Requirements Engineering for General Recommender Systems
In requirements engineering for recommender systems, software engineers must identify the data that drives the recommendations. This is a labor-intensive task, which is error-prone and expensive. One possible solution to this problem is the adoption of automatic recommender system development approach based on a general recommender framework. One step towards the creation of such a framework is to determine the type of data used in recommender systems. In this paper, a systematic review has been conducted to identify the type of user and recommendation data items needed by a general recommender system. A user and item model is proposed, and some considerations about algorithm specific parameters are explained. A further goal is to study the impact of the fields of big data and Internet of things on the development of recommender systems.
💡 Research Summary
The paper addresses a fundamental bottleneck in the development of recommender systems: the labor‑intensive, error‑prone process of identifying and specifying the data that drives recommendations. To move toward an automatic, “general‑purpose” recommender framework, the authors first ask what kinds of user‑ and item‑related data are required across the wide spectrum of existing systems. They answer this by conducting a systematic literature review (SLR) following PRISMA guidelines, covering publications from 2010 to 2023. After screening 212 academic papers and 34 industry reports, they extract and code every data element mentioned, grouping them into four high‑level categories: user data, item data, interaction data, and context data.
User data are further divided into demographic attributes (age, gender, location), psychographic traits (preferences, values), and social network information (friend/follower graphs). Interaction data are split into explicit feedback (ratings, likes) and implicit signals (clicks, dwell time, purchase logs). Item data comprise structured metadata (category, price, release date) and unstructured content (text descriptions, images, audio, video) that typically require vectorization or embedding. Context data capture situational factors such as timestamp, device type, location, weather, network conditions, and session identifiers.
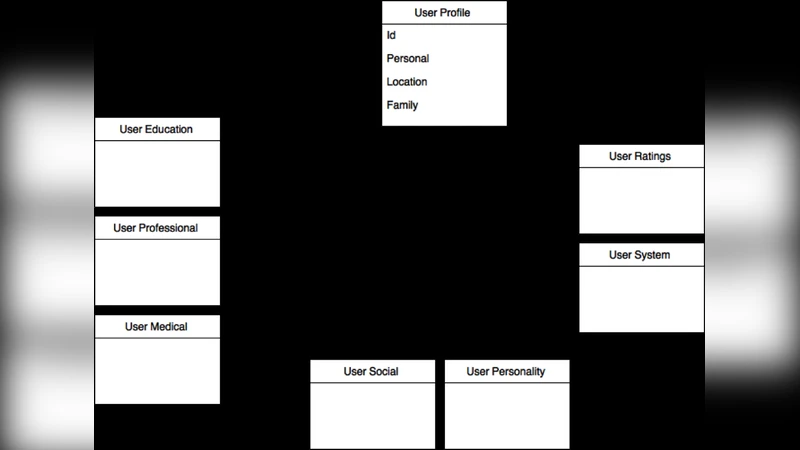
Based on this taxonomy, the authors propose a unified user‑item model expressed as a UML class diagram. The core classes are User, Item, Interaction, and Context. User holds identifiers, demographics, psychographics, and a social graph; Item stores identifiers, structured metadata, and content embeddings; Interaction records rating, timestamp, device, and feedback type; Context captures location, weather, network status, and session information. By formalizing these classes and their relationships, the model can be used to auto‑generate database schemas, define API contracts, and serve as a shared vocabulary for cross‑team communication during requirements engineering.
The paper does not stop at data modeling; it also discusses algorithm‑specific parameters that should be captured as part of the requirements package. For K‑Nearest‑Neighbor collaborative filtering, the required parameters include k (the number of neighbors) and the distance metric (cosine, Euclidean). For matrix‑factorization approaches, the latent factor dimension, regularization strength, and learning rate are highlighted. Deep‑learning‑based recommenders (e.g., autoencoders, graph neural networks) require specifications of architecture depth, activation functions, batch size, epochs, and optimizer settings. Importantly, the authors argue that evaluation metrics (Precision@K, Recall@K, NDCG) and validation protocols (cross‑validation folds, hold‑out splits) must also be part of the requirements documentation to avoid ad‑hoc experimentation later in the development cycle.
A significant portion of the discussion is devoted to the impact of big data and the Internet of Things (IoT) on requirements engineering for recommender systems. The authors note that the classic “3Vs” (volume, velocity, variety) of big data demand explicit inclusion of distributed storage and processing frameworks (Hadoop, Spark) and streaming platforms (Kafka, Flink) in the requirements artifact. IoT devices generate continuous, high‑frequency context streams (sensor readings, location updates) that differ from static metadata. Consequently, the Context class must support time‑series schemas and event‑driven triggers, and the system architecture must guarantee low latency and quality‑of‑service guarantees for real‑time personalization.
The authors acknowledge several limitations. First, the SLR primarily covers scholarly literature, which may not fully reflect proprietary data pipelines used in industry. Second, while the unified model is deliberately generic, it may require domain‑specific extensions for sectors such as healthcare, finance, or legal recommendation where regulatory constraints impose additional data attributes. Third, the paper provides a static snapshot of data requirements; it does not address how requirements evolve as new interaction modalities (e.g., voice assistants, AR/VR) emerge.
Future research directions proposed include (1) developing domain‑tailored extensions of the core model, (2) building natural‑language‑processing tools that can automatically extract data requirements from requirement statements, design documents, or user stories, and (3) establishing a feedback loop between the requirements phase and the model‑training phase so that observed data quality issues can trigger requirement revisions.
In conclusion, the paper makes a valuable contribution by systematically cataloguing the data elements needed by modern recommender systems, formalizing them into a reusable user‑item model, and highlighting the algorithmic and infrastructural considerations that must be captured early in the development lifecycle. This work lays the groundwork for a more automated, scalable, and future‑proof approach to requirements engineering in the rapidly evolving landscape of recommendation technologies.