Building End-To-End Dialogue Systems Using Generative Hierarchical Neural Network Models
We investigate the task of building open domain, conversational dialogue systems based on large dialogue corpora using generative models. Generative models produce system responses that are autonomously generated word-by-word, opening up the possibility for realistic, flexible interactions. In support of this goal, we extend the recently proposed hierarchical recurrent encoder-decoder neural network to the dialogue domain, and demonstrate that this model is competitive with state-of-the-art neural language models and back-off n-gram models. We investigate the limitations of this and similar approaches, and show how its performance can be improved by bootstrapping the learning from a larger question-answer pair corpus and from pretrained word embeddings.
💡 Research Summary
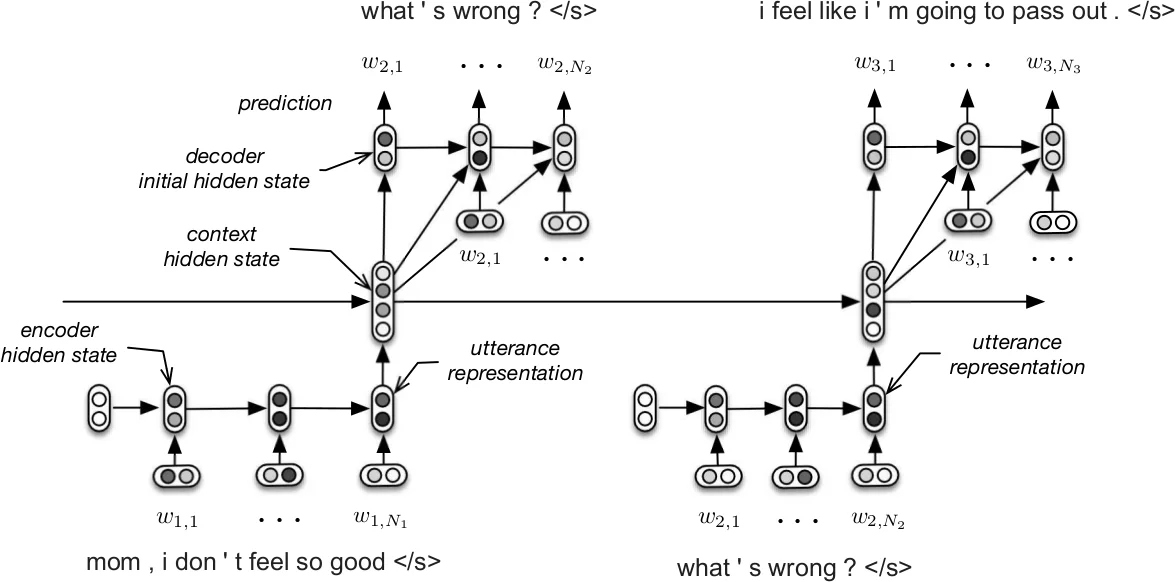
The paper tackles the problem of building open‑domain conversational agents that generate responses word‑by‑word, using large corpora of human‑human dialogues. The authors adopt the Hierarchical Recurrent Encoder‑Decoder (HRED) architecture, originally proposed for web query suggestion, and adapt it to dialogue modeling. In HRED, each utterance is first encoded by a word‑level recurrent neural network (GRU) into a fixed‑size vector; a second recurrent network (the context RNN) processes the sequence of utterance vectors, thereby maintaining a continuous representation of the dialogue state. The decoder GRU then generates the next utterance conditioned on the current context state, producing one token at a time. This hierarchical design allows the model to capture long‑range dependencies across turns while keeping the training objective tractable.
To address the specific challenges of dialogue—longer utterances, richer syntax, and the need for richer semantic knowledge—the authors introduce two major extensions. First, they replace the unidirectional encoder with a bidirectional GRU (HRED‑Bidirectional). By concatenating the final forward and backward hidden states (or applying L2 pooling), the utterance representation incorporates information from both the beginning and the end of the utterance, which is crucial for movie‑script style dialogues that can be lengthy and complex. Second, they employ a two‑stage bootstrapping strategy. Word embeddings are initialized with publicly available Word2Vec vectors trained on the Google News corpus (≈100 billion tokens), providing high‑quality semantic priors. Moreover, the entire HRED model is pretrained on a large question‑answer (Q‑A) corpus derived from movie subtitles (the SubTle dataset, ≈5.5 M Q‑A pairs). Each Q‑A pair is treated as a two‑turn dialogue, allowing the model to learn generic question‑answer dynamics and to acquire a good parameter initialization before fine‑tuning on the target dialogue data.
The experimental evaluation uses the newly constructed MovieTriples dataset, an expansion of the Movie‑DiC corpus. After preprocessing (lowercasing, replacing rare words with
Results show that the hierarchical structure already outperforms the flat RNN and the n‑gram model, achieving lower perplexity and better human ratings. Adding bidirectional encoding yields further improvements, confirming that richer utterance representations matter. Pretraining word embeddings reduces perplexity by about 12 % relative to random initialization. The most significant gain comes from the Q‑A pretraining: the full HRED‑Bidirectional model with both Word2Vec initialization and Q‑A pretraining attains the lowest perplexity (≈30) and the highest human evaluation scores, indicating more context‑aware and fluent responses.
The authors acknowledge several limitations. Generated replies tend to be safe and generic, reflecting the difficulty of controlling dialogue intent without explicit goal signals. The model’s large number of parameters (several million) makes training computationally expensive, and evaluation relies heavily on perplexity and limited human studies, which may not fully capture real‑world conversational quality. They propose future work in three directions: (1) integrating reinforcement learning to optimize task‑specific rewards and guide response generation; (2) incorporating dialogue act or intent annotations in a multi‑task setting to improve controllability; (3) extending the approach to other domains (customer support, medical advice) and exploring transformer‑based alternatives that could further benefit from massive pretraining.
In conclusion, the paper demonstrates that a hierarchical generative neural network, enriched with bidirectional utterance encoding and large‑scale pretraining on both word embeddings and Q‑A pairs, can learn effective open‑domain dialogue models from relatively modest dialogue corpora. This work bridges the gap between purely statistical language models and end‑to‑end conversational agents, showing that with appropriate architectural choices and bootstrapping strategies, neural dialogue systems can achieve competitive performance without hand‑crafted state or action representations.
Comments & Academic Discussion
Loading comments...
Leave a Comment