Fisher, Neyman-Pearson or NHST? A Tutorial for Teaching Data Testing
Despite frequent calls for the overhaul of null hypothesis significance testing (NHST), this controversial procedure remains ubiquitous in behavioral, social and biomedical teaching and research. Little change seems possible once the procedure becomes well ingrained in the minds and current practice of researchers; thus, the optimal opportunity for such change is at the time the procedure is taught, be this at undergraduate or at postgraduate levels. This paper presents a tutorial for the teaching of data testing procedures, often referred to as hypothesis testing theories. The first procedure introduced is the approach to data testing followed by Fisher (tests of significance); the second is the approach followed by Neyman and Pearson (tests of acceptance); the final procedure is the incongruent combination of the previous two theories into the current approach (NSHT). For those researchers sticking with the latter, two compromise solutions on how to improve NHST conclude the tutorial.
💡 Research Summary
The paper tackles the persistent dominance of null hypothesis significance testing (NHST) in behavioral, social, and biomedical research, arguing that the most effective point of reform is during education. It structures the tutorial around three distinct statistical testing philosophies. First, Fisher’s significance testing is presented as a post‑hoc procedure that quantifies how unlikely the observed data are under a null hypothesis, using the p‑value as a measure of surprise without requiring a pre‑specified alternative hypothesis. The authors emphasize that Fisher’s approach is exploratory, suited for hypothesis generation, but lacks pre‑planned control of Type I and Type II error rates.
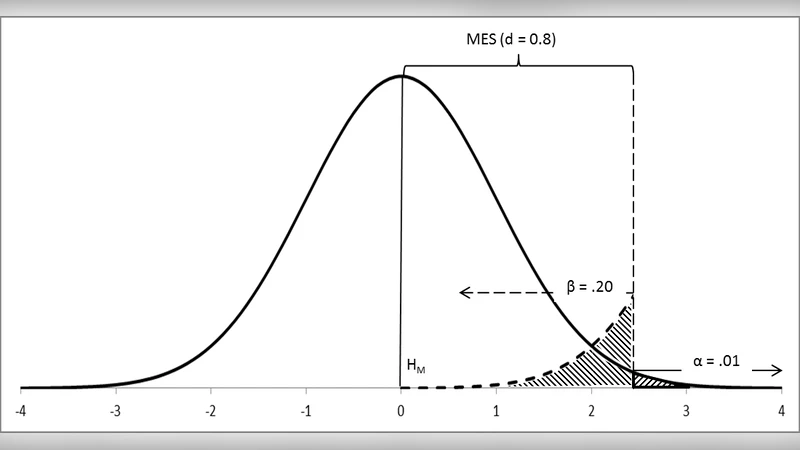
Second, the Neyman‑Pearson framework is described as a decision‑theoretic, pre‑experimental system. Here the null and alternative hypotheses are explicitly defined, α (Type I error) and β (Type II error) are set in advance, and power (1‑β) is maximized through sample‑size planning and effect‑size specification. Outcomes are binary—accept or reject—making the method appropriate for confirmatory research and policy decisions where error control is paramount.
Third, the authors expose how contemporary NHST conflates these two incompatible traditions. In practice, researchers treat a p‑value below .05 as a definitive sign of “statistical significance” while simultaneously ignoring the pre‑experimental error‑rate discipline of Neyman‑Pearson. This hybrid creates conceptual confusion, fuels p‑hacking, and undermines reproducibility.
To remedy the educational gap, the paper proposes a three‑stage teaching strategy. (1) Teach Fisher and Neyman‑Pearson as separate, historically grounded theories. (2) Use real‑world case studies to illustrate the appropriate contexts and limitations of each. (3) When NHST must be retained, integrate a “two‑step” or Bayesian augmentation: conduct a priori power analysis, then report p‑values together with effect sizes and confidence intervals. This dual reporting forces students to appreciate both the evidential weight of the data (Fisher) and the pre‑specified error constraints (Neyman‑Pearson).
Recognizing that a wholesale abandonment of NHST is unrealistic, the authors suggest two pragmatic improvements. First, mandate the simultaneous presentation of p‑values, effect sizes, and 95 % confidence intervals to convey practical significance alongside statistical significance. Second, require explicit specification of α and β at the design stage, making power analysis a compulsory component of any study. These steps aim to reduce the ambiguity of NHST, increase transparency, and promote more reliable inference.
Overall, the tutorial argues that “education is the lever for change.” By clearly distinguishing the three testing paradigms, exposing the logical inconsistency of current NHST, and offering concrete pedagogical and procedural reforms, the paper provides a roadmap for instructors and researchers to foster a more nuanced, accurate, and reproducible culture of statistical testing.
Comments & Academic Discussion
Loading comments...
Leave a Comment