Bi-directional LSTM Recurrent Neural Network for Chinese Word Segmentation
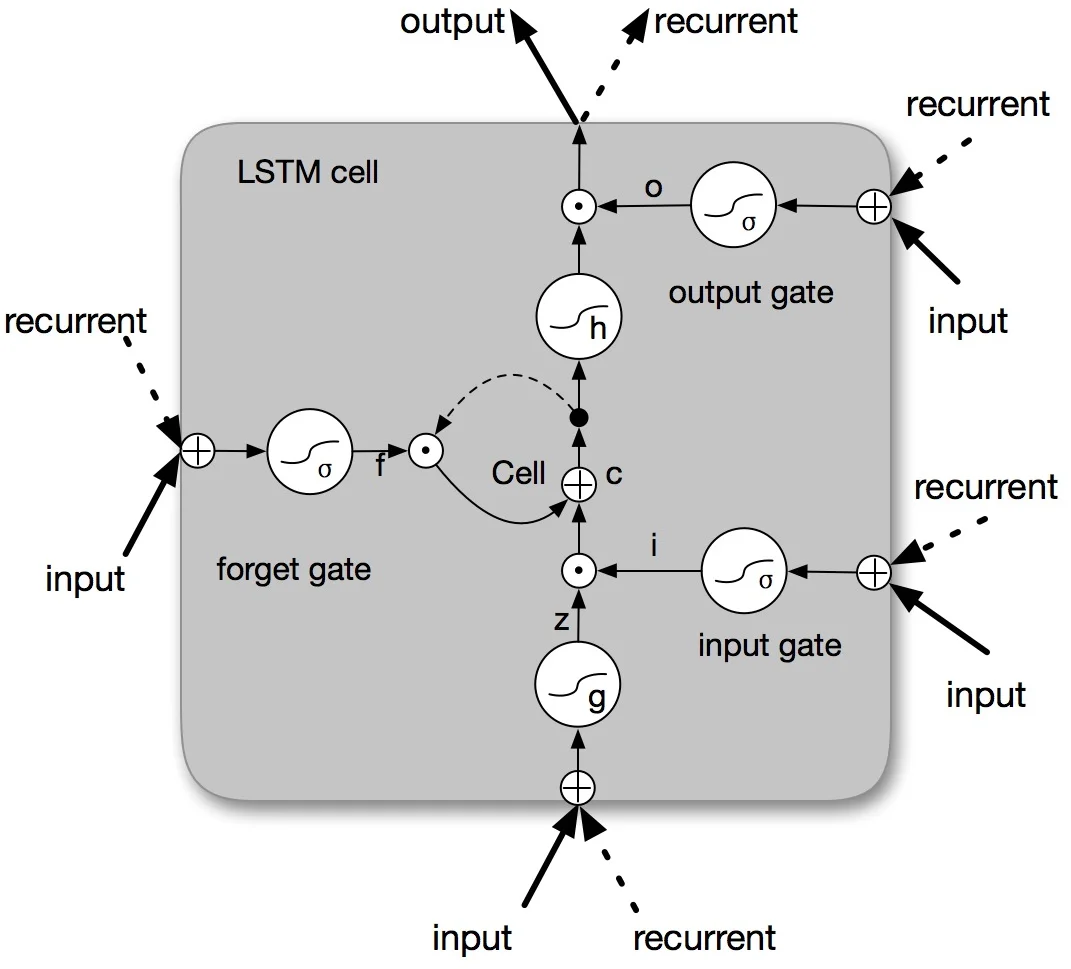
Recurrent neural network(RNN) has been broadly applied to natural language processing(NLP) problems. This kind of neural network is designed for modeling sequential data and has been testified to be quite efficient in sequential tagging tasks. In this paper, we propose to use bi-directional RNN with long short-term memory(LSTM) units for Chinese word segmentation, which is a crucial preprocess task for modeling Chinese sentences and articles. Classical methods focus on designing and combining hand-craft features from context, whereas bi-directional LSTM network(BLSTM) does not need any prior knowledge or pre-designing, and it is expert in keeping the contextual information in both directions. Experiment result shows that our approach gets state-of-the-art performance in word segmentation on both traditional Chinese datasets and simplified Chinese datasets.
💡 Research Summary
The paper presents a neural approach to Chinese Word Segmentation (CWS) that relies solely on character embeddings and a bidirectional Long Short‑Term Memory (BLSTM) network, eliminating the need for handcrafted features or external resources. The authors first reformulate CWS as a sequence tagging problem by assigning each character one of four tags—B (beginning), M (middle), E (end), or S (single)—which is a standard BEMS scheme. Each unique character in the training corpus is mapped to a dense vector of dimension d (the embedding). These embeddings are learned jointly with the segmentation model.
The core model consists of a forward LSTM and a backward LSTM running in parallel. Their hidden states are concatenated, yielding a 2d vector for each character. To prevent the dimensionality from exploding when stacking multiple BLSTM layers, a linear transformation matrix projects the 2d vector back to d before feeding it into the next BLSTM layer. The authors experiment with one, two, and three stacked BLSTM layers, applying dropout for regularization. The final hidden representation passes through a fully‑connected layer and a softmax classifier that predicts the most probable tag for each character. Training minimizes cross‑entropy loss using stochastic gradient descent (or Adam), with batch size adjusted to fit GPU memory.
Experiments are conducted on the SIGHAN 2005 benchmark, covering both simplified Chinese datasets (PKU, MSRA) and traditional Chinese datasets (AS, HK). The authors explore several hyper‑parameters: embedding dimensions of 100, 128, 200, and 300, and BLSTM depths of 1–3 layers. Results show that an embedding size of 200 yields the most stable and highest F1 scores, while adding a second or third BLSTM layer brings modest improvements; deeper stacks (>3 layers) lead to diminishing returns and longer training times. On the four test sets, the best BLSTM configuration (three layers with dropout) achieves F1 scores of 96.8 (PKU), 96.3 (MSRA), 96.5 (AS), and 97.4 (HK), surpassing or matching previous state‑of‑the‑art systems that rely on extensive feature engineering, semi‑supervised learning, or external corpora.
Key contributions claimed by the authors are: (1) the first application of a pure BLSTM architecture to CWS benchmark data, (2) a training framework that integrates character embedding learning and tagging without any handcrafted features, and (3) empirical evidence that bidirectional context (both past and future) is crucial for high‑quality segmentation. The paper also discusses practical aspects such as training time (≈16–17 hours on an NVIDIA GTX 970 GPU versus >4 days on CPU) and the impact of dropout on preventing overfitting.
Limitations acknowledged include the model’s reliance on sizable labeled corpora and GPU resources, the exclusive use of character‑level embeddings (potentially missing word‑level semantic cues), and the absence of a global decoding layer such as Conditional Random Fields that could enforce tag consistency. The authors suggest future work on combining character and word embeddings, integrating CRF layers for global optimization, and extending the approach to low‑resource domains.
In summary, the study demonstrates that a relatively simple BLSTM‑based tagger, equipped only with learned character embeddings, can achieve state‑of‑the‑art performance on both simplified and traditional Chinese word segmentation tasks, highlighting the power of deep bidirectional recurrent networks for sequential labeling without manual feature design.
Comments & Academic Discussion
Loading comments...
Leave a Comment