Mental Lexicon Growth Modelling Reveals the Multiplexity of the English Language
In this work we extend previous analyses of linguistic networks by adopting a multi-layer network framework for modelling the human mental lexicon, i.e. an abstract mental repository where words and concepts are stored together with their linguistic patterns. Across a three-layer linguistic multiplex, we model English words as nodes and connect them according to (i) phonological similarities, (ii) synonym relationships and (iii) free word associations. Our main aim is to exploit this multi-layered structure to explore the influence of phonological and semantic relationships on lexicon assembly over time. We propose a model of lexicon growth which is driven by the phonological layer: words are suggested according to different orderings of insertion (e.g. shorter word length, highest frequency, semantic multiplex features) and accepted or rejected subject to constraints. We then measure times of network assembly and compare these to empirical data about the age of acquisition of words. In agreement with empirical studies in psycholinguistics, our results provide quantitative evidence for the hypothesis that word acquisition is driven by features at multiple levels of organisation within language.
💡 Research Summary
The paper presents a novel approach to modeling the human mental lexicon (HML) by constructing a three‑layer multiplex network that captures phonological, synonym, and free‑association relationships among English words. Using a curated set of 4,731 commonly used English words drawn from WordNet 3.0, the Edinburgh Associative Thesaurus, and the OpenSubtitles corpus, the authors build three undirected, unweighted layers: (i) a phonological network (PN) where edges connect words differing by a single phoneme insertion, deletion, or substitution; (ii) a synonym network derived from WordNet; and (iii) a free‑association network based on human association norms. Basic network diagnostics (degree distributions, clustering coefficients, average shortest‑path lengths, assortativity, giant component sizes) confirm that each layer exhibits small‑world characteristics, with the phonological layer showing a sharp degree cutoff around k≈30 and high assortativity reflecting constraints of the phoneme embedding space.
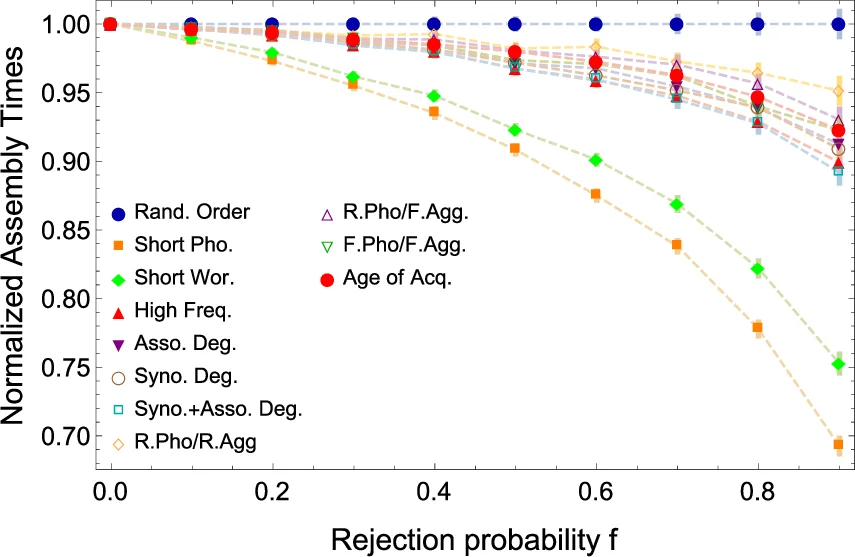
The core contribution is a growth model that simulates the incremental acquisition of words. At each discrete time step a candidate word is drawn from a list of not‑yet‑included words according to a specific ordering rule. The candidate is then examined for phonological similarity to any word already present in the multiplex; if at least one phonological edge would be created, the word is accepted, otherwise it is rejected with probability f (the sole free parameter) and returned to the candidate pool. The process repeats until all 4,731 words have been incorporated, and the average assembly time T (the number of steps required) is recorded.
The authors explore several ordering strategies: (1) random order (baseline), (2) shortest phonological length first, (3) shortest orthographic length first, (4) descending word frequency (derived from the OpenSubtitles counts), and (5) composite multiplex centrality measures (e.g., summed degree across layers, multiplex PageRank). By varying the rejection probability f and measuring T for each strategy, they assess how lexical features influence the speed of network formation.
Results show that ordering by phonological or orthographic shortness dramatically reduces T compared to random ordering, supporting the psycholinguistic observation that early language acquisition favors short, easily articulated forms. Frequency‑based ordering yields intermediate performance, while the multiplex‑centrality ordering achieves the fastest assembly when the centrality metric captures both phonological connectivity and semantic richness. The authors also compare the simulated assembly times with empirical age‑of‑acquisition (AoA) data from a large psycholinguistic database (reference
Comments & Academic Discussion
Loading comments...
Leave a Comment