT I O N O F L E N G TH R A T IO S T HA N L ON G S T RI N G S . Short Long Orth Pron Ratio Orth Pron Ratio t t ¯ e 0.50 groundwork ground”w ˆ urk‘ 0.83 ease ¯ ez 2.00 lithargyrum l ˘ i*th ¨ ar”j ˘ i*r ˘ um 0.79 v v ¯ e 0.50 haidingerite h ¯ i”d ˘ ing* ˜ er* ¯ it 0.92 values in related fields. The single-field methods presented in subsection III-A will be unable to detect these sorts of errors. The rest of this subsection describes two tied-field methods that can detect these sorts of errors. 1) T ied-F ield Length Ratio Method: This method deter- mines the ratio of length in characters of tied fields; pairs of data values with unusual length ratios are then reported as potential errors. W e treat the ratio of the length in characters of the tied-field data values to be a sample of a normally distributed population. W e calculate the absolute value of the z-score of each length ratio. High values indicate tied-field instances where the data values ha ve an unusual length ratio. T ied-field instances with scores above a threshold are flagged as potential errors. The threshold is configurable; we use a threshold of two by default. The threshold can be adjusted according to recall-precision preferences and dictionary char- acteristics. T o handle situations in which the distribution of length ratios is significantly different for short and long strings, we have an option to partition the tied-field instances by the length of the data in the first field, and treat each partition as its own population. T able I illustrates why it could be beneficial to partition tied-field instances by length. In these examples of correct pairs of data, the length ratios of the short tied-field pairs of data can be seen to vary more than the length ratios of the long tied-field pairs of data. 2) T ied-F ield T ransliter ation Method: F or some tied fields, the data in the two fields have a more specific relationship than a length relationship. For example, in dictionaries some fields are transliterations of each other . Such transliterations will usually have character-le vel correspondences (not necessarily a one-to-one correspondence). If the correspondence can be modeled, then pairs of texts that do not correspond well can be reported as errors. W e use Phonetisaurus 2 to learn transliteration models across tied-fields. The Phonetisaurus system has been described in detail and has been sho wn to perform well in [9]. The resulting transliteration model represents how the first field can be transliterated into the second field, and can be used to generate scored transliteration candidates of the first field. For each pair of tied-fields, we use the transliteration model to transliterate the first field into the n-best candidates for the second field. Each candidate is given a transliteration cost by Phonetisaurus. By taking the in v erse of the cost, we obtain a score indicating the model’ s confidence in that transliteration candidate. W e calculate the normalized 2 https://code.google.com/p/phonetisaurus/ T ABLE II E X AM P L E S O F A NO M A L IE S D E T E CT E D B Y S IN G L E - FI E L D S Y ST E M S . ExampleID FieldName V alue Example 1 GENDER /F . Example 2 NUMBER PLU. Example 3 P AR T -OF-SPEECH P AR TICLE T ABLE III E X AM P L E A N O MA LY D E T E CT E D B Y T IE D - FIE L D S Y S T EM S . ExampleID FieldName V alue Example 4 OR THOGRAPHY Û ± Ø Ù Û Ù ª Ø ¹ Ø ¬ Ø ± Ø PR ONUNCIA TION r ¯ a edit distance (NED) of each candidate to the observed data that actually is present in the second field, and calculate the mean NED weighted by transliteration score. W e treat the weighted means as a sample of a normally distributed population. W e calculate the z-score of each weighted mean. High values indicate that the data occurring in the second field is an unusually large NED aw ay from what our learned model would have expected based on the data that occurred in the first field. Instances with weighted mean z-scores abov e a threshold are flagged as errors. The threshold is configurable; we use a default of two. The weighted mean z-score threshold can be adjusted according to recall-precision preferences and dictionary characteristics. 3 C. Examples In this subsection we provide examples of anomalies de- tected by the various systems. T o obtain these examples, we ran the systems ov er a digitized sample of an Urdu-English dictionary [10] and selected illustrativ e examples that can be understood by most readers without ha ving to know too many details about specific dictionary representations in XML. T able II shows examples detected by the various single-field systems and T able III sho ws an example detected by the tied- field systems. Example 1 in T able II was detected by all four of our single-field systems. This is an error in the data since the value should ha ve been just “F . ” without the “/”. Since the GENDER field almost exclusi vely contains values of “M. ” or “F . ”, the W ord Sequence Method found any other words such as “/F . ” to hav e unusually high entropy . The character- based language model detected this error similarly . The T e xt Length Method detected this error since it is three characters long, which is unusually long given the predominance of two- character-long values in this field. The Uncommon Characters Method detected this error since the “/” character is uncommon in this field. Example 1 shows ho w the different methods can sometimes all detect the same error albeit through dif ferent views of the data. Example 2 in T able II shows an example of an error that was detected by some of the systems and not others. This is an error in the data since the value should hav e been just “PL. ” 3 W e also offer an option to normalize the tied-field te xt data to all lowercase letters. without the “U”. The W ord Sequence Method, the Character Sequence Method, and the Uncommon Characters Method all found this error . The Uncommon Characters Method detected this error since “U” is an uncommon character for values in the NUMBER field. The T ext Length Method did not detect this error . This is because the length of four characters is not unusually long or short for this field - the NUMBER field often contains “PL. ” with length three characters and “SING. ” with length fiv e characters. Example 3 in T able II shows an example of an anomaly that was detected by all four single-field methods that was not erroneous. The W ord Sequence Method and the Character Sequence Method detected it since it had unusually high entropy . The T ext Length Method detected it since it was unusually long. The Uncommon Characters Method detected it since the characters “C”, “E”, “L”, “P”, and “R” are uncommon for this field. For reference, some of the most common values for the part of speech field include “V . ”, “N. ”, “ ADJ. ”, “ AD V . ”, etc. Although “P AR TICLE” is an uncommon value for this field, it is not an error . Example 4 in T able III shows an example detected by both the Tied-Field T ext Length Ratio Method and the T ied- Field Transliteration Method. The OR THOGRAPHY field had the v alue “ Û ± Ø Ù Û Ù ª Ø ¹ Ø ¬ Ø ± Ø ” and the PR ONUNCI- A TION field had the value “r ¯ a”. This is an error resulting from incorrect merging and splitting of fields. The T ext Length Ratio Method detected this as an error since the ratio was un- usually high for values of these two fields. The Transliteration Method detected this as an error since the weighted mean Normalized Edit Distance from the generated pronunciation candidates to the observed pronunciation “r ¯ a” was unusually high. Note that the single-field methods did not detect this error since “ Û ± Ø Ù Û Ù ª Ø ¹ Ø ¬ Ø ± Ø ” is not an anomalous value for OR THOGRAPHY in isolation and neither is “r ¯ a” an anomalous v alue for PR ONUNCIA TION in isolation. It is only when they are tied to each other that an anomaly is detected. The examples help to illustrate on a small scale what types of errors the various methods can detect. Also, the examples show how sometimes the methods have ov erlapping behavior and sometimes the methods ha ve complementary behavior . The examples also illustrate ho w sometimes the methods detect errors in the data that need to be corrected and sometimes the methods detect anomalies that, while rare, are not errors that need to be corrected. In the next section we provide lar ger-scale e v aluations of the error detection methods. I V . E V A L UA T I O N W e used Amazon’ s Mechanical T urk crowdsourcing plat- form to e valuate the Tied-Field Length Ratio Method, the T ied-Field Transliteration Method, and a random sample of data. Mechanical T urk is an online crowdsourcing platform where workers, also called T urkers, complete simple tasks called Human Intelligence T asks (HITs). Crowdsourcing can allow ine xpensiv e and rapid data collection for various Natural Language Processing (NLP) tasks [11], [12], [13], including human ev aluations of NLP systems [14], [15], [16], [17], [18]. Fig. 1. Screenshot of interface for ev aluating tied-field error detection systems. The tied fields that we used in our ev aluation were the orthography and the corresponding pronunciation fields from the GNU Collaborati ve International Dictionary of English (GCIDE). GCIDE is a freely av ailable dictionary of English based on W ebster’ s 1913 Revised Unabridged Dictionary and supplemented with entries from W ordNet [19], [20], [21] and additional submissions from users. GCIDE is formatted in XML and is available for download from www .ibiblio.or g/ webster/. Out of the 16704 pairs of orthography-pronunciation values in the dictionary , our tied-field error detection systems identified 2797 of the pairs as possible errors. From this set of detected candidate errors, we randomly selected 1000 pairs detected by the tied-field length ratio system and 1000 pairs detected by the tied-field transliteration system for ev aluation by T urkers. For each candidate error , we asked fi ve T urkers if the orthography-pronunciation pair was correct. Figure 1 shows a screenshot of the Mechanical T urk interface we used. If a T urker judged that a pair was not correct, i.e., that the pair was truly an error , then the T urker was required to provide an explanation. By requiring an explanation when pairs are incorrect, we are, if anything, creating a bias where workers will tend tow ards saying pairs are correct since that is easier for them. This will cause, if anything, the efficacy of our error detection systems to be understated. Figure 2 displays counts of proposed orthography-to- pronunciation errors judged to be real errors by the T urkers for the tied-field transliteration and the tied-field length ratio error detection systems as well as for randomly selected examples. The x-axis shows the number of T urkers that agreed a proposed error was a real error . Recall that for each of the proposed errors we had asked fiv e Turk ers to judge whether it was a real error or not. The y-axis sho ws the number of proposed errors that were judged to be real errors. The main observation is that both the tied-field transliteration system and the tied-field length ratio system find many more errors than the random selection system. In particular, observe that for the tied-field transliteration system three or more T urkers agree its proposed errors are really errors more than 60% of the time; for the tied-field length ratio system three or more T urkers agree its proposed errors are really errors more than 76% of Fig. 2. Counts of proposed errors judged to be real errors by at least 5, 4, 3, 2, 1, and 0 Turk ers. the time. In contrast, for randomly selected proposed errors, three or more T urkers agree they are really errors only about 45.5% of the time. These results are evidence that the error detection systems could substantially increase the ef ficiency with which domain experts can clean XML data. Diving a little deeper , Figure 3 and Figure 4 sho w the av erage number of T urkers that agree a proposed error is really an error for proposed errors at varying score cutoffs. Figure 3 shows the information for the tied-field length ratio error detection system. In Figure 3, the score cutof f on the x-axis is the absolute value of the z-score. The absolute value is used because this error detection system finds errors with both unusually high and unusually low z-scores. The y-axis is the av erage number of T urkers (out of 5) who marked the proposed errors with scores above the corresponding cutof f as real errors. Figure 4 shows similar information for the tied- field transliteration error detection system. In Figure 4, the score cutoff on the x-axis is the z-score. The z-score is used because this error detection system finds errors with unusually high z-scores. The y-axis is the a verage number of T urkers (out of 5) who marked the proposed errors with scores abov e the corresponding score cutoff as real errors. For systems that will be used for purposes of ranking proposed errors in order from most likely to least likely , it is desirable that they predict errors with higher accuracy above a particular score threshold. This has positiv e implications for application settings where users will go through errors in a sorted order from most likely to least likely . Figure 3 and Figure 4 show that from this perspectiv e the length ratio sys- tem produces better results. The length ratio system correctly predicts consistently with a cutoff over 5.5 standard deviations from the av erage. In contrast, the transliteration system does not perform as well because it is unable to predict errors with as high a degree of precision as the length ratio system at any score cutoff. A perhaps surprising result in Figure 4 is that the transliteration system decreases in precision when the score cutoff increases past about 2.5 standard deviations from the average. This result can be explained by the low number of proposed errors with very high scores with the transliteration Fig. 3. The a verage number of Turkers (out of 5) who believ e the orthography-pronunciation pair is an error for varying score cutoffs for the length ratio system. The score is the absolute value of the z-score. Fig. 4. The a verage number of Turkers (out of 5) who believ e the orthography-pronunciation pair is an error for varying score cutoffs for the transliteration system. The score is the z-score. system. This can create the situation where there are too few data points to compute a precision score reliably . T able IV displays the overlap of the errors most strongly proposed by the length ratio error detection system and the transliteration error detection system for varying cutoff sizes. This table allows us to ev aluate the similarity between the two systems. The two systems do not have a high degree of similarity; for example, only 4 of the top 100 anomalies detected by the length ratio system also appear in the top 100 anomalies detected by the transliteration system. The low lev els of ov erlap indicate that the systems ha ve complementary behavior . This complementary behavior can be leveraged to build improved hybrid systems. The four single-field methods can also be combined with each other and with the tied-field methods. By combining methods a hybrid system could be built that takes into account different perspecti ves on the data. There are many possible ways of combining methods to build a hybrid system, e.g., see [7]. In future work, it would be worthwhile to explore how to optimally combine the error detection methods to create an improv ed system. W e conducted an additional ev aluation of our systems using the annotations of a language expert in the process of correct- ing errors in a T amasheq dictionary containing 5968 lexical entries. The language expert ev aluated 175 anomalies proposed by the single-field text length system and the single-field uncommon character system for data in fields POS (part of speech) and MAIN (headword). The language expert marked each proposed anomaly as either a real error or not a real error . The results are in T able V. These results are further evidence that the error detection systems could substantially T ABLE IV O V E RL A P O F T HE A NO M A L IE S M OS T ST R ON G L Y P RO PO S E D B Y T H E L E NG T H R A T I O A N D T H E T R A NS L I T ER A T I O N S Y ST E M S . Number of Proposed Errors Number of Common Results Percent 10 0 0% 25 1 4% 50 3 6% 100 4 4% 200 16 8% 300 31 10% 400 52 13% 500 81 16% 600 110 18% 700 143 20% 800 173 22% 900 186 21% 1000 227 23% 1500 396 26% 2000 563 28% T ABLE V L A NG UA G E E X P E RT A N N OTA T IO N S O N 1 75 A N OM A L I ES P RO PO S E D B Y T H E T E X T L E N GT H S YS T E M A N D T H E U N CO M M O N C H A R AC TE R S YS T E M F O R D A TA I N FI EL D S P O S A N D M A I N . System Field Real Error No Error T otal Uncommon POS 16 1 17 Character System MAIN 4 10 14 T e xt Length POS 110 3 113 System MAIN 30 1 31 increase the efficienc y with which domain experts can clean XML data. V . C O N C L U S I O N There is increasing interest in methods for computer-aided rapid data cleaning. W e presented multiple methods for data cleaning of XML electronic dictionaries. The methods detect errors in the data content of the XML, unlike pre vious work that detected errors in the structure of the XML electronic dictionaries and ignored the content. The methods are based on different underlying sources and indicators of errors and have complementary behavior with each other and with previously dev eloped methods. The methods can be classified into single- field methods and tied-field methods. Single-field methods detect anomalies on the basis of expectations inferred from content in the same single field type. T ied-field methods detect anomalies on the basis of expectations of content correspon- dences inferred from content in multiple related fields. Four single-field methods for error detection were presented that work by using expectations of word sequence information, expectations of character sequence information, expectations of length, and expectations of individual characters in partic- ular fields. T wo tied-field methods for error detection were presented that work by using e xpectations of length ratios and expectations of string correspondences via transliteration models. The precision of the error detection systems tends to cor- relate with the internal scores of the systems. This desirable behavior supports the scenario where a domain expert would go down a sorted list of proposed errors from most likely to least likely . The performance of the different error detection systems v aries based on the XML fields and the dictionaries on which they are applied. Domain experts can choose to in voke error detection system-field combinations with score cutoffs to suit their needs. W e ev aluated these methods using the crowdsourcing plat- form Mechanical T urk and using expert annotations on multi- ple datasets. Sometimes the systems have overlapping behav- ior , detecting the same errors albeit through different views of the data. Often the systems hav e complementary behavior , which is promising for hybrid system construction in the future. W e provided intuitive examples of the sorts of errors each of the systems can detect. In the ev aluations, the systems are consistently helpful in increasing the efficienc y with which data errors can be identified. A C K N O W L E D G M E N T This material is based upon work supported, in whole or in part, with funding from the United States Government. Any opinions, findings and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the vie ws of the Univ ersity of Maryland, College Park and/or any agency or entity of the United States Gov ernment. R E F E R E N C E S [1] E. Rahm and H. H. Do, “Data cleaning: Problems and current ap- proaches, ” IEEE Data Eng. Bull. , vol. 23, no. 4, pp. 3–13, 2000. [2] N. Ide and J. V eronis, T ext encoding initiative: Backgr ound and contexts . Springer Science & Business Media, 1995, vol. 29. [3] G. Francopoulo, M. George, N. Calzolari, M. Monachini, N. Bel, M. Pet, and C. Soria, “Lexical markup framework (LMF), ” in Proceedings of the F ifth International Conference on Language Resources and Evaluation (LREC 2006) . Genoa, Italy: European Language Resources Association, May 2006, pp. 233–236. [4] V . Raman and J. M. Hellerstein, “Potter’ s wheel: An interactiv e data cleaning system, ” in VLDB , vol. 1, 2001, pp. 381–390. [5] I. Guyon, N. Matic, and V . V apnik, “Discovering informativ e patterns and data cleaning, ” in Advances in knowledge discovery and data mining . American Association for Artificial Intelligence, 1996, pp. 181–203. [6] D. Zajic, M. Maxwell, D. Doermann, P . Rodrigues, and M. Bloodgood, “Correcting errors in digital lexicographic resources using a dictionary manipulation language, ” in Pr oceedings of the Confer ence on Electr onic Lexicogr aphy in the 21st Century . Bled, Slovenia: Trojina, Institute for Applied Slovene Studies, November 2011, pp. 297–301. [Online]. A vailable: http://www .trojina.si/elex2011/elex2011 proceedings.pdf [7] M. Bloodgood, P . Y e, P . Rodrigues, D. Zajic, and D. Doermann, “ A random forest system combination approach for error detection in digital dictionaries, ” in Proceedings of the W orkshop on Innovative Hybrid Appr oaches to the Processing of T extual Data . A vignon, France: Association for Computational Linguistics, April 2012, pp. 78–86. [Online]. A vailable: http://www .aclweb .or g/anthology/W12- 0511 [8] P . Rodrigues, D. Zajic, D. Doermann, M. Bloodgood, and P . Y e, “Detecting structural irregularity in electronic dictionaries using language modeling, ” in Pr oceedings of the Conference on Electr onic Lexicogr aphy in the 21st Century . Bled, Slovenia: Trojina, Institute for Applied Slovene Studies, November 2011, pp. 227–232. [Online]. A vailable: http://www .trojina.si/elex2011/elex2011 proceedings.pdf [9] J. R. Novak, N. Minematsu, and K. Hirose, “WFST-based grapheme-to- phoneme conv ersion: Open source tools for alignment, model-building and decoding, ” in Pr oceedings of the 10th International W orkshop on F inite State Methods and Natur al Languag e Pr ocessing . Donostia–San Sebasti ´ an: Association for Computational Linguistics, July 2012, pp. 45–49. [Online]. A v ailable: http://www .aclweb .org/anthology/W12- 6208 [10] B. A. Qureshi and A. Haq, Standar d T wenty First Century Urdu-English Dictionary . Delhi: Educational Publishing House, 1991. [11] R. Snow , B. O’Connor , D. Jurafsky , and A. Ng, “Cheap and fast – but is it good? e valuating non-expert annotations for natural language tasks, ” in Pr oceedings of the 2008 Confer ence on Empirical Methods in Natural Language Processing . Honolulu, Hawaii: Association for Computational Linguistics, October 2008, pp. 254–263. [Online]. A vailable: http://www .aclweb .org/anthology/D08- 1027 [12] M. Bloodgood and C. Callison-Burch, “Bucking the trend: Large- scale cost-focused activ e learning for statistical machine translation, ” in Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics . Uppsala, Sweden: Association for Computational Linguistics, July 2010, pp. 854–864. [Online]. A vailable: http://www .aclweb .or g/anthology/P10- 1088 [13] M. Negri, L. Benti vogli, Y . Mehdad, D. Giampiccolo, and A. Marchetti, “Divide and conquer: Crowdsourcing the creation of cross-lingual textual entailment corpora, ” in Pr oceedings of the 2011 Conference on Empirical Methods in Natural Language Pr ocessing . Edinbur gh, Scotland, UK.: Association for Computational Linguistics, July 2011, pp. 670–679. [Online]. A vailable: http://www .aclweb .org/anthology/ D11- 1062 [14] C. Callison-Burch, “Fast, cheap, and creative: Evaluating translation quality using Amazon’ s Mechanical Turk, ” in Proceedings of the 2009 Confer ence on Empirical Methods in Natural Language Processing . Singapore: Association for Computational Linguistics, August 2009, pp. 286–295. [Online]. A vailable: http://www .aclweb .org/anthology/D/ D09/D09- 1030 [15] M. Bloodgood and C. Callison-Burch, “Using mechanical turk to build machine translation e valuation sets, ” in Proceedings of the N AACL HLT 2010 W orkshop on Cr eating Speech and Language Data with Amazon’ s Mechanical T urk . Los Angeles, California: Association for Computational Linguistics, June 2010, pp. 208–211. [Online]. A vailable: http://www .aclweb .org/anthology/W10- 0733 [16] E. Amig ´ o, J. Artiles, J. Gonzalo, D. Spina, B. Liu, and A. Corujo, “W eps-3 evaluation campaign: Overview of the online reputation man- agement task, ” in CLEF 2010 (Notebook P apers/LABs/W orkshops) , 2010. [17] D. Chen and W . Dolan, “Collecting highly parallel data for paraphrase ev aluation, ” in Pr oceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language T echnologies . Portland, Oregon, USA: Association for Computational Linguistics, June 2011, pp. 190–200. [Online]. A vailable: http: //www .aclweb .or g/anthology/P11- 1020 [18] M. Bloodgood and B. Strauss, “Translation memory retrieval methods, ” in Pr oceedings of the 14th Conference of the Eur opean Chapter of the Association for Computational Linguistics . Gothenbur g, Sweden: Association for Computational Linguistics, April 2014, pp. 202–210. [Online]. A vailable: http://www .aclweb .or g/anthology/E14- 1022 [19] G. A. Miller , R. Beckwith, C. Fellbaum, D. Gross, and K. J. Miller , “Introduction to wordnet: An on-line lexical database*, ” International Journal of Lexicography , vol. 3, no. 4, pp. 235–244, 1990. [20] G. A. Miller, “W ordnet: a lexical database for english, ” Communications of the ACM , vol. 38, no. 11, pp. 39–41, 1995. [21] C. Fellbaum, W ordNet: An Electr onic Lexical Database . MIT Press, 1998.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment