Distributed Phasers
A phaser is an expressive synchronization construct that unifies collective and point-to-point coordination with dynamic task parallelism. Each task can participate in a phaser as a signaler, a waiter, or both. The participants in a phaser may change over time as dynamic tasks are added and deleted. In this poster, we present a highly concurrent and scalable design of phasers for a distributed memory environment that is suitable for use with asynchronous partitioned global address space programming models. Our design for a distributed phaser employs a pair of skip lists augmented with the ability to collect and propagate synchronization signals. To enable a high degree of concurrency, addition and deletion of participant tasks are performed in two phases: a “fast single-link-modify” step followed by multiple hand-overhand “lazy multi-link-modify” steps. We show that the cost of synchronization and structural operations on a distributed phaser scales logarithmically, even in the presence of concurrent structural modifications. To verify the correctness of our design for distributed phasers, we employ the SPIN model checker. To address this issue of state space explosion, we describe how we decompose the state space to separately verify correct handling for different kinds of messages, which enables complete model checking of our phaser design.
💡 Research Summary
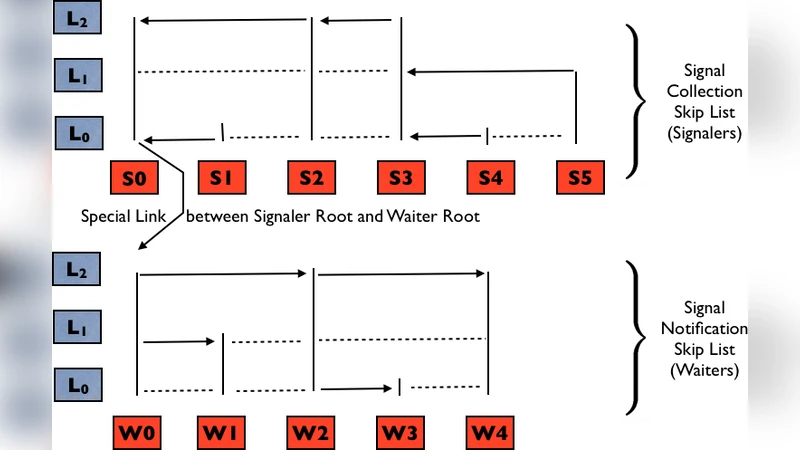
The paper presents a novel design for phasers—high‑level synchronization primitives that support collective and point‑to‑point coordination with dynamic task parallelism—in distributed memory environments, targeting asynchronous partitioned global address space (APGAS) programming models. Traditional phaser implementations have been limited to shared‑memory systems; this work extends the concept to distributed settings by employing two augmented skip lists per phaser: a Signal Collection Skip List (SCSL) that aggregates signals from all signaler tasks to a designated head‑signaler, and a Signal Notification Skip List (SNSL) that disseminates the aggregated signal from a head‑waiter to all waiter tasks. The skip lists are enriched with additional “signaling edges” that direct the flow of synchronization information, while preserving the probabilistic logarithmic height property of classic skip lists.
Phaser creation uses a log n‑based recursive doubling algorithm (Egecioglu et al., 1989) to build the initial SCSL, where each task exchanges information with hypercube neighbors over log n rounds. Dynamic participant management is split into two phases to maximize concurrency. For addition, an “eager insertion” step quickly inserts the newly async‑spawned task into the lowest level of the SCSL using a standard skip‑list search (O(log n)) and a constant number of link‑update messages. A subsequent “lazy promotion” phase incrementally lifts the node to its final probabilistic height through a series of hand‑over operations between neighboring stable nodes; the expected cost of this phase is O(p^{1‑p}·log(C^{p‑1‑p})), where p is the level‑promotion probability and C is the number of nodes being promoted concurrently. Deletion mirrors this approach: each level removal requires a constant number of messages, and because a node spans O(log n) levels, the overall deletion cost is also O(log n).
The authors provide a detailed complexity analysis showing that both synchronization (signal aggregation) and structural modifications (addition/deletion) scale logarithmically with the number of participants, even under concurrent modifications. This sub‑linear scaling is crucial for exascale‑level applications where the participant set can change rapidly.
To ensure correctness, the design is formally verified using the SPIN model checker. Direct verification of the full distributed phaser would suffer from state‑space explosion; therefore, the authors decompose the verification problem by message type, creating separate PROMELA models for eager insertion, lazy promotion, and deletion. Linear Temporal Logic (LTL) specifications encode safety properties such as “every signal from a signaler eventually reaches the head‑signaler” and “no waiter proceeds before all required signals have been collected.” This decomposition reduces memory consumption dramatically, enabling exhaustive exploration of billions of states on a 32‑core, 256 GB RAM machine. Table 1 reports resource usage for each message‑type verification run, demonstrating feasibility.
In summary, the paper delivers a scalable, highly concurrent distributed phaser implementation with provable logarithmic bounds on synchronization and structural operations, and validates its correctness through exhaustive model checking. The work bridges a critical gap between dynamic task parallelism and distributed memory systems, offering a practical synchronization mechanism for future exascale and large‑scale heterogeneous computing platforms.
Comments & Academic Discussion
Loading comments...
Leave a Comment