Multimodal Transfer Deep Learning with Applications in Audio-Visual Recognition
We propose a transfer deep learning (TDL) framework that can transfer the knowledge obtained from a single-modal neural network to a network with a different modality. Specifically, we show that we can leverage speech data to fine-tune the network trained for video recognition, given an initial set of audio-video parallel dataset within the same semantics. Our approach first learns the analogy-preserving embeddings between the abstract representations learned from intermediate layers of each network, allowing for semantics-level transfer between the source and target modalities. We then apply our neural network operation that fine-tunes the target network with the additional knowledge transferred from the source network, while keeping the topology of the target network unchanged. While we present an audio-visual recognition task as an application of our approach, our framework is flexible and thus can work with any multimodal dataset, or with any already-existing deep networks that share the common underlying semantics. In this work in progress report, we aim to provide comprehensive results of different configurations of the proposed approach on two widely used audio-visual datasets, and we discuss potential applications of the proposed approach.
💡 Research Summary
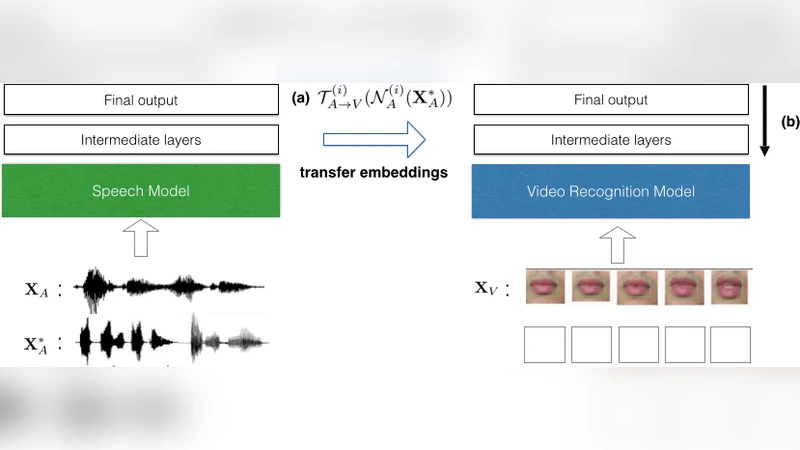
The paper introduces a Transfer Deep Learning (TDL) framework that enables knowledge transfer from a single‑modal neural network to another network operating on a different modality. The authors focus on leveraging abundant speech data to improve lip‑reading video recognition, assuming only a limited set of parallel audio‑video pairs is initially available. The method proceeds in two stages. First, abstract representations are extracted from intermediate layers of two separately trained deep belief networks (DBNs): one for audio (N_A) and one for video (N_V). For each layer i, a mapping T_{A→V}^{(i)} is learned that aligns the audio feature space H_A^{(i)} with the video feature space H_V^{(i)}. Three mapping techniques are explored: (1) multivariate Support Vector Regression with nonlinear kernels, (2) a K‑Nearest‑Neighbour non‑parametric approach, and (3) Normalized Canonical Correlation Analysis (NCCA).
Second, for previously unseen audio samples X*_A, the audio network produces H_A^{(i)} which is transformed by the learned mapping into a synthetic video representation H_V^{(i)}. This synthetic representation is injected as the input to the video network at layer i, and the subsequent layers (i … l) are fine‑tuned using standard back‑propagation. The fine‑tuning procedure is called Transfer Deep Learning Fine‑Tuning (TDLFT(i)), where the index i determines how deep the transfer occurs. Larger i values correspond to higher‑level, more semantic transfers (more reliable but affect fewer layers), while smaller i values attempt low‑level feature transfer (riskier due to modality disparity).
The authors evaluate the approach on two widely used audio‑visual datasets: AV‑Letters (26 alphabet letters) and the Stanford dataset (49 classes including digits and letters). They artificially create an imbalance by restricting the video training set to the first 20 (or 44) classes, while the audio set contains all classes. Unparallel audio data for the remaining classes is used only for transfer. Experiments compare three embedding methods combined with TDLFT at i=3 (mid‑high layer) and i=0 (raw input). Results show that TDL with TDLFT(3) consistently outperforms the unimodal video baseline, achieving 4–7 percentage‑point gains in classification accuracy. KNN‑based transfer yields the best performance, followed by NCCA and SVR. Transfer at the raw input level (i=0) does not improve performance and can even degrade it, confirming that low‑level feature spaces are too dissimilar for reliable mapping. An “Oracle” scenario—assuming perfect transfer—provides an upper bound, indicating that further improvements in embedding quality could close the gap.
The paper concludes that abstract, intermediate‑layer representations are more amenable to cross‑modal transfer than raw features, and that the proposed TDL framework can boost target‑modality performance without altering its network architecture. Future directions include extending the framework to top‑down generation (e.g., synthesizing lip‑motion videos from audio) and exploring more sophisticated joint latent spaces to enhance transfer fidelity.
Comments & Academic Discussion
Loading comments...
Leave a Comment