Choice by Elimination via Deep Neural Networks
We introduce Neural Choice by Elimination, a new framework that integrates deep neural networks into probabilistic sequential choice models for learning to rank. Given a set of items to chose from, the elimination strategy starts with the whole item …
Authors: Truyen Tran, Dinh Phung, Svetha Venkatesh
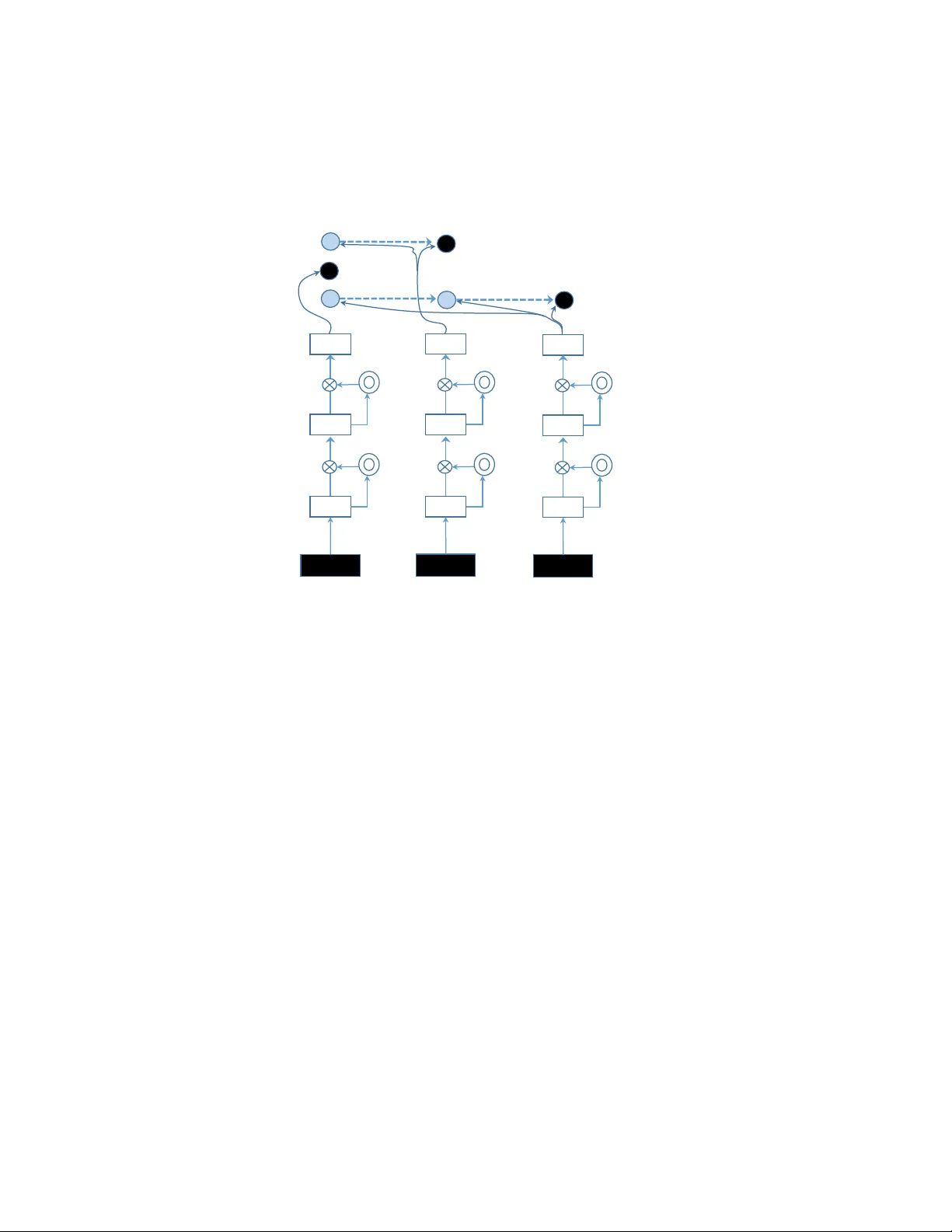
Choice b y Elimination via Deep Neural Net w orks T ruy en T ran, Dinh Ph ung and Sv etha V enk atesh Cen tre for Pattern Recognition and Data Analytics Deakin Universit y , Geelong, Australia { truyen.tr an,dinh.phung,svetha.venkatesh } @de akin.e du.au Octob er 1, 2018 Abstract W e in tro duce Neur al Choic e by Elimination , a new framework that integrates deep neural net works in to probabilistic sequential c hoice mo dels for learning to rank. Given a set of items to c hose from, the elimination strategy starts with the whole item set and iteratively eliminates the least worth y item in the remaining subset. W e pro ve that the choice b y elimination is equiv alent to marginalizing out the random Gompertz latent utilities. Coupled with the c hoice mo del is the recen tly introduced Neural High wa y Netw orks for appro ximating arbitrarily complex rank functions. W e ev aluate the prop osed framework on a large-scale public dataset with ov er 425 K items, drawn from the Y aho o! learning to rank challenge. It is demonstrated that the prop osed metho d is comp etitive against state-of-the-art learning to rank metho ds. 1 In tro duction P eople often rank options when making choice. Ranking is central in many social and individual con texts, ranging from election [ 16 ], sp orts [ 17 ], information retriev al [ 22 ], question answering [ 1 ], to recommender systems [ 32 ]. W e fo cus on a setting known as learning to rank (L2R) in whic h the system learns to c ho ose and rank items (e.g. a set of do cumen ts, p otential answ ers, or shopping items) in resp onse to a query (e.g., keyw ords, a question, or an user). Tw o main elemen ts of a L2R system are rank model and rank function. One of the most promising rank mo dels is listwise [ 22 ] where all items resp onding to the query are considered simultaneously . Most existing work in L2R fo cuses on designing listwise rank losses rather than formal models of choic e , a crucial asp ect of building preference-aw are applications. One of a few exceptions is the Plac kett-Luce mo del which originates from Luce’s axioms of choice [ 24 ] and is later used in the context of L2R under the name ListMLE [ 34 ]. The Plac k ett-Luce model offers a natural interpretation of making sequential c hoices. First, the probability of c ho osing an item is prop ortional to its w orth. Second, once the most probable item is chosen, the next item will b e pick ed from the remaining items in the same fashion. Ho wev er, the Plack ett-Luce mo del suffers from tw o drawbac ks. First, the mo del sp ends effort to separate items down the rank list, while only the first few items are usually imp ortant in practice. Th us the effort in making the right ordering should b e sp ent on more imp ortan t items. Second, the Plac kett-Luce is inadequate in explaining man y comp etitive situations, e.g., sp ort tournaments and buying preferences, where the ranking pro cess is rev ersed – worst items are eliminated first [33]. Addressing these drawbac ks, we introduce a probabilistic sequential rank mo del termed choic e by elimination . At each step, we remov e one item and rep eat until no item is left. The rank of items is 1 gate input rank sc ore elimination o rde r gate A B C A C C Figure 1: Neur al choic e by elimination with 4-lay er highw ay netw orks for ranking three items (A,B,C). Empt y b oxes represent hidden la y ers that share the same parameters (hence, recurrent). Double circles are gate that con trols information flow. Dark filled circles represen t a c hosen item at eac h step – here the elimination order is (B,A,C). then the reverse of the elimination order. This elimination pro cess has an imp ortan t prop ert y: Near the end of the pro cess, only b est items compete against the others. This is unlike the selection pro cess in Plac kett-Luce, where the b est items are contrasted against all other alternatives. W e may face difficulty in separating items of similarly high quality but can ignore irrelev ant items effortlessly . The elimination mo del th us reflects more effort in ranking w orthy items. Once the ranking model has been specified, the next step in L2R is to design a rank function f ( x ) of query-sp ecific item attributes x [ 22 ]. W e lev erage the newly introduced highway networks [ 28 ] as a rank function approximator. Highw ay netw orks are a compact deep neural netw ork architecture that enables passing information and gradient through hundreds of hidden lay ers b etw een input features and the function output. The high w ay net works coupled with the prop osed elimination mo del constitute a new framework termed Neur al Choic e by Elimination (NCE) illustrated in Fig. 1. The framework is an alternative to the current state-of-the-arts in L2R whic h inv olve tree ensembles [ 12 , 5 , 4 ] trained with hand-crafted metric-aw are losses [ 7 , 21 ]. Unlik e the tree ensembles where t ypically h undreds of trees are maintained, highw ay netw orks can b e trained with dr op outs [ 27 ] to pro duce an implicit ensemble with only one thin netw ork. Hence we aim to establish that de ep neur al networks ar e c omp etitive in L2R . While shallow neural netw orks ha ve b een used in ranking b efore [ 6 ], they w ere outp erformed by tree ensembles [ 21 ]. Deep neural nets are compact and more p ow erful [ 3 ], but they hav e not b een measured against tree-based ensem bles for generic L2R problems. W e empirically 2 demonstrate the effectiveness of the proposed ideas on a large-scale public dataset from Y aho o! L2R c hallenge with totally 18 . 4 thousands queries and 425 thousands do cuments. T o summarize, our pap er makes the follo wing con tributions: (i) introducing a new neural sequential c hoice model for learning to rank; and (ii) establishing that deep nets are scalable and competitive as rank function approximator in large-scale settings. 2 Bac kground 2.1 Related W ork The elimination pro cess has b een found in multiple comp etitive situations such as m ultiple round con tests and buying decisions [ 14 ]. Choic e by elimination of distractors has b een long studied in the psyc hological literature, since the pioneer work of Tversky [ 33 ]. These backw ard elimination mo dels ma y offer b etter explanation than the forward selection when eliminating asp ects are a v ailable [ 33 ]. Ho wev er, existing studies are mostly on selecting a single best c hoice. Multiple sequen tial eliminations are muc h less studied [ 2 ]. Second, most prior work has b een ev aluated on a handful of items with several attributes, whereas we consider hundreds of thousands of items with thousands of attributes. Third, the cross-field connection with data mining has not b een made. The link b et ween choice mo dels and Random Utility Theory has b een well-studied since Th urstone in the 1920s, and is still an activ e topic [ 2 , 30 , 31 ]. Deep neural netw orks for L2R hav e b een studied in the last t wo years [ 18 , 10 , 26 , 11 , 25 ]. Our work contributes a formal reasoning of human choices together with a newly in tro duced highw ay net works which are v alidated on large-scale public datasets against state-of-the-art metho ds. 2.2 Plac k ett-Luce W e now review Plack ett-Luce mo del [ 24 ], a forw ard selection metho d in learning to rank, also kno wn in the L2R literature as ListMLE [ 34 ]. Giv en a query and a set of response items I = (1 , 2 , .., N ) , the rank choice is an ordering of items π = ( π 1 , π 2 , ..., π N ), where π i is the index of item at rank i . F or simplicit y , assume that eac h item π i is asso ciated with a set of attributes, denoted as x π i ∈ R p . A rank function f ( x π i ) is defined on π i and is indep endent of other items. W e aim to characterize the rank p erm utation mo del P ( π ). Let us start from the classic probabilistic theory that any joint distribution of N v ariables can be factorized according to the c hain-rule as follows P ( π ) = P ( π 1 ) N Y i =2 P ( π i | π 1: i − 1 ) (1) where π 1: i − 1 is a shorthand for ( π 1 , π 2 , .., π i − 1 ), and P ( π i | π 1: i − 1 ) is the probabilit y that item π i has rank i giv en all existing higher ranks 1 , ..., i − 1. The factorization can b e interpreted as follows: c ho ose the first item in the list with probability of P ( π 1 ), and c ho ose the second item from the remaining items with probability of P ( π 2 | π 1 ), and so on. Luce’s axioms of choic e assert that an item is chosen with probability prop ortional to its worth . This translates to the follo wing choice mo del: P ( π i | π 1: i − 1 ) = exp ( f ( x π i )) P N j = i exp f ( x π j ) 3 Learning using maximizing likelihoo d minimizes the log-loss: ` 1 ( π ) = N − 1 X i =1 − f ( x π i ) + log N X j = i exp f ( x π j ) (2) 3 Choice b y Elimination W e note that the factorization in Eq. (1) is not unique. If w e p ermute the indices of items, the factorization still holds. Here we derive a r everse Plack ett-Luce mo del as follo ws P ( π ) = Q ( π N ) N − 1 Y i =1 Q ( π i | π i +1: N ) (3) where Q ( π i | π i +1: N ) is the probabilit y that item π i receiv es rank i giv en all existing low er ranks i + 1 , i + 2 , ..., N Since π N is the most irrelev an t item in the list, Q ( π N ) can be considered as the probability of eliminating the item. Th us the en tire pro cess is backw ard elimination: The next irrelev ant item π k is eliminated, given that more extraneous items ( π i>k ) ) hav e already been eliminated. It is reasonable to assume that the pr ob ability of an item b eing eliminate d is inversely pr op ortional to its worth. This suggests the following sp ecification Q ( π i | π i +1: N ) = exp ( − f ( x π i )) P i j =1 exp − f ( x π j ) . (4) Note that, due to specific choices of conditional distributions, distributions in Eqs. (1,3) are generally not the same. With this mo del, the log-loss has the follo wing form: ` 2 ( π ) = N X i =1 f ( x π i ) + log i X j =1 exp − f ( x π j ) (5) 3.1 Deriv ation using Random Utility Theory . Random Utility Theory [ 2 , 29 ] offers an alternative that explains the ordering of items. Assume that there exists latent utilities { u i } , one p er item { π i } . The ordering P ∗ ( π ) is defined as Pr ( u 1 ≥ u 2 ≥ ... ≥ u N ) . Here we show that it is linked to Gomp ertz distribution . Let u j ≥ 0 denote the laten t random utilit y of item π j . Let v j = e bu j , the Gomp ertz distribution has the PDF P j ( u j ) = bη j v j exp ( − η j v j + η j ) and the CDF F j ( u j ) = 1 − exp ( − η j ( v j − 1)), where b > 0 is the scale and η > 0 is the shape parameter. A t rank i , choosing the worst item π i translates to ensuring u i ≤ u j for all j < i . The random utilit y theory states that probability of choosing π i can b e obtained by integrating out all latent utilities sub ject to the inequalit y constraints: 4 Q ( π i | π i +1: N ) = ˆ + ∞ 0 P i ( u i ) ˆ + ∞ u i Y j 0, where ∂ ` 1 , 2 ∂ f ( x π k ) are functional gradients derived from Eqs. (2,5). 5 Exp erimen tal Ev aluation 5.1 Data & Ev aluation Metrics W e v alidate the prop osed mo del using a large-scale W eb dataset from the Y aho o! learning to rank c hallenge [ 8 ], . The dataset is split into a training set of 18 , 425 queries (425 , 821 documents), and a testing set of 1 , 520 queries (47 , 313 do cumen ts). W e also prepare a smaller training subset, called Y aho o!-small, whic h has 1 , 568 queries and 47 , 314 do cuments. The Y aho o! datasets contain the groundtruth relev ance scores (from 0 for irrelev ant to 4 for perfectly relev ant). There are 519 pre- computed unique features for eac h query-do cument pair. W e normalize the features across the whole training set to hav e mean 0 and standard deviation 1. Tw o ev aluation metrics are employ ed. The Normalized Discount Cumulativ e Gain [ 19 ] is defined as: N G @ T = 1 N max T X i =1 2 r π i − 1 log 2 (1 + i ) where r π i is the relev ance of item at rank i . The other metric is Exp ected Recipro cal Rank (ERR) [ 9 ], whic h was used in the Y aho o! learning-to-rank challenge (2011): E RR = X i R ( r π i ) i Y j >i 1 − R ( r π j ) , s.t. R ( r π i ) = 2 r π i − 1 16 Both metrics discount for the long list and place more emphasis on the top ranking. Finally , all metrics are av eraged across all test queries. 5.2 Mo del Implementation The high wa y nets are configured as follows. Unless stated otherwise, we use ReLU units for transforma- tion H ( z ). Parameters W 1 , W H and W T are initialized randomly from a small Gaussian. Gate bias b T is initialized at − 1 to encourage passing more information, as suggested in [ 28 ]. T ransform bias b H is initialized at 0. T o preven t ov erfitting, dropout [ 27 ] is used, i.e., during training for each item 6 0 0.1 0.2 0.3 0.4 0.5 0.43 0.44 0.45 0.46 0.47 0.48 0.49 0.5 hidden dropout rate ERR K=10,p vis =0 K=20,p vis =0 K=20,p vis =0.1 Figure 2: Effect of drop outs on NCE p erformance of a 3-la yer highw a y nets on Y aho o! small set. K is n umber of hidden units, p v is is drop out rate for visible lay er. 7 Y aho o!-small Y aho o!-large Rank mo del ERR NDCG@1 NDCG@5 ERR NDCG@1 NDCG@5 Rank SVM 0.477 0.657 0.642 0.488 0.681 0.666 Plac kett-Luce 0.489 0.683 0.652 0.495 0.699 0.671 Choice by elimination 0.497 0.697 0.664 0.503 0.709 0.680 T able 1: Performance with linear rank functions. Plac ket-Luce Choice by elimination Rank function ERR NDCG@1 NDCG@5 ERR NDCG@1 NDCG@5 SGTB 0.497 0.697 0.673 0.506 0.705 0.681 Neural nets 0.501 0.705 0.688 0.509 0.719 0.697 Figure 3: Comparing highw ay neural netw orks against sto chastic gradient tree b o osting (SGTB) on Y aho o!-large dataset. in a mini-batc h, input features and hidden units are randomly dropp ed with probabilities p v is and p hid , resp ectively . As drop outs ma y cause big jumps in gradient and parameters, w e set max-norm p er hidden unit to 1. The mini-batch size is 2 queries, the learning rate starts from 0 . 1, and is halved when there is no sign of improv emen t in training loss. Learning stops when learning rate falls b elow 10 − 4 . W e fix the dropout rates as follo ws: (a) for small Y aho o! data, p v is = 0, p hid = 0 . 3 and K = 10; (b) for large Y aho o! data, p v is = 0, p hid = 0 . 2 and K = 20. Fig. 2 sho ws the effect of drop outs on the NCE mo del on the small Y aho o! dataset. 5.3 Results 5.3.1 P erformance of choice models. In this exp eriment we ask whether the new choice by elimination mo del has an y adv antage ov er existing state-of-the-arts (the forw ard selection method of Plac kett-Luce [ 34 ] and the p opular Rank SVM [ 20 ]). T able 1 reports results on the all datasets (Y aho o!-small, Y aho o!-large) on different sequential mo dels. The NCE w orks better than Rank SVM and Plac kett-Luce. Note that due to the large size, the differences are statistically significant. In fact, in the Y aho o! L2R c hallenge, the top 20 scores (out of more than 1,500 teams) differ only by 1.56% in ERR, whic h is less than the difference b etw een Plac kett-Luce and c hoice by elimination (1.62%). 5.3.2 Neural nets v ersus gradient b o osting. W e also compare the high wa y netw orks against the best p erforming metho d in the Y ahoo! L2R challenge. Since it was consistently demonstrated that gradien t b o osting trees work best [ 8 ], we implemen t a sophisticated v ariant of Sto chastic Gradient T ree Bo osting (SGTB) [ 13 ] for comparison. In SGTB, at eac h iteration, regression trees are grown to fit a random subset of functional gradien ts ∂ ` ∂ f ( x ) . Grown trees are added to the ensemble with an adaptive learning rate whic h is halv ed whenev er the loss fluctuates and do es not decrease. At each tree no de, a random subset of features is used to split the no de, follo wing [ 4 ]. T ree no des are split at random as it leads to muc h faster tree growing without h urting performance [ 15 ]. The SGTB is configured as follo ws: num b er of trees is 300; learning rate starts at 0 . 1; a random subset of 50% data is used to grow a tree; one third of features are randomly 8 selected at each no de; trees are gro wn until either the num b er of lea v es reac hes 512 or the no de size is b elo w 40. T able. 3 sho w p erformance scores of mo dels trained under different losses on the Y aho o!-large dataset. The highw ay neural net works are consistently comp etitiv e against the gradien t tree b o osting, the b est p erforming rank function appro ximator in this c hallenge [8]. 6 Conclusion W e ha ve presen ted Neur al Choic e by Elimination , a new framework that integrates deep neural netw orks in to a formal modeling of human b eha viors in making sequen tial choices. Contrary to the standard Plac kett-Luce mo del, where the most w orthy items are iteratively selected, here the least w orth y items are iteratively eliminated. Theoretically w e sho w that choice by elimination is equiv alent to sequentially marginalizing out Th urstonian random utilities that follow Gomp ertz distributions. Exp erimentally we establish that deep neural net w orks are competitive in the learning to rank domain, as demonstrated on a large-scale public dataset from the Y aho o! learning to rank challenge. References [1] Arvind Agarwal, Hema Raghav an, Karthik Subbian, Prem Melville, Richard D La wrence, David C Gondek, and James F an. Learning to rank for robust question answering. In Pr o c e e dings of the 21st A CM international c onfer enc e on Information and know le dge management , pages 833–842. A CM, 201 2. [2] Hossein Azari, Da vid Parks, and Lirong Xia. Random utility theory for social c hoice. In A dvanc es in Neur al Information Pr o c essing Systems , pages 126–134, 2012. [3] Y oshua Bengio. Learning deep architectures for AI. F oundations and tr ends R in Machine L e arning , 2(1):1–127, 2009. [4] L. Breiman. Random forests. Machine le arning , 45(1):5–32, 2001. [5] Leo Breiman. Bagging predictors. Machine L e arning , 24(2):123–140, 1996. [6] C. Burges, T. Shaked, E. Renshaw, A. Lazier, M. Deeds, N. Hamilton, and G. Hullender. Learning to rank using gradient descent. In Pr o c e e dings of the 22nd international c onfer enc e on Machine le arning , page 96. A CM, 2005. [7] Christopher JC Burges, Krysta Marie Svore, Paul N Bennett, Andrzej Pastusiak, and Qiang W u. Learning to rank using an ensemble of lambda-gradient mo dels. In Y aho o! L e arning to R ank Chal lenge , pages 25–35, 2011. [8] O. Chap elle and Y. Chang. Y aho o! learning to rank c hallenge ov erview. In JMLR Workshop and Confer enc e Pr o c e e dings , volume 14, pages 1–24, 2011. [9] O. Chap elle, D. Metlzer, Y. Zhang, and P . Grinspan. Exp ected recipro cal rank for graded relev ance. In CIKM , pages 621–630. A CM, 2009. [10] Li Deng, Xiao dong He, and Jianfeng Gao. Deep stacking netw orks for information retriev al. In A c oustics, Sp e e ch and Signal Pr o c essing (ICASSP), 2013 IEEE International Confer enc e on , pages 3153–3157. IEEE, 2013. 9 [11] Y uan Dong, Chong Huang, and W ei Liu. Rankcnn: When learning to rank encoun ters the pseudo preference feedback. Computer Standar ds & Interfac es , 36(3):554–562, 2014. [12] Jerome H. F riedman. Greedy function approximation: a gradient b o osting machine. Annals of Statistics , 29(5):1189–1232, 2001. [13] J.H. F riedman. Sto chastic gradien t b o osting. Computational Statistics and Data A nalysis , 38(4):367– 378, 2002. [14] Qiang F u, Jingfeng Lu, and Zhewei W ang. ’reverse’ nested lottery con tests. Journal of Mathematic al Ec onomics , 50:128–140, 2014. [15] Pierre Geurts, Damien Ernst, and Louis W ehenkel. Extremely randomized trees. Machine le arning , 63(1):3–42, 2006. [16] Isob el Claire Gormley and Thomas B rendan Murphy . A mixture of exp erts mo del for rank data with applications in election studies. The A nnals of Applie d Statistics , 2(4):1452–1477, 2008. [17] RJ Henery . P ermutation probabilities as models for horse races. Journal of the R oyal Statistic al So ciety, Series B , 43(1):86–91, 1981. [18] P o-Sen Huang, Xiao dong He, Jianfeng Gao, Li Deng, Alex Acero, and Larry Heck. Learning deep structured semantic mo dels for web search using clickthrough data. In Pr o c e e dings of the 22nd ACM international c onfer enc e on Confer enc e on information & know le dge management , pages 2333–2338. ACM, 2013. [19] K. J¨ arv elin and J. Kek¨ al¨ ainen. Cumulated gain-based ev aluation of IR techniques. A CM T r ansac- tions on Information Systems (TOIS) , 20(4):446, 2002. [20] T. Joachims. Optimizing search engines using clickthrough data. In Pr o c e e dings of the eighth ACM SIGKDD international c onfer enc e on Know le dge disc overy and data mining , pages 133–142. A CM New Y ork, NY, USA, 2002. [21] P . Li, C. Burges, Q. W u, JC Platt, D. Koller, Y. Singer, and S. Row eis. Mcrank: Learning to rank using m ultiple classification and gradient b o osting. A dvanc es in neur al information pr o c essing systems , 2007. [22] Tie-Y an Liu. L e arning to r ank for information r etrieval . springer, 2011. [23] D. McF adden. Conditional logit analysis of qualitative choice b ehavior. F r ontiers in Ec onometrics , pages 105–142, 1973. [24] R.L. Plack ett. The analysis of p ermutations. Applie d Statistics , pages 193–202, 1975. [25] Aliaksei Severyn and Alessandro Mosc hitti. Learning to rank short text pairs with c on volutional deep neural net w orks. In Pr o c e e dings of the 38th International ACM SIGIR Confer enc e on R ese ar ch and Development in Information R etrieval , pages 373–382. A CM, 2015. [26] Y ang Song, Hongning W ang, and Xiao dong He. Adapting deep ranknet for p ersonalized search. In Pr o c e e dings of the 7th A CM international c onfer enc e on Web se ar ch and data mining , pages 83–92. A CM, 201 4. 10 [27] Nitish Sriv astav a, Geoffrey Hinton, Alex Krizhevsky , Ilya Sutskev er, and Ruslan Salakhutdino v. Drop out: A simple w ay to preven t neural net works from o verfitting. Journal of Machine L e arning R ese ar ch , 15:1929–1958, 2014. [28] Rup esh Kumar Sriv astav a, Klaus Greff, and J ¨ urgen Schmidh ub er. T raining very deep netw orks. arXiv pr eprint arXiv:1507.06228 , 2015. [29] L.L. Thurstone. A la w of comparative judgmen t. Psycholo gic al r eview , 34(4):273, 1927. [30] T. T ran, D. Ph ung, and S. V enk atesh. Thurstonian Boltzmann Machines: Learning from Multiple Inequalities. In International Confer enc e on Machine L e arning (ICML) , Atlan ta, USA, June 16-21 2013. [31] T. T ran, D.Q. Phung, and S. V enk atesh. Sequential decision approach to ordinal preferences in recommender systems. In Pr o c. of the 26th AAAI Confer enc e , T oronto, Ontario, Canada, 2012. [32] T. T ruyen, D.Q Ph ung, and S. V enk atesh. Probabilistic mo dels o ver ordered partitions with applications in do cument ranking and collab orative filtering. In Pr o c. of SIAM Confer enc e on Data Mining (SDM) , Mesa, Arizona, USA, 2011. SIAM. [33] Amos Tversky . Elimination by asp ects: A theory of choice. Psycholo gic al r eview , 79(4):281, 1972. [34] F. Xia, T.Y. Liu, J. W ang, W. Zhang, and H. Li. Listwise approach to learning to rank: theory and algorithm. In Pr o c e e dings of the 25th international c onfer enc e on Machine le arning , pages 1192–1199. ACM, 2008. [35] John I Y ellott. The relationship betw een Luce’s choice axiom, Thurstone’s theory of comparative judgmen t, and the double exp onen tial distribution. Journal of Mathematic al Psycholo gy , 15(2):109– 144, 1977. 11
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment