Interactive Storytelling over Document Collections
Storytelling algorithms aim to 'connect the dots' between disparate documents by linking starting and ending documents through a series of intermediate documents. Existing storytelling algorithms are based on notions of coherence and connectivity, an…
Authors: Dipayan Maiti, Mohammad Raihanul Islam, Scotl
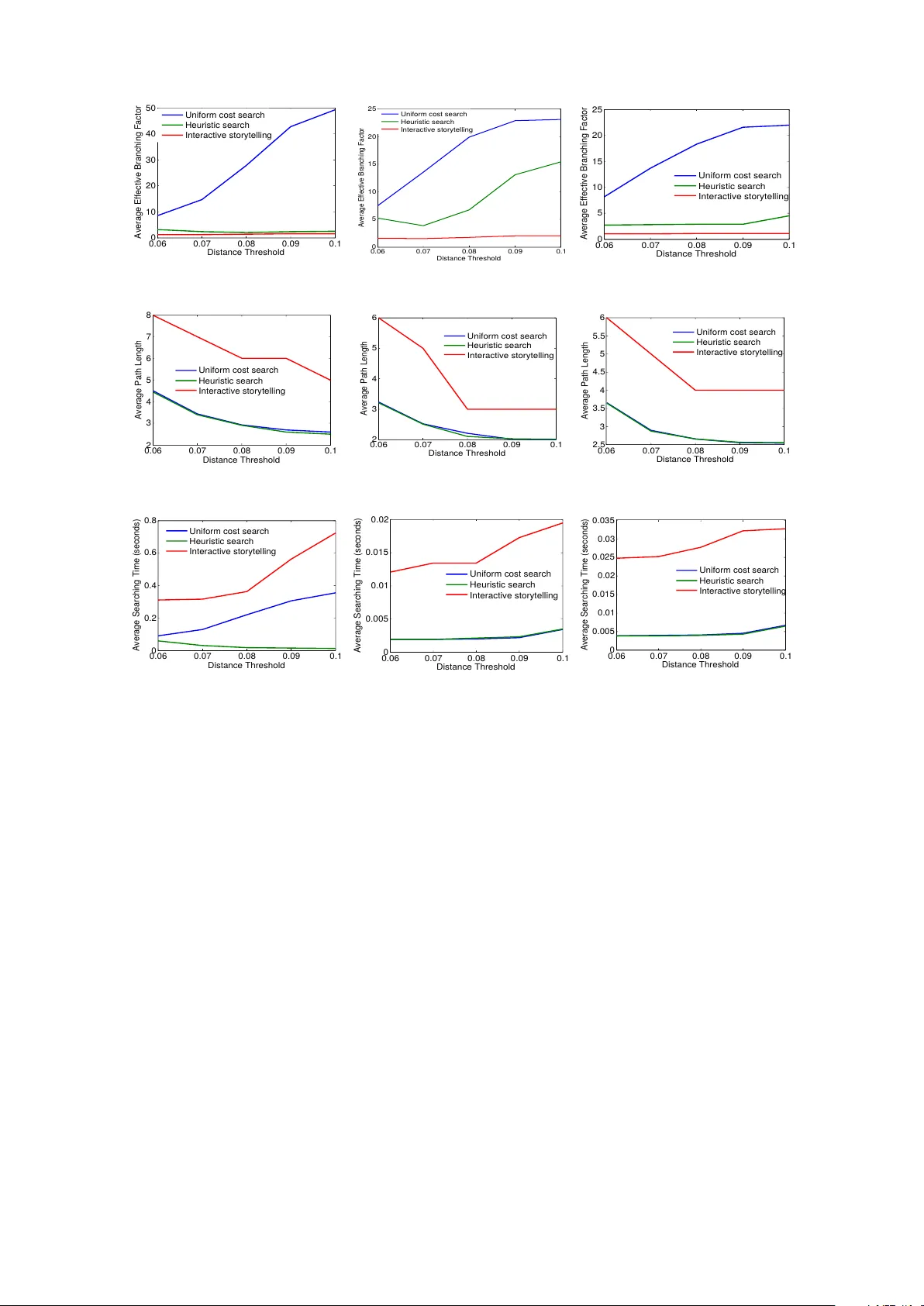
In teractiv e Storytelling o v er Do cumen t Collections Dipa yan Maiti ∗ 1,3 , Mohammad Raihan ul Islam † 2,3 , Scotland Leman ‡ 1,3 and Naren Ramakrishnan § 2,3 1 Departmen t of Statistics, Virginia T ec h, V A, USA 2 Departmen t of Computer Science, Virginia T ec h, V A, USA 3 Virginia T ech, Disco very Analytics Center, Arlington, V A 22203 Abstract Storytelling algorithms aim to ‘connect the dots’ b et w een disparate do cumen ts by linking starting and ending do cumen ts through a series of intermediate documents. Existing storytelling algorithms are based on notions of coherence and connectivit y , and th us the primary wa y b y which users can steer the story construction is via design of suitable similarity functions. W e present an alternativ e approach to storytelling wherein the user can interactiv ely and iteratively pro vide ‘m ust use’ constraints to preferen tially supp ort the construction of some stories ov er others. The three inno v ations in our approach are distance measures based on (inferred) topic distributions, the use of constraints to define sets of linear inequalities o ver paths, and the introduction of slack and surplus v ariables to condition the topic distribution to preferentially emphasize desired terms o ver others. W e describ e exp erimen tal results to illustrate the effectiv eness of our interactiv e storytelling approach ov er multiple text datasets. 1 In tro duction F aced with a constan t deluge of unstructured (text) data and an ev er increasing sophistication of our information needs, a significan t research fron t has op ened up in the space of what has b een referred to as information c arto gr aphy [31]. The basic ob jective of this space is to pictorially help users make sense of information through inference of visual constructs suc h as stories [13, 17, 27, 28], threads [9, 10, 23], and maps [29, 30]. By supp orting in teractions o ver such constructs, information cartograph y systems aim to go b eyond traditional information retriev al systems in supp orting users’ information exploration needs. Arguably the k ey concept underlying suc h cartography is the notion of storytelling, which aims to ‘connect the dots’ b etw een disparate do cumen ts b y linking starting and ending do cumen ts through a series of interme- diate do cumen ts. There are tw o broad classes of storytelling algorithms, motiv ated by their different lineages. Algorithms fo cused on news articles [27, 28] aim for c oher enc e of stories wherein every do cumen t in the story shares an underlying common theme. Algorithms focused in domains suc h as intelligence analysis [12] and bioin- formatics [14] must often work with sparse information wherein a common theme is typically absent or at b est ten uous. Suc h algorithms m ust leverage weak links to bridge diverse clusters of do cumen ts, and thus emphasize the construction and trav ersal of similarit y netw orks. Irresp ectiv e of the motiv ations b ehind storytelling, all suc h algorithms provide limited abilities for the user to steer the story construction pro cess. There is t ypically no mec hanism to interactiv ely steer the story construction to ward desired story lines and av oid sp ecific asp ects that are not of interest. In this pap er, w e present an alternative approach to storytelling wherein the user can interactiv ely provide ‘m ust use’ constrain ts to preferen tially support the construction of some stories o v er others. At eac h stage of our approac h, the user can insp ect the giv en story and the ov erall do cumen t collection, and express preferences to adjust the storyline, either in part or in ov erall. Suc h feedback is then incorp orated into the story construction iterativ ely . Our key contributions are: 1. Our in teractive storytelling approac h can b e viewed as a form of ‘visual to parametric interaction’ (V2PI [18]) wherein users’ natural interactions with do cumen ts in a w orkspace is translated into parameter- lev el interactions in terms of the underlying machine learning mo dels (here, topic mo dels). In particular, ∗ dipay an@vt.edu † raihan8@cs.vt.edu ‡ leman@vt.edu § naren@cs.vt.edu 1 w e demonstrate how high-lev el user feedback at the lev el of paths is translated do wn to redefine topic distributions. 2. The underlying mathematical framew ork for interactiv e storytelling is a no vel combination of hitherto uncom bined comp onents: distance measures based on (inferred) topic distributions, the use of constrain ts to define sets of linear inequalities ov er paths, and the introduction of slac k and surplus v ariables to condition the topic distribution to preferentially emphasize desired terms ov er others. The proposed framew ork th us brings together notions from heuristic search, linear systems of inequalities, and topic mo dels. 3. W e illustrate how just a mo dicum of user feedback can b e fruitfully employ ed to redefine topic distribu- tions and at the same time sev erely curtail the searc h pro cess in navigating large do cument collections. Through exp erimen tal studies, w e demonstrate the effectiv eness of our in teractive storytelling approach o ver multiple text datasets. 2 Motiv ating Example W e present an illustrative example of how a storytelling algorithm can b e steered tow ard desired lines of analysis based on user input. F or our purp oses, assume a v anilla storytelling algorithm (akin to [15, 17]) based on heuristic search to prioritize the exploration of adjacent do cumen ts in order to reac h a desired destination do cumen t. Adjacency here can b e assessed in many wa ys. One approac h is to use lo cal representations suc h as a tf-idf representation and define similarity measures (e.g., Jaccard co efficient) ov er such lo cal represen tations. A second approach is to utilize the normalized topic distribution generated using, e.g., LD A [5], to induce a distance b et ween every pair of do cumen ts. Let us construct a toy corpus of 50 do cumen ts wherein the terms are drawn from 9 predefined themes and some random noise terms. Each theme is assumed to b e represented by a collection of 4 terms. An example of a theme is: Theme 1 : nation, terror, a vert, orange Eac h do cumen t is generated by a single theme or b y mixing tw o themes. In addition to the terms sampled from the themes, each do cumen t is assumed to also con tain 2 noise terms. (The noise terms are do cumen t-sp ecific meaning tw o do cumen ts do not share the same terms.) Thus, we obtain 4 terms for each of the 9 themes and 2 noise terms for each of the 50 do cumen ts, so that the total num b er of terms is 9 × 4 + 50 × 2 = 136. A pair of do cuments has an edge betw een them if they ha v e at least one common term. (Since noise terms are not common b et ween the do cumen ts, they are not resp onsible for edge formation.) W e use the notation d n ( p · · · q ) to denote a do cumen t. Here n denotes the do cumen t index and p, q are the tw o themes represented by the do cumen t. F or example d 1 (5 · · · 6) is the first do cumen t in the corpus and contains terms from themes 5 and 6. No w consider the storytelling scenario from Fig. 1. The user desires to mak e a story from document d 43 (5 · · · 7) to do cumen t d 23 (1 · · · 3). d 43 (5 · · · 7) describ es a bank robb ery and d 23 (1 · · · 3) mentions a p ossible c hemical attac k. The constructed story is as follows: d 43 (5 · · · 7) → d 27 (1 · · · 7) → d 23 (1 · · · 3) using heuristic searc h (Fig. 1 (a)). The first tw o do cumen ts are connected using ( Theme 7 ), inv olving the terms bank, red, truc k, aspen . As can b e seen this story is not desirable since the algorithm has conflated a bank robbery in Asp en using a red truck with the bankruptcy of the Red T rucking compan y (due to insufficient orange pro duction in Asp en). Thus although the connection b et ween tw o do cumen ts are established by the same set of terms, the contexts are very different. In this case the user realizes that the story do es not make very goo d sense, and thus uses her domain knowl- edge to steer the story in the right direction. She aims to incorp orate a story segmen t < d 4 (5 · · · 8) , d 22 (1 · · · 8) > in to the construction. Here, d 4 (5 · · · 8) rep orts the closing of a chemical factory and d 22 (1 · · · 8) mentions ab out a sweet o dor emanating from an abandoned chemical factory (see Fig. 1 (b)). The user believes that these t wo do cumen ts could play an imp ortan t role in the final story . Incorp orating this feedback, a story from d 43 to d 23 could p oten tially be d 43 (5 · · · 7) → d 4 (5 · · · 8) → d 22 (1 · · · 8) → d 23 (1 · · · 3) (i.e., the shortest path from d 43 (5 · · · 7) to d 23 (1 · · · 3) via d 4 (5 · · · 8) and d 22 (1 · · · 8)). Note that there could b e other do cumen ts necessary to b e included in the path that are not explicitly provided in the user’s feedback. Incorp orating this feedback, the algorithm introduced in this pap er will infer new topic definitions ov er the dictionary of terms, and subsequently new topic distributions for each do cumen t. In this case, a new story is generated: d 43 (5 · · · 7) → d 4 (5 · · · 8) → d 22 (1 · · · 8) → d 23 (1 · · · 3). In this story (see Fig. 1 (c)), the first t wo do cumen ts are connected b y the terms ski, tourist, destination, win ter ( Theme 5 ); the second and the third are linked via the terms c hemical, factory , recently , hiring ( Theme 8 ) and the last tw o do cumen ts are connected by nation, terror, a v ert, orange ( Theme 1 ). This story thus suggests an alternative hypothesis for the user’s scenario. After incorp orating the user’s feedbac k using our proposed algorithm, w e see that ski, tourist, destination, win ter has some mass for do cumen t d 22 (1 · · · 8) so that it is inferred closer to do cumen t d 4 (5 · · · 8) (see Fig. 2). 2 doc 43 doc 27 doc 23 Red trucking Co. of Aspen could not av ert bank ruptcy with Naon wide. This further terror iz ed farmer s aer a weak or ange season (...) A bank robbery was r eported in the town of Aspen . The r obbers fled the scene of robbery in a red truck . Aspen is a popular ski desnaon f or tourists during the win ter months (...) The terror alert has been r aised to orang e level naon wide to a possible chemical a ack. Cizens are r equested to inf orm local authories about any abondoned material eman ng sweet odor as they might be haz ardous (...) s t (a) doc 4 A bank robbery w as report ed in the town of Aspen . The robber s fled the scene of robbery in a red truck . Aspen is a popular ski desnaon for t ourists during the wint er months (...) The terr or alert has been raised to or ange level naon wide t o a possible chemical a ack. Cizens are r equested to in form local authories about any abondoned material eman ng sweet odor as they might be haz ardous (...) A local chemical f actory r ecently closed down and retr acted its open hiring posions. It is locat ed in the outskirts of Aspen, a popular ski desnaon f or touris ts in winter . Locals report ed a sweet odor fr om an abondoned chemical f actory . Authories inv esga ted the report but f ound no hazar dous substance in the pr emises. The fact ory recently re tracted its open hiring posions and has since been abandoned. doc 22 s t doc 43 doc 23 (b) A bank robbery w as report ed in the town of Aspen . The robber s fled the scene of robbery in a red truck . Aspen is a popular ski desnaon for t ourists during the wint er months (...) The terr or alert has been raised to orang e level naon wide t o a possible chemical a ack. Cizens ar e requested to inf orm local authories about any abondoned mat erial emanng sweet odor as they might be haz ardous (...) A local chemical f actory r ecently closed down and retr acted its open hiring posions. It is locat ed in the outskirts of Aspen, a popular ski desnaon for t ourists in winter . Locals report ed a sweet odor fr om an abondoned chemical fact ory . Authories inv esga ted the report but f ound no hazar dous substance in the pr emises. The fact ory recently re tracted its open hiring posions and has since been abandoned. s t doc 4 doc 22 doc 43 doc 23 (c) Figure 1: An illustration of the interactiv e storytelling algorithm. Similarly , the algorithm estimates p ositiv e probabilities for the terms chemical, factory , recently , hiring in do cumen t d 23 (1 · · · 3) which brings it closer to do cumen t d 22 (1 · · · 8). 3 Figure 2: Probability of weigh ts of terms b efore (green) and after (blue) feedback. The inferred topic distribu- tions are shifted to induce proximit y b et ween do cumen ts so that the story is consistent with user feedback. 3 F ramew ork A summary of notation as used in this pap er is given in T able 1. W e utilize the terms no des and do cuments in terchangeably in this pap er. As describ ed earlier, we impute the notion of distance b et ween do cumen ts based on v ector represen tations inferred from probabilistic topic mo dels (here, LDA). Sp ecifically , we use the topic distributions θ ( d i ) and θ ( d j ) for do cumen ts d i and d j (resp.) to calculate the distance or edge cost b et w een d i and d j . W e p osit an edge betw een tw o do cuments if they share an y terms and the edge cost is low er than a fixed cost ξ . While a num b er of probabilistic measure of distance can b e utilized, in this pap er w e adopt the Manhattan distance metric. The heuristic distance for a node m is given by the straigh t line distance to the ending (target) do cumen t t . Since the Manhattan distance ob eys the triangle inequality , it is w ell known that it is an admissble heuristic for A* search. As is customary , we define a no de ev aluation function f S core ( l ) as the sum of g S cor e ( l ) and hS cor e ( l ). 3.1 Obtaining User F eedback After an initial story generated by heuristic searc h, the user provides a sequence of do cumen ts that ough t to b e included in the story (i.e., b et ween the do cuments s and t ). Suppose this sequence is C = < C 1 , · · · , C K > . The order of the do cumen ts is imp ortan t, since the sequence is a reflection of desired story progression. W e define the path P ∗ as a concatenation of the shortest path b et ween s and C 1 , follow ed by the no des in C , and finally the shortest path b et ween C K and t . This pro cess is done in the original LDA-inferred topic space. W e will no w undertake a constrained A ∗ searc h incorp orating the user feedback. 3.2 Constrained A ∗ searc h No w we discuss the incorp oration of the user’s feedback into the story . Consider the case where the user insists that a do cumen t C (not in the initial story) should b e included in the story . This case can b e easily extended to a sequence of do cumen ts C = < C 1 , · · · , C K > . Supp ose the adjacen t no des of a document d is denoted b y N ( d ). There are fiv e adjacen t no des to d in Fig. 3. The heuristic distance b et ween a neigh b or (say , D 2 ) and the ending do cumen t t is given b y h ( D 2 , t ) in the original A ∗ searc h. Our redefined heuristic distance for constrained A ∗ searc h is giv en by h ∗ ( D 2 , B ) = h ( D 2 , C ) + h ( C, B ). If the feedback is a sequence of do cumen ts C = < C 1 , · · · , C K > then h ∗ ( D 2 , t ) = h ( D 2 , C 1 ) + h ( C 1 , C 2 ) + · · · + h ( C K , t ). Ho wev er, while h ∗ ensures that the f S core of a do cumen t dep ends on the path via the sequence of feedback no des C , it must also consider the subset of C that already b elong to the shortest path from s to D to estimate the heuristic distance h ∗ ( D , t ). 4 T able 1: Notation ov erview. Notation Explanation d i i th do cumen t in the copus T total num b er of topics s starting do cumen t t ending/goal do cumen t ξ distance threshold θ ( d i ) = ( θ ( d i ) 1 , · · · , θ ( d 1 ) T ) T dimensional vector of normalized topic distribution of do cumen t d i e ij edge b et ween d i and d j if they hav e any term in common c ( e ij ) cost b et ween d i and d j , c ( e ij ) = c ij = P T t =1 ∆ ( ij ) t , where ∆ ( ij ) t = | θ d i t − θ d j t | P = < s, d P (1) , d P (2) , · · · , d L − 1 , t > path P from s to t with L edges, d P ( i ) is the i th do cumen t after s c ( P ) c ( P ) = P e ij ∈ P c ( e ij ) P ∗ shortest path from s to t d ( i, j ) cost of the shortest path from i to j g S core ( l ) cost of the shortest path from s to l using A ∗ searc h hS cor e ( m ) the heuristic distance (Manhattan distance) b etw een the no de m and the goal no de t α e ∗ minim um cost any e ∗ ∈ E − P ∗ is b ounded by such that P ∗ is the shortest path from s to t β e ∗ maxim um cost any e ∗ ∈ P ∗ is b ounded by such that P ∗ is the shortest path from s to t d e,k ( s, t ) cost of the shortest path from s to t with c ( e ) = k c e,k ( P ) cost of an arbitrary path P with c ( e ) = k d ( s, e, t ) cost of the shortest path from s to t including an edge e ∈ E s D D 1 D 2 D 5 D 4 D 3 t C (a) s D t C (b) s D t C 2 (c) h h 1 h 2 C 1 h 1 h 2 D 1 D 5 D 4 D 3 D 1 D 5 D 4 D 3 Figure 3: (a) shows the heuristic distance h ( D 2 , t ) from original A ∗ searc h. (b) depicts h ∗ ( D 2 , t ) based on constrained A ∗ searc h. (c) depicts h ∗ ( D 2 , t ) when feedback no des are C = < C 1 , C 2 > where ancestry of D is giv en by A ( D ) = C 1 . Dashed line sho ws the shortest path from s to D . W e define a prop ert y named Anc estry that k eeps track of the subset of the feedback no des that already exists in the shortest path from the s to the said no de. Ancestry A ( D i ) of an arbitrary neighbor of D is defined as A ( D i ) = A ( pr edecessor ( D )) if D is not a feedback no de. If D is the feedback no de immediately after the subsequence A ( pr edecessor ( D )) in C then A ( D i ) = { ( pr edecessor ( D )) , D } . The starting no de s has an empty ancestry . A no de having longer subsequence of C in its ancestry compared to another is said to hav e a richer ancestry . A no de with richer ancestry is alwa ys preferred. If ancestries are comparable, for an op en no de the predecessor with smaller g S cor e is chosen while for a closed node the predecessor with smaller f S cor e is chosen. 3.3 Alternate/Candidate Stories The no des explored by A ∗ searc h in the initial topic space (the set of op en and c losed no des) induce an acyclic graph G ( V , E ). The orange no des in Fig. 4 are op en no des in such a graph. Denote the set of op en no des by O . Any path from s to t via o ∈ O is a candidate story generated by A ∗ searc h. Let us denote the path via o b y P ( o ) . 5 s t s t Figure 4: (left) The path with green no des is the initial story generated b y the storytelling algrithm and hence the shortest path from s to t before incorp orating feedback. The gra y paths (dashed and solid) are alternate stories abandoned by the A ∗ searc h. (righ t) Story after user feedbac k where the user-preferred story P ∗ is sho wn in blue. This is not the shortest path in the current topic space. The do cumen ts that the user desires to b e in the story are shown in large circles. W e intend to estimate the topic space where the blue path ( P ∗ ) is shorter than all the other alternate paths from s to t . No w assume O has O op en no des. T o enforce the user feedback that P ∗ b e the shortest path o ver all paths from s to t we define the following system of inequalities: c ( P ∗ ) ≤ c ( P ( o 1 ) ) . . . c ( P ∗ ) ≤ c ( P ( o O ) ) (1) If we break each inequality in terms of topics then we obtain: T X t =1 (∆ ∗ t − ∆ ( o 1 ) ) ≤ 0 . . . T X t =1 (∆ ∗ t − ∆ ( o O ) ) ≤ 0 (2) In addition to this set of inequalities, w e also add another set of inequalities imp osing that the cost of an edge in the new topic space, c ( e ) is at least as muc h as the cost of the edge in the initial topic space c 0 ( e ). c ( e ) ≥ c 0 ( e ) , e ∈ E (3) This constraint is imp osed so that the pro ximity of the do cumen t do es not change drastically , as otherwise this migh t disorient users. 3.4 Deriving Systems of Inequalities A ∗ is a heuristic algorithm to find the shortest path b et ween tw o no des. Given the shortest path, finding the edge costs or upp er and low er limits thereof is th us as inverse shortest p ath pr oblem . Our goal is to find a normalized topic distribution θ ( d i ) so that P ∗ is actually the shortest path in the new topic space. In our approac h, w e obtain the inequalities in Eqn 2 by using the follo wing observ ation: if the cost of an edge e ∗ ∈ P ∗ crosses the upp er threshold β ∗ e or an edge e 6∈ P ∗ falls b elo w the low er threshold α e , all the other edge cost b eing fixed P ∗ is no longer the shortest path from s to t . Therefore the condition for P ∗ b eing the shortest path is c ( e ∗ ) ≤ β ∗ e , ∀ e ∗ ∈ P ∗ c ( e ) ≥ α e , ∀ e ∈ E − P ∗ (4) 6 s t i* c* e* Figure 5: Dashed line shows the s ubtree τ ( e ∗ ) and the solid line shows the subtree τ C ( e ∗ ). The candidate op en no des in τ C ( e ∗ ) for Eqn. 6 are shown in green. Red no des are op en no des in τ ( e ∗ ) and do not contribute in Eqn. 6. The shortest path from s to t av oiding e ∗ is the shortest path from s to t via any of the green no des. Upp er and low er shortest path tolerances are presented in [25] as: β e ∗ = d e ∗ , ∞ ( s, t ) − c ( P ∗ ) + c ( e ∗ ) α e = c ( P ∗ ) − d e, 0 ( s, t ) (5) Therefore the inequities for the edges b ecomes: c ( P ∗ ) ≤ d e ∗ , ∞ ( s, t ) , ∀ e ∗ ∈ P ∗ (6) c ( e ) ≥ c ( P ∗ ) − d e, 0 ( s, t ) , ∀ e ∈ E − P ∗ (7) Note that for the first equation in Eqn. 5, β e ∗ is the difference of tw o path costs: the cost of the shortest path from s to t that av oid e ∗ (imp osing an infinite cost for e ∗ ) d e ∗ , ∞ ( s, t ) and the minimum cost of P ∗ with e ∗ in the path (imp osing a zero cost for e ∗ ), so that c ( P ∗ ) − c ( e ∗ ) = c e ∗ , 0 ( P ∗ ). Notice also that if e = ( l, m ), then d e,o ( s, t ) = min( c ( P ∗ ) , d ( s, l ) + d ( m, t )). F or the second equation if the shortest path from s to t do es not c hange ev en with c ( e ) = 0, i.e. d e, 0 ( s, t ) = c ( P ∗ ), then the low er tolerance for c ( e ) is zero. Ho wev er, if the constrain t c ( e ) = 0 fav ors a different path through e (meaning not P ∗ ) the low er tolerance for e is given by the drop in the path cost which this alternate path allows o ver P ∗ . W e use the fact that our choice of hS cor e is an admissible heuristic in A ∗ searc h to simplify our formulation of inequalities. Due to admissibility , hS cor e ( m ) ≤ d ( m, t ), and consequently g S cor e ( l ) + hS cor e ( m ) ≤ d ( s, l ) + d ( m, l ). Replacing d e, 0 ( s, t ) with low er heuristic estimate of g S cor e ( l ) + hS cor e ( m ) in Eqn. 7 w e achiev e a stricter inequality: c ( e ) ≥ c ( P ∗ ) − g S core ( l ) − hS cor e ( m ) c ( e ) ≥ 0 ∀ e ∈ E − P ∗ (8) The cost of shortest path av oiding e ∗ ∈ P ∗ is given b y d e ∗ , ∞ ( s, t ) = min e ∈ E − P ∗ ( d ( s, e, t ) | e ∗ 6∈ d ( s, e, t )). In Fig. 5 supp ose the red edge is one such e ∗ ∈ P ∗ . Let the subtree induced b y A ∗ searc h following e ∗ is τ ( e ∗ ) (shown in dashed line) and the remainder of the tree is τ C ( e ∗ ) (shown in solid line). Based on the search pro cess, we w ould exp ect the shortest path from s to t via any edge in τ ( e ∗ ) to hav e e ∗ in it. Therefore d e ∗ , ∞ ( s, t ) should b e based on paths via edges in τ C ( e ∗ ). Since we hav e path costs that are estimated b y the heuristically A ∗ searc h ( f S cor es ) w e can use these for the op en no des in τ C ( e ∗ ). These op en no des are shown in green in Fig. 5. Hence in this setting, the inequality c ( P ∗ ) ≤ min e ∈ E − P ∗ ( d ( s, e, t ) | e ∗ 6∈ d ( s, e, t )) is replaced by the following set of inequalities: c ( P ∗ ) ≤ f S cor e ( o ) , ∀ o in the set of op en no des in τ C ( e ∗ ) (9) Due to the admissibilit y of hS cor e , f S cor e also underestimates the true distance, so we are using a stricter inequalit y in Eqn. 9. If this pro cess is rep eated for all e ∗ ∈ P ∗ our set of inequalities consist of the user defined path P ∗ b eing compared against all the set of paths defined by the op en no des in the original A ∗ searc h given in Eqn 2. 3.5 Mo deling Relationships b y Auxiliary V ariables In the previous section we formulated the user feedbac k as a set of relationships, where eac h relationship is an inequality in terms of path lengths. Since the distance metric is based on normalized topic distribution we 7 explicitly sho w the dep endence of an individual relationship on θ θ θ . F or an inequality r o ≡ c ( P ∗ ) ≤ c ( P ( o ) ) in Eqn. 2, we in tro duce a slack random v ariable λ o (i.e. λ o ≤ for some ≤ 0) as an auxiliary v ariable with exp ectation E E E ( λ o ) = µ o ( θ θ θ ) = c ( P ∗ ) − c ( P ( o ) ). Similarly for a relationship r e ≡ c ( e ) ≥ c 0 ( e ) in Eqn 3 we define a surplus random v ariable λ e where λ e is positive with exp ectation given by E E E ( λ e ) = µ o ( θ θ θ ) = c ( e ) − c 0 ( e ). Therefore µ o ( θ θ θ ) = P T t =1 (∆ ∗ t ( θ θ θ ) − ∆ ( o ) t ( θ θ θ )). Supp ose the distribution of the auxiliary v ariable is given by λ o ∼ f ( ·| θ θ θ ). The random v ariable λ o measures the difference in path lengths b et w een the user defined path P ∗ and an alternate P ( o ) . If µ o ( θ θ θ ) is zero, it means enforcing the relationship that P ∗ is as costly as the alternate path P ( o ) . The more negative the v alue of its mean µ o ( θ θ θ ), the larger w e exp ect P ( o ) to b e compared to P ∗ . This ensures that the topic space θ θ θ satisfies the relationship c ( P ∗ ) ≤ c ( P ( o ) ). Now conditional on a kno wn θ θ θ , the join t distribution of the auxiliary v ariables (b oth slack and surplus) and the observed feedback < is given b elo w: f ( < , λ λ λ | θ θ θ ) ∝ Y o ∈O { 1 c ( P ∗ ) ≤ c ( P ( o ) 1 λ o ≤ + 1 c ( e ) ≥ c o ( e ) 1 λ 0 ≥ 0 } f ( λ o | θ θ θ ) (10) Here, 1 x is an indicator v ariable whic h is one if condition x holds and zero otherwise. Our goal is to find a set of surplus and slack v ariables λ λ λ that maximizes the probability in Eqn 10. No w let f ( λ o | θ θ θ ) b e normally distributed with mean µ 0 ( θ θ θ ) and v ariance 1. By marginalizing ov er the auxiliary v ariables λ o , our formulation is same as the mo deling the probability of satisfying a relationship using the cumulativ e normal distribution. P ( c ( P ∗ ) ≤ c ( P ( o ) ) | θ θ θ ) = 1 − Φ( µ o ( θ θ θ ) − ) , for Eqn 2 P ( c ( e ) ≥ c 0 ( e ) | θ θ θ ) = Φ( µ o ( θ θ θ )) , for Eqn 3 (11) Here for a standard normal v ariable Z , Φ( z ) = P ( Z ≤ z ). This approach is v ery similar to the usage of auxiliary v ariables in probit regression [1]. In probit regression the mean of the auxiliary v ariable is modeled b y a linear predictor to maximize the discrimination b et ween the successes and failures in the data. In our case satisfiabilit y of a user defined relationship is a success and the probabilit y of satisfying the relationship is mo deled by the me an of auxiliary v ariable. The mean of the auxiliary v ariable is a function of the topic space θ θ θ on whic h the distances are defined. Our goal is to searc h for a topic space θ θ θ which explains the term distribution of the do cumen ts and satisfies as many of the relationships in < as p ossible. T runcating a slack v ariable λ o to a negativ e region sp ecified b y allo ws to searc h for θ θ θ that shrinks the mean µ o ( θ θ θ ) to a negativ e v alue. The complete hierarchical mo del using the term do cumen t data η η η and the relationship data < is presented b elo w: f ( < , λ λ λ | θ θ θ ) ∝ Y o ∈O { 1 c ( P ∗ ) ≤ c ( P ( o ) 1 λ o ≤ + 1 c ( e ) ≥ c o ( e ) 1 λ o ≥ 0 } N ( λ o | µ o ( θ θ θ ) , 1) η i | z i , φ ( z i ) ∼ Discr ete ( φ ( z i ) ) φ ∼ D ir ichlet ( β ) z i | θ ( d i ) ∼ Discr ete ( θ ( d i ) ) θ ∼ D irichl et ( α ) (12) 3.6 Inference W e use Gibbs sampling to compute the p osterior distributions for z , λ λ λ and θ θ θ . The conditional p osterior distri- butions for z i is given b elo w: p ( z i = j | z ( − i ) , η η η ) ∝ p ( η i | z i = j, z ( − i ) , η η η ( − i ) ) p ( z i = j | z ( − i ) , η η η ( − i ) ) (13) The sampling of topic for terms η η η is same as used in v anilla LDA [11]. p ( z i = j | z ( − i ) , η η η ) ∝ β + n ( η i ) ( − i,j ) M β + n ( · ) ( − i,j ) × α + n ( d i ) ( − i,j ) T α + n ( d i ) ( − i, · ) (14) The full conditional distribution for λ o is given b elo w: p ( λ o | θ θ θ , < ) = ( N ( ·| µ o ( θ θ θ ) , 1) , λ o ≤ , if r o is ≤ type N ( ·| µ o ( θ θ θ ) , 1) , λ o > 0 , if r o is > type (15) The full conditional distribution for the topic distribution of do cumen t d j is given b elo w: p ( θ ( d j ) | θ θ θ ( − d j ) , λ λ λ, z z z ) ∝ Y z i ∈ d j p ( z i | θ ( d j ) ) p ( θ ( d j ) | α ) × Y o ∈O N ( λ o | µ o ( θ θ θ ) , 1) ∝ p ( θ ( d j ) | z z z , α ) Y o ∈O N ( λ o | µ o ( θ θ θ ) , 1) ∝ T Y t =1 θ ( d j ) t ( n ( d j ) t + α ) − 1 Y o ∈O N ( λ o | µ o ( θ θ θ ) , 1) (16) 8 since p ( θ ( d j ) = D irichl et ( n ( d j ) t + α ). n ( d j ) t denotes the num b er of terms in do cumen t d j assigned to topic t based on z z z . If d j do es not b elong to < , then θ ( d j ) is sampled from D irichl et ( n ( d j ) t + α ). W e sample from p ( θ ( d j ) | θ θ θ ( − d j ) , λ λ λ, z z z ) b y a Metropolis-Hastings step otherwise. W e use a proposal strategy based on stic k-breaking pro cess to allo w better mixing. The stick-breaking pro cess b ounds the topic distribution of a document d j b et w een zero and one and their sum to one. W e first sample random v ariables u 1 , · · · , u T − 1 truncated b etw een zeros and one and centered by θ θ θ ( d j ) using a prop osal distribution q ( · ): u 1 ∼ q ·| θ ( d j ) 1 , 0 < u 1 < 1 u 2 ∼ q ·| θ ( d j ) 2 1 − u 1 ! , 0 < u 2 < 1 u 3 ∼ q ·| θ ( d j ) 3 (1 − u 1 )(1 − u 2 ) ! , 0 < u 3 < 1 . . . u T − 1 ∼ q ·| θ ( d j ) T − 1 (1 − u 1 )(1 − u 2 ) · · · (1 − u T − 2 ) ! , 0 < u T − 1 < 1 (17) This is follow ed by the mappings, S : u → θ θ θ ∗ ( d j ) 1: T − 1 , θ ∗ ( d j ) 1 = u 1 θ ∗ ( d j ) 2 = u 2 (1 − u 1 ) θ ∗ ( d j ) 3 = u 3 (1 − u 2 )(1 − u 1 ) . . . θ ∗ ( d j ) T − 1 = (1 − u T − 1 )(1 − u T − 2 ) · · · (1 − u 2 )(1 − u 1 ) (18) The inv erse mappings S − 1 : θ θ θ ∗ ( d j ) 1: T − 1 → u are given by: u 1 = θ ∗ ( d j ) 1 u t = θ ∗ ( d j ) 1 1 − P i
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment