Probabilistic Numerics and Uncertainty in Computations
We deliver a call to arms for probabilistic numerical methods: algorithms for numerical tasks, including linear algebra, integration, optimization and solving differential equations, that return uncertainties in their calculations. Such uncertainties…
Authors: Philipp Hennig, Michael A Osborne, Mark Girolami
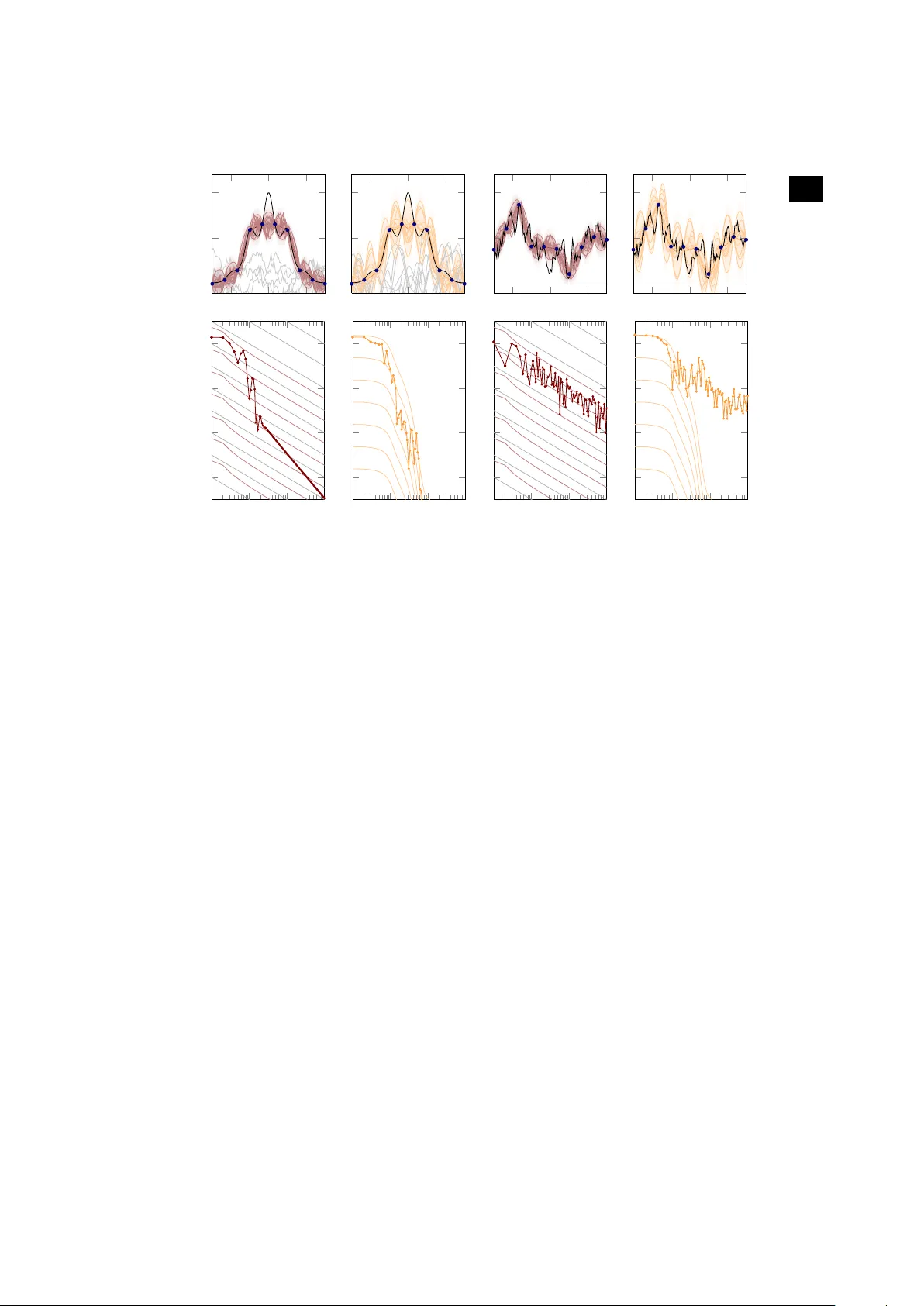
rspa.ro yalsocietypub lishing.org Research Ar ticle submitted to journal Subject Areas: Statistics, Computational Mathematics, Artificial Intelligence Ke ywords: numerical methods, probability , inf erence, statistics A uthor for correspondence: Philipp Hennig e-mail: phennig@tue.mpg.de Probabilistic Numer ics and Uncer tainty in Computations Philipp Hennig 1 , Michael A Osbor ne 2 and Mark Girolami 3 1 Max Planck Institute f or Intelligent Systems, Tübingen, Germany 2 University of Oxf ord, United Kingdom 3 University of W arwick, United Kingdom W e deliver a call to arms for probabilistic numerical methods : algorithms for numerical tasks, including linear algebra, integration, optimization and solving differ ential equations, that return uncertainties in their calculations. Such uncertainties, arising from the loss of precision induced by numerical calculation with limited time or hardware, are important for much contemporary science and industry . W ithin applications such as climate science and astr ophysics, the need to make decisions on the basis of computations with large and complex data has led to a renewed focus on the management of numerical uncertainty . W e describe how several seminal classic numerical methods can be interpreted naturally as probabilistic inference. W e then show that the probabilistic view suggests new algorithms that can flexibly be adapted to suit application specifics, while delivering improved empirical performance. W e provide concrete illustrations of the benefits of probabilistic numeric algorithms on real scientific problems fr om astrometry and astr onomical imaging, while highlighting open problems with these new algorithms. Finally , we describe how probabilistic numerical methods provide a coher ent framework for identifying the uncertainty in calculations performed with a combination of numerical algorithms (e.g. both numerical optimisers and dif ferential equation solvers), potentially allowing the diagnosis (and control) of error sources in computations. © The Authors . Published by the Roy al Society under the ter ms of the Creative Commons Attribution License http://creativecommons.org/licenses/ by/4.0/, which per mits unrestricted use, provided the or iginal author and source are credited. 2 rspa.ro yalsocietypub lishing.org Proc R Soc A 0000000 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1. Introduction Probability theory is the quantitative framework for scientific infer ence [ 21 ]. It codifies how observations (data) combine with modelling assumptions (prior distributions and likelihood functions) to give evidence for or against a hypothesis and values of unknown quantities. There is continuing debate about how prior assumptions can be chosen and validated [e.g. 19 , §1.2.3]; but the role of probability as the language of uncertainty is rar ely questioned. That is, as long as the subject of inference is a physical variable. What if the quantity in question is a mathematical statement, the solution to a computational task? Does it make sense to assign a probability measure p ( x ) over the solution of a linear system of equations Ax = b if A and b are known? If so, what is the meaning of p ( x ) , and can it be identified with a notion of ‘uncertainty’? If one sees the use of probability in statistics as a way to remove “noise” from “signal”, it seems mi sguided to apply it to a deterministic mathematical problem. But noise and stochasticity are themselves dif ficult to define precisely . Pr obability theory does not rest on the notion of randomness ( aleatory uncertainty), but extends to quantifying epistemic uncertainty , arising solely fr om missing information 1 . Connections between deterministic computations and probabilities have a long history . Erdös and Kac [ 5 ] showed that the number of distinct prime factors in an integer follows a normal distribution. Their statement is precise, and useful for the analysis of factorization algorithms [ 24 ], even though it is difficult to “sample” from the integers. It is meaningful without appealing to the concept of epistemic uncertainty . Probabilistic and deterministic methods for inference on physical quantities have shared dualities from very early on: Legendre introduced the method of least- squares in 1805 as a deterministic best fit for data without a pr obabilistic interpretation. Gauss’ 1809 probabilistic formulation of the exact same method added a generative stochastic model for how the data might be assumed to have arisen. Legendre’s least-squares is a useful method without the generative interpretation, but the Gaussian formulation adds the important notion of uncertainty (also interpretable as model capacity) that would later become crucial in areas like the study of dynamical systems. 2 Several authors [ 4 , 35 , 42 ] have shown that the language of probabilistic inference can be applied to numerical problems, using a notion of uncertainty about the result of an intractable or incomplete computation, and giving rise to methods we will here call probabilistic numerics 3 . In such methods, uncertainty r egularly arises solely from the lack of information inherent in the solution of an “intractable” problem: A quadrature method, for example, has access only to finitely many function values of the integrand; an exact answer would, in principle, require infinitely many such numbers. Algorithms for problems like integration and optimization proceed iteratively , each iteration providing information impr oving a running estimate for the correct answer . Probabilistic numerics provides methods that, in place of such estimates, update probability measures over the space of possible solutions. As Diaconis noted [ 4 ], it appears that Poincaré pr oposed such an approach alr eady in the 19th century . The recent explosive growth of automated inference, and the increasing importance of numerics for science, has given this idea new ur gency . This article connects recent results, promising applications, and central questions for probabilistic numerics. W e collate results showing that a number of basic, popular numerical methods can be identified with families of probabilistic inference procedur es. The probability measures arising from this new interpretation of established methods can offer improved 1 Many r esources discussing epistemic uncertainty can be found, at the time of writing, at http:// understandinguncertainty.org (the authors are not affiliated with this web page) 2 In fact, the very same connection between least-squares estimation and Gaussian inference has been re-discovered repeatedly , simply because least-squares estimation has been re-discovered repeatedly after Legendr e, under names like ridge regression [ 18 ], Kriging [ 25 ], T ikhonov’s method [ 44 ], and so on. The fundamental connection is that the normal distribution is the exponential of the square ` 2 norm. Because the exponential is a monotonic function, minimizing an ` 2 -regularized ` 2 loss is equivalent to maximizing the product of Gaussian prior and likelihood. In this sense, this paper is adding numerical mathematicians to the list as yet another group of re-discoverers of Gaussian inference. Ironically , this list includes Gauss himself, because Gaussian elimination, introduced in the very same paper as the Gaussian distribution itself [ 7 ], can be interpreted as a conjugate-dir ection method [ 17 ], and thus as Gaussian regression [ 14 ]. See also [ 41 ]. 3 The probabilistic numerics community web site can be found at http://www.probabilistic- numerics.org . 3 rspa.ro yalsocietypub lishing.org Proc R Soc A 0000000 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . performance, enticing new functionality , and conceptual clarit y; we demonstrate this with examples drawn from astrometry and computational photography . The article closes by pointing out the propagation of uncertainty through computational pipelines as a guiding goal for probabilistic numerics. It may be helpful to separate the issues discussed here clearly from other areas of overlap between statistics and numerical mathematics: W e here focus on well-posed deterministic pr oblems, identifying degrees of uncertainty arising from the computation itself. This is in contrast to the notion of uncertainty quantification [e.g. 22 , 23 ], which identifies degrees of fr eedom in ill-posed problems, and wher e epistemic uncertainty arises from the set-up of the computation, rather than the computation itself. It also differs fr om several concepts of stochastic numerical methods, which use (aleatory) random numbers either to quantify uncertainty from r epeated computations [e.g. 20 ], or to reduce computational cost through randomly chosen projections [see for example 11 , 28 ]. It is also important to note that, as a matter of course, existing frameworks already analyse and estimate the error created by a numerical algorithm. Theoretical analysis of computational err ors generally yields convergence rates—bounds up to an unknown constant—made under certain structural assumptions. Wher e probabilistic numerical methods ar e derived from classic ones, as described below , they naturally inherit such analytical properties. At runtime, the error is also estimated for the specific problem instance. Such run-time error estimation is frequently performed by monitoring the dynamics of the algorithm’s main estimate [see 10 , §II.4, for ODEs], [ 3 , §4.5, for quadrature]. Similarly , in optimization pr oblems, the magnitude of the gradient is often used to monitor the algorithm’s progr ess. Such error estimates are informal, as ar e the solution estimates computed by the numerical method itself. They are meant to be used locally , mostly a criteria for the termination of a method, and the adaptation of its internal parameters. They can not typically be interpreted as a property (e.g. the variance) of a posterior probability measur e, and thus can not be communicated to other algorithms, and thus can not be embedded in a lar ger framework of error estimation. They also do not usually inform the design of the numerical algorithm itself; instead, they are a diagnostic tool added post-hoc. Below , we argue that the estimation of errors should be given a formal framework, and that pr obability theory is uniquely suited for this task. Describing numerical computations as inference on a latent quantity yields a joint, consistent, framework for the construction of solution and error estimates. The inference perspective can provide a natural intuition that may suggest extensions and impr ovements. And the probabilistic framework provides a lingua franca for numerical computations, which allows the communication of uncertainty between methods in a chain of computation. 2. Probabilistic numerical methods from classical ones Numerical algorithms estimate quantities not directly computable, using the results of mor e r eadily available computations. Even existing numerical methods can thus be seen as inference rules, reasoning about latent quantities from “observables”, or “data”. At face value, this connection between inference and computation is vague. But several recent results have shown that it can be made rigor ous, such that established deterministic rules for various numerical problems can be understood as maximum a-posteriori estimates under specific priors (hypothesis classes) and likelihoods (observation models). The recurring pictur e is that there is a one-to-many relationship between a classic numerical method for a specific task and a family of pr obabilistic priors which give the same maximum posterior estimate but dif fering measures of uncertainty . Choosing one member of this family amounts to fitting an uncertainty , a task we call uncertainty calibration . The result of this process is a numerical method that returns a point estimate surrounded by a probability measure of uncertainty , such that the point estimate inherits the proven theoretical properties of the classic method, and the uncertainty of fers new functionality . 4 rspa.ro yalsocietypub lishing.org Proc R Soc A 0000000 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . (a) Quadrature W e term the Probabilistic Numeric appr oach to quadrature Bayesian quadrature. Diaconis [ 4 ] may have been first to point out a clear connection between a Gaussian pr ocess regression model and a deterministic quadrature r ule, an observation subsequently generalised by W ahba [ 47 , §8] and O’Hagan [ 34 ], and also noted by Rasmussen & Ghahramani [ 39 ] . Details can be found in these works; here we constr uct an intuitive example highlighting the practical challenges of assigning uncertainty to the result of a computation. For concreteness, consider f ( x ) = exp − sin 2 ( 3 x ) − x 2 (black in Figure 1 , top). Evidently , f has a compact symbolic form and f ( x ) can be computed for virtually any x ∈ R in nanoseconds. It is a wholly deterministic object. Nevertheless, the real number F = 3 − 3 f ( x ) d x (2.1) has no simple analytic value, in the sense that it can not be natively evaluated in low-level code. Quadrature r ules offer “black box” estimates of F . These rules have been optimized so heavily [e.g. 3 ] that they could almost be called “low-level”, but their r esults do not come with the strict error bounds of floating-point operations; instead, assumptions about f are necessary to bound error . Perhaps the simplest quadratur e rule is the trapezoid rule, which amounts to linear interpolation of f (red line in Figur e 1 , top left): Evaluate f ( x i ) on a grid − 3 = x 1 < x 2 < ⋅ ⋅ ⋅ < x N = 3 of N points, and compute ˆ F midpoint = N i = 2 1 2 [ f ( x i ) + f ( x i − 1 )] ( x i − x i − 1 ) . (2.2) (b) Ba yes-Hermite Quadrature A probabilistic description of F requir es a joint probability distribution over f and F . Since f lies in an infinite-dimensional Banach or Hilbert space, no Lebesgue measure can be defined. But Gaussian process measures can be well-defined over such spaces, and offer a powerful framework for quadrature [ 38 , 47 ]. In particular , we may choose to model f on [ − 3 , 3 ] by p ( f ) = G P ( f ; 0 , k ) , a Gaussian process with vanishing mean µ = 0 and the linear spline covariance function [ 29 ] (a stationary variant of the W iener process) k ( x, x ′ ) = c ( 1 + b − 1 3 b x − x ′ ) , for some c, b > 0 . (2.3) More pr ecisely , this assigns a probability measur e over the function values f ( x ) on [ − 3 , 3 ] , such that any restriction to finitely many evaluations y = [ f ( x 1 ) , . . . , f ( x M )] at X = [ x 1 , . . . , x N ] is jointly Gaussian distributed with zero mean and covariance co v f ( x i ) , f ( x j ) = k ( x i , x j ) . Samples drawn from this process ar e shown in grey in the top left of Figur e 1 . These sample paths r epresent the hypothesis class associated with this Gaussian process prior: They are continuous, but not differ entiable, in mean square expectation [ 1 , § 2.2]. Because Gaussian processes ar e closed under linear projections [e.g. 1 , p. 27], this distribution over f is identified with a corr esponding univariate Gaussian distribution [ 29 ], p ( F ) = N F ; 0 , 3 − 3 k ( ˜ x, ˜ x ′ ) d ˜ x d ˜ x ′ = c ( 1 + b 3 ) , (2.4) on F . The strength of this formulation is that it provides a clear framework under which observations f ( x i ) can be incorporated. The measur e on p ( F ) conditioned on the collected function values is another scalar Gaussian distribution p F y = N F ; 3 − 3 k ( ˜ x, X ) K − 1 y d ˜ x, 3 − 3 k ( ˜ x, ˜ x ′ ) − k ( ˜ x, X ) K − 1 k ( X, ˜ x ′ ) d ˜ x d ˜ x ′ , (2.5) where k ( ˜ x, X ) = [ k ( ˜ x, x 1 ) , . . . , k ( ˜ x, x N )] and K is the symmetric positive definite matrix with elements K ij = k ( x i , x j ) . The final expression in the brackets, the posterior covariance can be optimized with respect to X to design a “most informative” dataset. For the spline kernel ( 2.3 ) , this leads to placing X on a regular , equidistant, grid [ 29 ]. 5 rspa.ro yalsocietypub lishing.org Proc R Soc A 0000000 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . − 2 0 2 0 0 . 5 1 x f ( x ) ; p f ( x ) − 2 0 2 x − 2 0 2 x − 2 0 2 x 10 0 10 1 10 2 10 3 10 − 6 10 − 4 10 − 2 10 0 # function evaluations estimation error 10 0 10 1 10 2 10 3 # function evaluations 10 0 10 1 10 2 10 3 # function evaluations 10 0 10 1 10 2 10 3 # function evaluations Figure 1. Quadrature rules, illustrating the challenge of uncer tainty-calibration. Left two columns: T op row: Function f ( x ) (blac k line), is approximately integrated using two different Gaussian process priors (left: linear spline; right: e xponentiated quadratic), giving poster ior distr ibutions and mean estimates. Gra y lines are functions sampled from the pr ior . The thick coloured line is the posterior mean, thin lines are posterior samples, and the delineation of two marginal standard deviations . The shading represents poster ior probability density . Bottom ro w: As the n umber of e valuation points increases, the posterior mean (thick line with points) converges to the tr ue integral value; note the more rapid conv ergence of the exponentiated quadratic pr ior . The poster ior covariance provides an error estimate whose scale is defined b y the poster ior mean alone (each thin coloured line in the plots corresponds to a different instance of such an estimate). But it is only a meaningful error estimate if it is matched w ell to the function’s actual proper ties. The left plot shows systematic diff erence between the conv ergence of the real error and the convergence of the estimated error under the linear spline, whereas conv ergence of the estimated error under the exponentiated quadratic prior is better calibrated to the real error . Grey grid lines in the background, bottom left, correspond to O ( N − 1 ) conv ergence of the error in the number N of function ev aluations. Right two columns: The same experiment repeated with a function f drawn from the spline kernel prior. For this function, the trapezoid rule is the optimal statistical estimator of the integral (note well-calibrated error measure in bottom row , third panel), while the Gaussian kernel GP is strongly over-confident. The spline kernel k of ( 2.3 ) is a piecewise linear function with a single point of non- differ entiability at x = x ′ . The posterior mean k ( ˜ x, X ) K − 1 y is a weighted sum of N such kernels centred on the evaluation points X and constrained by the likelihood to pass through the values y at the nodes X . Thus, the posterior mean is a linear spline interpolant of the evaluations, and the posterior mean of Equation ( 2.5 ) is exactly equal to the trapezoid-rule estimate from X [see also 4 ]. That is, Bayesian quadrature with a linear spline prior provides a probabilistic interpretation of the trapezoidal rule; it supplements the estimate with a full probability distribution characterising uncertainty . The corresponding conditional on f is a Gaussian process whose mean is the piecewise linear red function in the top left of Figure 1 (the Figure also repr esents the conditional distribution p f f ( x 1 ) , . . . , f ( x N ) as a red cloud, and some samples). V arious other , more elaborate quadrature rules (e.g. higher order spline interpolation and Chebyshev polynomials) can be cast probabilistically in analogous ways, simply by changing the covariance function k [ 4 , 34 , 47 ]. 6 rspa.ro yalsocietypub lishing.org Proc R Soc A 0000000 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . (c) Added v alue, and challenge , of probabilistic output A non-probabilistic analysis of the trapezoid-r ule is that, for sufficiently r egular functions f , this rule converges at a rate of at least O ( N − 1 ) to the correct value for F as N increases [e.g. 3 , Eq. 2.1.6] (other quadrature r ules, like cubic splines, have better conver gence for differ entiable functions). Figure 1 bottom left shows the mean estimate (equivalently , the trapezoid-rule) as a thick line. Grey help lines repr esent O ( N − 1 ) convergence. Clearly , the asymptotic behaviour is steeper than those lines. 4 So the theoretical bound is corr ect, but it is also of little practical value: No linear bound is tight from start to conver gence. On the probabilistic side, the standard deviation of the conditional ( 2.5 ) is regularly interpreted as an estimate of the impr ecision of the mean estimate. In fact, this err or estimate (thin red lines in Figure 1 , top left) is analogous to the deterministic linear convergence bound for continuous functions. There is a family of such error bounds associated with the same posterior mean, with each line corresponding to a dif ferent value for the unknown constant in the bound and differ ent values for the parameters b and c in the covariance. 5 It may seem as though the probabilistic interpretation had added nothing new , but since this view identifies quadrature r ules of varying assumptions as parameter choices in Gaussian pr ocess regr ession, it embeds seemingly separate rules in a hierarchical space of models, from which models with good error modelling can be selected by hierarchical probabilistic inference. This can be done without collecting additional data-points [ 38 , §5]. More generally , the probabilistic numeric viewpoint pr ovides a principled way to manage the parameters of numerical procedures. Wher e Markov Chain Monte Carlo procedures might requir e the hand-tuning of parameters such as step sizes and annealing schedules, Bayesian quadrature allows the machinery of statistical infer ence pr ocedure to be brought to bear upon such parameters. A practical example of the benefits of approximate Bayesian infer ence for the (hyper-)parameters of a Bayesian quadrature pr ocedure is given by [ 36 ]. The function f used in this example is much smoother than typical functions under the Gaussian process prior distribution associated with the trapezoid rule (shown as thin grey samples in the top left plot). The second column (using orange) of Figur e 1 shows analogous experiments with the exponentiated quadratic covariance function k ( x, x ′ ) = θ 2 exp ( − ( x − x ′ ) 2 λ 2 ) , corresponding to a very strong smoothness assumption on f [ 45 ] (see grey samples in top right plot), giving a very quickly converging estimate. In this case, the “error bars” provided by the standard deviation converge in a qualitatively comparable way . Of course, the faster convergence of this quadrature rule based on the exponentiated quadratic- covariance prior is not a universal property . It is the effect of a much stronger set of prior assumptions. If the true integrand is rougher than expected under this prior , the quadrature estimate arising from this prior can be quite wrong. The right two columns of Figure 1 show analogous experiments on an integrand that is a true sample from a Gaussian process with the spline covariance ( 2.3 ) . In this case, the spline prior is the optimal statistical estimator by construction, and its error estimate is perfectly calibrated (third column of Figure 1 ), while the exponentiated quadratic-kernel gives over -confident, and inef ficient estimates (right-most column). Identifying the optimal regr ession model from a larger class, just based on the collected function values, requir es more computational work than to fix a regr essor from the start. But it also gives better calibrated uncertainty . Contemporary general-purpose quadrature implementations [e.g. 3 ] remain lightweight by recursively re-using previous computations. The above experiments show that it is possible to design Bayesian quadrature rules with well-calibrated posterior error estimates, but it r emains a question how small the computational over head from a probabilistic computation over these methods can be made. Even so, formulating quadrature as pr obabilistic regr ession precisely captur es a trade-off between prior assumptions inher ent in a computation and 4 This, too, is a well-known result: If the integrand is differentiable, rather than just continuous, the trapezoid rule has quadratic convergence rate [ 3 , Eq. 2.1.12]. 5 The initial behaviour of the red lines in the figure is a function of the scale b , which relates to assumptions about the rate at which the asymptotic quadratic convergence is appr oached. 7 rspa.ro yalsocietypub lishing.org Proc R Soc A 0000000 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . the computational ef fort r equired in that computation to achieve a certain precision. Computational rules arising from a strongly constrained hypothesis class can perform much better than less restrictive rules if the prior assumptions are valid . In the numerical setting—in contrast to many empirical situations in statistics—it is often possible to precisely check whether a particular prior assumption is valid: The machine performing the computation has access, at least in principle, to a formal, complete, description of its task, in form of the sour ce code describing the task (the integrand, the optimization objective, etc.). Using this source code, it is for example to test, at runtime, whether , and how many times, an integrand is continuously differentiable [e.g. 8 ]. Using this information will in futur e allow the design of impr oved quadrature methods. Once one knows that general purpose quadrature methods effectively use a Gaussian process prior over function values, it is natural to ask whether this prior actually incorporates the salient information available for one’s specific problem. Including such information in the prior leads to customized, “tailored”, numerical methods that can perform better . Probabilistic infer ence also furnishes the framework required to tackle numerics tasks using decision theory . For quadrature, the decision problem to be solved is that of node selection: that is, the determination of the optimal positions for points (or nodes) at which to evaluate the integrand. W ith the definition of an appropriate loss function, such as the posterior variance of the integral, such nodes can be optimally selected by minimising the expected loss function. It seems clear that this approach can improve upon the simple uniform grids of many traditional quadrature methods, and can enable active learning: where surprising evaluations can influence the selection of future nodes. This decision-theoretic appr oach stands in contrast with that adopted by randomised, Monte Carlo, approaches to quadrature. Such approaches generate nodes with the use of a pseudo-random number generator , injecting additional epistemic uncertainty (about the value of the generator ’s outputs) into a procedure designed to reduce the uncertainty in an integral. It is worth noting that the use of pseudo-random generators burdens the pr ocedure with additional computational overhead: pseudo-random numbers ar e cheap, but not free. The principal feature of Monte Carlo approaches is their conservative nature: the Monte Carlo policy will always, eventually , take an additional node arbitrarily close to an existing node. The disadvantage of this strategy is its waste of valuable evaluations: the convergence rate of Monte Carlo techniques, O ( N − 1 2 ) , is clearly improved upon by both traditional quadrature and Bayesian quadrature methods. This pr oblem is only worsened by the common discarding of evaluations known as ‘burn-in’ and ‘thinning’. The advantage of Monte Carlo, of course, is its robustness to even highly non-smooth integrands. However , Bayesian quadrature can realise more value from evaluations by exploiting known structure (e.g. smoothness) in the integrand. (d) Empirical ev aluation of Bay esian quadrature f or astrometr y W e illustrate this on an integration problem drawn from astrometry , the measurement of the motion of stars. In order to validate astrometric analysis, we aim to recover the number of planets present in synthetic data generated (with a known number of planets) to mimic that produced by an astrometric facility such as the GAIA satellite [ 43 ]. 6 Here, quadratur e’s task is to compute the model evidence (marginal likelihoo d) Z = ∫ p ( D θ , M ) p ( θ M ) d θ of a model M for orbital motions, where D are the gathered observations and θ are the model parameters. Specifically , it is of interest to compar e the evidence for models including differing numbers of exoplanets. For the following example, to pr ovide a focal problem upon which to compar e quadrature methods, we compute the evidence of a model with two such planets on data generated with a two-planet model. The corresponding integral is analytically intractable, with a multi-modal integrand (the likelihood p ( D θ , M ) ) and a 19-dimensional θ rendering the quadrature pr oblem challenging. As the probabilistic method, we use a recent algorithm: W arped, Sequential, Active Bayesian Integration (WSABI 7 ) [ 9 ]. WSABI is a Bayesian quadrature algorithm that uses an internal 6 The authors are grateful to H. Parviainen and S. Aigrain for pr oviding data and code examples. 7 Matlab code for WSABI is available at https://github.com/OxfordML/wsabi . 8 rspa.ro yalsocietypub lishing.org Proc R Soc A 0000000 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10 − 2 10 − 1 10 0 10 1 10 2 10 3 0 20 40 T ime in seconds log log Z pred − log Z true WSABI SMC AIS BMC Figure 2. W e compare different quadrature methods in computing the 19-dimensional integral giving model evidence in an astrometr y application. The Bay esian quadrature algorithm (WSABI) that employs active selection of nodes, along with pr ior knowledge of the smoothness and non-negativity of the integrand, converges faster than the Monte Carlo approaches: simple Monte Carlo (SMC) and Annealed Impor tance Sampling (AIS). Note that Bay esian Monte Car lo (BMC) is a Bayesian quadrature algorithm that uses the same samples as SMC, explaining their similar performance. Note also the performance improv ement offered by WSABI ov er BMC, suggesting the crucial role play ed by the active selection of nodes. probabilistic model that is well-calibrated to the suspected pr operties of the problem’s integrand. Firstly , like the exponentiated quadratic, WSABI’s covariance function is suitable for smooth integrands, as are expected for the problem. Secondly , and beyond what is achievable with classic quadrature rules, WSABI explicitly encodes the fact that the integrand (the likelihood p ( D θ , M ) ) is strictly positive. WSABI also makes use of a further opportunity af forded by the pr obabilistic numeric approach: it actively select nodes so as to minimise the uncertainty in the integral. This final contribution permits nodes to be selected that are far more informative than gridded or randomly selected evaluations. W e compare this algorithm against two different Monte Carlo approaches to the pr oblem: Annealed Importance Sampling (AIS) [ 31 ] (which was implemented with a Metropolis–Hastings sampler) and simple Monte Carlo (SMC). W e additionally compared against Bayesian Monte Carlo (BMC) [ 39 ], a Bayesian quadrature algorithm using the simpler exponentiated quadratic model, and whose nodes were taken fr om the same samples selected by SMC. “Ground truth” ( Z true ) was obtained through exhaustive SMC sampling ( 10 6 samples). The results in Figure 2 show that the probabilistic quadrature method achieves improved precision drastically faster than the Monte Carlo estimates. It is important to point out that the plot’s abscissa is “wall-clock” time, not algorithmic steps. Probabilistic algorithms need not be expensive. (e) Linear Algebra Computational linear algebra covers various operations on matrices. W e will here focus on linear optimization, where b ∈ R N is known and the task is to find x ∈ R N such that A x = b where A ∈ R N × N is symmetric positive definite. W e assume access to projections A s for arbitrary s ∈ R N . If N is too large for exact inversion of A , a widely known approach is the method of conjugate gradients (CG) [ 17 ], which pr oduces a convergent sequence x 0 , . . . , x M of improving estimates for x . Each iteration involves one matrix-vector multiplication and a small number of linear operations, to produce the update s i = x i − x i − 1 , and an “observation” y i = A s i . CG’s good performance has been analysed extensively [e.g. 32 , §5.1]. W e will use the shorthands S M = [ s 1 , . . . , x M ] and Y M = [ y 1 , . . . , y M ] for the set of projection directions and “observations” after M iterations of the method. Defining a probabilistic numerical algorithm requir es a joint probability measure p ( Y M , A, b , x S M ) over all involved variables, conditioned on the algorithm’s active design decisions; and an “action rule” (design, policy , control law) describing how the algorithm should collect data. Recent work by Hennig [ 14 ] describes such a model which exactly repr oduces the sequence { x i } i = 1 ,...,M ≤ N of CG: As prior , choose a 9 rspa.ro yalsocietypub lishing.org Proc R Soc A 0000000 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Gaussian measure over the (assumed to exist) inverse H = A − 1 of A p ( H ) = N ( Ð → H ; Ð → H 0 , Γ ( W ⊗ W ) Γ ⊺ ) . (2.6) This implies a Gaussian prior over x = H b , and a non-Gaussian prior over A . In ( 2.6 ), N is a Gaussian distribution over the N 2 elements of H stacked into a vector Ð → H . Γ is the symmetrization operator ( Γ Ð → A = 1 2 ( Ð Ð Ð Ð → A + A ⊺ )) , and ⊗ is the Kronecker product ( Γ ( W ⊗ W ) Γ ⊺ is also known as the symmetric Kronecker pr oduct [ 46 ]). As projections ar e presumed noise-fr ee, the likelihood is the Dirac distribution, the limit of a Gaussian with vanishing width, which can also be seen as performing a strict conditioning of the prior on the observed function values, p ( Y M A, b , x , S M ) = i δ ( A s i − y i ) = i δ ( s i − H y i ) . (2.7) The action rule at iteration i is to move to x i + 1 = x i − α ˆ H i ( A x i − b ) , where ˆ H i is the posterior mean p ( H Y M ) . The optimal step α can be computed exactly in a linear computation. Eq. ( 2.6 ) requires choices for Ð → H 0 and W . The prior mean is set to unit, Ð → H 0 = I . If W ∈ R N × N is positive definite, then p ( H ) assigns finite measure to every symmetric H ∈ R N × N , and the algorithm converges to the tr ue x in at most N steps, assuming exact computations [ 14 ]. In this sense it is non-restrictive, but of course some matrices are assigned more density than others. If W is set to a value among the set { W ∈ R N × N W symm. positive definite and W Y M = σ S M , σ ∈ R + } (this includes the true matrix W = H , but does not r equire access to it), then the resulting algorithm exactly repr oduces the iteration sequence { x i } i = 0 ,...,N of the CG method, and can be implemented in the exact same way . However , this derivation also provides something new: A Gaussian posterior distribution p ( H y ) = N ( H ; H M , Γ ( W M ⊗ W M ) Γ ⊺ ) over H . Details can be found in [ 14 ], for the present discussion it suf fices to know that both the posterior mean H M and covariance parameter W M are of manageable form. In particular , H M = I + U E U ⊺ with a diagonal matrix E ∈ R 2 M × 2 M and “skinny” matrices U ∈ R N × 2 M , which are a function of the steps s and observed projections y . So, as in the case of quadrature, there is a family of Gaussian priors of varying width (scaled by σ ), such that all members of the family give the same posterior mean estimate. And this posterior mean estimate is identical to a classic numerical method (CG). But each member of the family gives a differ ent posterior covariance—a differ ent uncertainty estimate. It is an interesting question to which degree the uncertainty parameter W M can be designed to give a meaningful error estimate. Some answers can be found in [ 14 ]. Inter estingly , the equivalence- class of prior covariances W 0 that match CG in the mean estimate has mor e degrees of freedom than the number M of observations (matrix-vector multiplications) collected by the algorithm during its typical runtime. Fitting the posterior uncertainty W M thus requires strong regularization. The method advocated in [ 14 ] constructs such a regularized estimator exclusively from scalar numbers alr eady collected during the run of the CG method, thus keeping computational overhead very small. But, as in quadrature, ther e are valuable applications for the probabilistic formulation that do not strictly require a well-calibrated width of the posterior . Applications that make primary use of the posterior mean may just requir e algebraic structure in the prior , up to an arbitrary scaling constant, to incorporate available, helpful, information. W e will not do this here and instead highlight another use of probabilities over point estimates: the pr opagation of knowledge from one linear problem to another r elated problem. The approach described in the following is known in the numerical linear algebra community as the r ecycling of Krylov sequences [ 37 ]. However , while the framework of classic numerical analysis requir ed challenging and bespoke derivation of this result, it follows naturally in the probabilistic viewpoint as the extension of a parametric regressor to a filter on a time-varying process. The probabilistic formulation of computation uses the universal and unique language of inference to enable the solution of similar pr oblems across the br eadth of numerics using similar techniques. This is in contrast to the compartmentalised state of current numerics, which demands distinct expert knowledge of each individual numeric problem in order to make progr ess towards it. 10 rspa.ro yalsocietypub lishing.org Proc R Soc A 0000000 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Further , there is social value in making results accessible to any practitioner with a graduate knowledge of statistics. In many set-ups, the same A features in a sequence of problems A x t = b t , t = 1 , . . . . In others, a map A t changes slightly from step t to step t + 1 . Figure 3 describes a blind deconvolution problem from astronomical imaging: 8 The task is to remove an unknown linear blur from a sequence y 1 , . . . , y K of astronomical images [ 12 ]. Atmospherical disturbances cr eate a blur that continuously varies over time. The model is that each frame y i is the noisy result of convolution of the same ground truth image x with a spatially varying blur kernel f i , i.e. y i = f i ∗ x + n i , where n i is white Gaussian noise. A matrix X encodes the convolution operation as y i = X f i + n i (it is possible to ensure X is positive definite). A blind deconvolution algorithm iterates between estimating X and estimating the f i [ 12 ]. Each iteration thus requir es the solution of K linear problems (with fixed X ) to find the f i , then one larger linear problem to find x . The naïve approach of running separate instances of CG wastes information, because the K linear problems all share the matrix X , and from one iteration to the next, the matrix X changes less and less as the iterations approach convergence. Instead, information can be propagated between related computations using the probabilistic interpretation of CG, by starting each computation in the sequence with a prior mean H 0 set to the posterior mean H M of the pr eceding problem. Due to the low-rank structure of H M , this has low cost. T o prevent a continued rise in computational costs as more and mor e linear problems are solved, H M can be restricted to a fixed rank approximation after each inner loop, also at low cost. The plots in the lower half of Figure 3 show the incr ease in computational ef ficiency: For the baseline of solving 40 linear problems independently in sequence, each converges about equally fast (top plot, each “jump” is the start of a new problem). The lower plot shows optimization progr ess of the same 40 problems when information is propagated fr om one problem to the next. The first problem amounts to standard CG, while subsequent iterations can make increasingly better use of the available information. The Figure also shows the dominant eigenvectors of the inferred posterior means of X − 1 after K = 40 subsequent linear pr oblems, which converge to a r elatively generic basis for point-spread functions. Although not strictly correct, this scheme can be intuitively understood as inferring a pre-conditioner across the sequence of problems, by Bayesian filtering (the technical caveat is that the described scheme does not re-scale the linear problem itself, as a pr e-conditioner would, it just shifts the initial solution estimate). (i) Fur ther Areas These examples highlight the ar eas of quadrature and linear algebra. Analogous results, identifying existing numerical methods with maximum a-posteriori estimators have been established in other areas, too. W e do not experiment with them here, but they help complete the picture of numerical methods as inference acr oss problem boundaries: In non-linear optimization, quasi-Newton methods like the BFGS rule are deeply connected to conjugate gradients (in linear problems, BFGS and CG ar e the same algorithm [ 30 ]). The BFGS algorithm can be interpreted as a specific kind of autor egressive generalization of the Gaussian model for conjugate gradients [ 16 ]. Among other things, this allows explicit modelling of noise on evaluated gradients, a pressing issue in lar ge-scale machine learning [ 13 ]. One currently particularly exciting area for probabilistic numerics is ordinary differential equations, more specifically the solution of initial value problems (IVPs) of the form d x dt ( t ) = f ( x ( t ) , t ) , where x ∶ R + _ R N is a real-valued curve parametrised by t known to start at the initial value x ( t 0 ) = x 0 . Explicit Runge-Kutta methods ar e a basic and well-studied tool for such pr oblems [ 10 ]—while not necessarily state of the art, they nevertheless perform well on many problems, and are conceptually very clear . From the inference perspective, Runge-Kutta methods ar e linear extrapolation rules. At incr easing nodes t 0 < t 1 < ⋅ ⋅ ⋅ < t i < t s they repeatedly constr uct “estimates” ˆ x ( t i ) ≈ x ( t i ) for the true solution which is used to collect an “observation” y i = f ˆ x ( t i ) , t i , such 8 The authors thank S. Harmeling, M. Hirsch, S. Sra and B. Schölkopf [ 12 ] for providing data. 11 rspa.ro yalsocietypub lishing.org Proc R Soc A 0000000 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . observed images estimated point-spread functions y 1 y 2 y 3 y 4 f 1 f 2 f 3 f 4 x estimated ground truth ∗ ∗ ∗ ∗ X f i = y i + n i eigen-vectors of inf erred approximation to X − 1 : . . . 0 50 100 150 200 250 300 350 400 10 − 7 10 − 4 10 − 1 # steps residual 0 50 100 150 200 250 300 350 400 10 − 7 10 − 4 10 − 1 residual Figure 3. Solving sequences of linear problems by utilizing the probabilistic inter pretation of conjugate gradients, also known as the recycling of Krylov sequences. T op: A sequence of obser ved astronomical images y i is modelled as the convolution of a stationar y true image x with a time-var ying point-spread function f i (the matr ix X encodes the conv olution with x ). Each individual deconv olution task requires one r un of a linear solv er , here chosen to be the method of conjugate gradients. Bottom plots: If each problem is solved independently , each instance of the solver progresses similarly (top plot. Optimization residuals ov er time. Each “jump” in the residual is the star t of a new frame/deconv olution problem). If the posterior mean implied by the probabilistic inter pretation of the solv er is communicated from one problem to the ne xt, the solvers progress increasingly f aster (bottom plot, note decreasing number of steps for each deconvolution problem, and decrease, by about one order of magnitude, of initial residuals). Middle ro w: Ov er time , the vectors spanning this posterior mean for X − 1 conv erge to a generic basis for point-spread functions. that the estimate is a linear combination of previous observations: ˆ x ( t i ) = x 0 + j < i w ij y j . (2.8) Crucially , the weights w ij are chosen such that, after s evaluations, the estimate has high convergence or der: x ( t s ) − ˆ x ( t s ) = O ( h p ) , with an order p ≤ s (typically , p ≤ 5 ). It is important to point out the central r ole that linear extrapolation, and linear computations more generally , play again here, as they did in the other numerical settings discussed above. It is not an oversimplification to note that numerical methods often amount to efficiently projecting an intractable problem into a tractable linear computation. Since the Gaussian family is closed under all linear operations, it is, per haps, no surprise that Gaussian distributions play a central r ole in probabilistic r e-interpretations of existing numerical methods. In the case of initial value problems, Gaussian process extrapolation was previously suggested by Skilling [ 42 ] as a tool for their solution. 12 rspa.ro yalsocietypub lishing.org Proc R Soc A 0000000 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Starting from scratch, Skilling arrived at a method that shares the linear structure of Eq. ( 2.8 ), but does not have the strong theoretical underpinning of Runge-Kutta methods, in particular , Skilling’s method does not share the high convergence order of Runge-Kutta methods. But the probabilistic formulation allows for novel theoretical analysis of its own [ 2 ], and new kinds of applications, such as the marginalization over posterior uncertainty in subsequent computational steps and finite prior uncertainty over the initial value [ 15 ]. A considerably vaguer but much earlier observation was made, on the side of numerical mathematics, by Nordsieck [ 33 ], who noted that a class of methods he proposed, and which were subsequently captured in a wider nomenclature of ODE solvers, bore a r esemblance to linear electrical filters. These, in turn, are closely connected to Gaussian process r egression thr ough the notion of Markov processes. Recently , Schober et al. [ 40 ] showed that these connections between Gaussian r egression and the solution of IVP’s, hitherto only conceptual, can be made tight. There is a family of Gauss- Markov priors that, used as extrapolation r ules, give posterior Gaussian processes whose mean function exactly matches members of the Runge-Kutta family . (Thanks to its Markov property , the corresponding inference method can be implemented as a signal filter , and thus in linear computational complexity , like Runge-Kutta methods). Hence, as in the other ar eas of numerics, there is now a family of methods that returns the trusted point estimates of an established method, while giving a new posterior uncertainty estimate allowing new functionality . 3. Discussion (a) General Recipe f or Probabilistic Numer ical Algorithms These r ecent r esults, identifying probabilistic formulations for classic numerical methods, highlight a general structure. Consider the problem of approximating the intractable variable z , if the algorithm has the ability to choose ‘inputs’ x = { x i } i = 1 ,... for computations that result in numbers y ( x ) = { y i ( x i )} i = 1 ,... . A blueprint for the definition of probabilistic numerical methods requir es two main ingredients: (i) A generative model p ( z , y ( x )) for all variables involved—that is, a joint probability measure over the intractable quantity to be computed, and the tractable numerical quantities computed in the process of the algorithm. Like all (sufficiently structured) probability measures, this joint measur e can be written as p z , y ( x ) = p ( z ) p y ( x ) z , (3.1) i.e. separated into a prior p ( z ) and a likelihood p y ( x ) z . The prior encodes a hypothesis class over solutions, and assigns a typically non-uniform measure over this class. The likelihood explains how the collected tractable numbers y relate to z . It has the basic role of describing the numerical task. Often, in classic numerical problems, the likelihood is a deterministic conditioning rule, a point measure. (ii) A design , action rule, or policy r , such that x i + 1 = r p z , y ( x ) , x 1 ∶ i , y 1 ∶ i , (3.2) encoding how the algorithm should collect numbers. (Here x 1 ∶ i should be understood as the actions taken in the pr eceding steps 1 to i , and similarly for y 1 ∶ i ). This rule can be simple, for example it could be independent of collected data (regular grids for integration). Or it might have a Markov-type property that the decision at i only depends on k < i previous decisions (for example in ODE solvers). Sometimes, these rules can be shown to be associated with the minimization of some empirical loss function, and thus be given a decision-theoretic motivation. This is for example the case for regular grids in quadrature rules [ 29 ]. 13 rspa.ro yalsocietypub lishing.org Proc R Soc A 0000000 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Problem class integration linear opt. nonlinear opt. ODE IVPs inferred z z = f ; ∫ f ( x ) dx z = A − 1 ; Ax = b z = B = ∇∇ ⊺ f z ′ ( t ) = f ( z ( t ) , t ) classic method Gaussian quad. conjugate gradients BFGS Runge-Kutta p ( z ) G P ( f ; µ, k ) N ( A − 1 ; M , V ) G P ( z ; µ, k ) G P ( z ; µ, k ) p ( y z ) I ( f ( x i ) = y i ) I ( y i = Ax i ) I ( y i = B x i ) I ( y i = z ′ ( t )) decision rule minimize gradient at gradient under evaluate at post. variance est. solution est. Hessian est. solution T able 1. Probabilistic description of sev eral basic numerical problems (shor tened notation for brevity). In quadrature, (symmetric positive definite) linear optimization, non-linear optimization, and the solution of ordinary differential equation initial value problems, classic methods can be cast as maximum a-posteriori estimation under Gaussian priors. In each case, the likelihood function is a strict conditioning, because observations are assumed to be noise-free. Because numerical methods are active (they decide which computations to perform), they require a decision rule. This is often “greedy”: evaluation under the poster ior mean estimate. The exception is integration, which is the only area where the estimated solution of the numerical task is not required to construct the next e valuation. The aforementioned results show that classic, base-case algorithms for several fundamental numerical problems can be cast as maximum a-posteriori inference in specific cases of this description; typically under Gaussian priors, and often under simple action rules, like uniform gridding (in quadrature) or gr eedy extrapolation (in linear algebra, optimization and the solution of ODEs). T able 1 gives a short summary . (b) Current Limitations Numerical methods have undergone centuries of development and analysis. The result is a mature set of algorithms that have been ingrained in the scientific tool-set. By contrast, the probabilistic viewpoint suggested here is an emerging ar ea. Many questions remain unanswered, and many aspects of practical importance are missing: Formal analysis is at an early stage. Efficient and stable implementations are still in development. Convincing use-cases from various scientific disciplines are only beginning to emerge. W e hope that the reader will take these issues as a motivation to contribute, rather than a hold-up. As the use of large scale computation, simulation, and the use of data permeate the quantitative sciences, there is clearly a need for a formal theory of uncertainty in computation. (c) New P aths f or Research In our opinion, the match between probabilistic inference and existing numerical methods lays a firm foundation for the analysis of probabilistic numerical methods. W e see two primary , complementary goals: First, implicit prior assumptions can now be questioned. This could be done in an “aggressive” way , in the hope of finding either algorithms with faster convergence on a smaller set of problems satisfying stronger assumptions (as in the quadrature example of Section (b) ). Conversely , a “conservative” re-definition of prior assumptions might improve robustness at increased computational cost. A particularly important aspect in this regard is the action r ule r . Wherever r is a function of previously collected ‘data’ (known as adaptive design in statistics and active learning in machine learning), a bias can occur . Where the collected data also influence the r esult of future actions (as in ODE solvers), a mor e severe problem, an exploration-exploitation trade-off can arise. Checking for such biases, and potentially correcting them, can increase computational cost. But in some applications that requir e high robustness this ef fort can pay off. Secondly the modelling assumptions, in particular the likelihood, can be extended to incr ease the reach of existing methods to new settings. A first point of interest is the explicit modelling 14 rspa.ro yalsocietypub lishing.org Proc R Soc A 0000000 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . of uncertainty or noise on the evaluations themselves. This generalization, which would be challenging to construct fr om a classical standpoint, is often straightforward once a probabilistic interpretation has been found. It may be as simple as replacing the point-mass likelihood functions in T able 1 with Gaussian distributions. A prominent case of this aspect is the optimization of noisy functions, such as it arises for example in the training of large-scale machine learning architectures from subsets of a lar ge or infinite dataset. Other ideas, like the propagation of knowledge between pr oblems, as in Figure 3 , are just as difficult to motivate and study in a classic formulation, but suggest themselves quite naturally in the probabilistic formulation. There are also practical considerations that shape the research effort. Gaussian distributions play an important role, at least where the inferred quantity is continuous valued. This is not incidental: T o a large degr ee, the point of a numerical method is to turn an intractable computation into a sequence of linear computations. The Gaussian exponential family is closed under linear projections, thus ideally suited for this task. Efficient adaptation of model hyper -parameters is crucial for a well-calibrated posterior measur e. Models with fixed parameters often simply repr oduce existing analytic bounds; only through parameter adaptation can uncertainty be actively “fitted”. Doing so is per haps more challenging than elsewhere in statistics because numerical methods ar e “inner-loop” algorithms used to solve more complex, higher-level computations. It is important to find computationally lightweight parameter estimation methods, perhaps at the cost of accepting some limitations in model flexibility . Although the fundamental insight that numerical methods solve inference problems is not new , the study of probabilistic numerical methods is still young. Recent work has made pr ogress, exposing a wealth of enticing applications in the process. W e conclude this text by highlighting a most promising, if distant, application motivating ongoing r esearch. (d) A Vision: Chained numerical methods communicating uncer tainty Fueled by ubiquitous collection and communication of data, several academic and industrial fields are now interested in systems that use observations to adapt to, and interact with, their data sou rce in an autonomous way . Figure 4 shows a conceptual sketch of an autonomous machine aiming to solve a given task by using observations (data) D to build a probabilistic model p ( x t D , θ t ) of variables x t that describe the envir onment’s dynamics through model parameters θ t . The model can be used to predict future states x t + δ t as a function of actions a t chosen by the machine. The goal is to choose actions that, over time, maximize some measure of utility that encodes the task. This requir es a sequence of numerical steps: Inference on x requir es marginalization and expectations, i.e. integration. Fitting θ involves optimization. Prediction of x t + δ t may entail solving differ ential equations. All three areas have linear base cases (inference in linear regression, optimization of quadratic functions, the solution of linear ODEs). The combination of a sequence of “black-box” numerical methods in such automated set-ups gives rise to new challenges. Each method receives a point estimate from its pr ecursor , performs its local computation (and adds its local error), and hands the r esult on. Errors can accumulate in unexpected ways along this chain, but modelling their accumulation provides value: It may be unnecessary to run a numerical method to convergence if its inputs are alr eady known to be only rough estimates. Specifically , numerical methods allowing for probabilistic inputs and outputs turn the sketch of Figure 4 into a factor graph [ 6 ], and allow propagation of uncertainty estimates along the chain of computation, through message passing [ 26 ]. This would identify sour ces of computational error , allowing: the active management of a computational budget across the chain; the dedication of finite computer resour ces to steps that dominate the overall error; and the truncation of computations early once they r each sufficient precision. Uncertainty propagation through computations has been studied widely before [ 27 , gives a review], but the available algorithms focus on the effects of set-up uncertainties on the outcome of a computation, rather than the computation itself. This new functionality explicitly requires calibrated probabilistic uncertainty at each step of the computation, at runtime . Classic abstract convergence analyses can not be used for this kind of estimation. 15 rspa.ro yalsocietypub lishing.org Proc R Soc A 0000000 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . autonomous system / machine environment perception / learning / inference / system id prediction action D x t θ t x t + δ t a t data variables parameters conditioning by quadrature estimation by optimization prediction by analysis action by control Figure 4. Sketch of an autonomous system, collecting data to build a parametrised model of the environment. Predictions of future states from the model can be used to choose an action strategy . If inter mediate operations are solved by numerical methods, both computational errors and inherent uncer tainty should be propagated across the pipeline to monitor and target computational effort. 4. Conclusion Numerical tasks can be interpr eted as inference pr oblems, giving rise to probabilistic numerical methods. Established algorithms for many tasks can be cast explicitly in this light. Doing so establishes connections between seemingly disparate problems, yields new functionality , and can improve performance on structured problems. T o allow interpretation of the posterior as a statement of uncertainty , care must be taken to ensure well-calibrated priors and models. But even where the uncertainty interpretation is not (yet) rigorously established, the probabilistic formulation already allows for the encoding of prior information about problem structure, including the propagation of collected information among problem instances, leading to improved performance. Many open questions remain for this exciting field. In the long run, probabilistic formulations may allow the propagation of uncertainty through pipelines of computation, and thus the active control of computational ef fort through hierar chical, modular computations. Data accessibility . N/A. The paper has no data, the empirical parts are all illustrative. Conflict of interests. The authors declare to have no conflicting or competing interests. Ethics statement. All three authors contributed content and editing equally . Acknowledgements. The authors would like to express their gratitude to the two anonymous refer ees for several helpful comments. They are also grateful to Catherine Powell, University of Manchester , for pointing out the connection to recycled Krylov sequence methods. Funding statement. PH is funded by the Emmy Noether Programme of the German Resear ch Community (DFG). MAG is funded by an Engineering and Physical Sciences Research Council (EPSRC), EP/J016934/2, Established Career Research Fellowship, a Royal Society W olfson Research Merit A ward, and and EPSRC Programme Grant—Enabling Quantification of Uncertainty for Large Scale Inverse Problems— EP/K034154/1. Ref erences 1 Adler , R. 1981 The Geometry of Random Fields . W iley . 2 Chkrebtii, O., Campbell, D., Girolami, M. & Calderhead, B. 2013 Bayesian uncertainty quantification for differ ential equations. arXiv prePrint 1306.2365 . 3 Davis, P . & Rabinowitz, P . 2007 Methods of numerical integration . Courier Dover . 4 Diaconis, P . 1988 Bayesian numerical analysis. Statistical decision theory and related topics , IV (1), 163–175. 16 rspa.ro yalsocietypub lishing.org Proc R Soc A 0000000 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 Erdös, P . & Kac, M. 1940 The Gaussian law of errors in the theory of additive number theoretic functions. American Journal of Mathematics , pp. 738–742. 6 Frey , B., Kschischang, F ., Loeliger , H.-A. & W iberg, N. 1997 Factor graphs and algorithms. In Proc. 35th Allerton Conf. on Communications, Contr ol, and Computing , pp. 666–680. 7 Gauss, C. 1809 Theoria motus corporum coelestium in sectionibus conicis solem ambientium . Perthes, F . and Besser , I.H. 8 Griewank, A. 2000 Evaluating derivatives: Principles and techniques of algorithmic differentiation . No. 19 in Frontiers in Appl. Math. SIAM. 9 Gunter , T ., Osborne, M. A., Garnett, R., Hennig, P . & Roberts, S. 2014 Sampling for inference in probabilistic models with fast bayesian quadrature. In Advances in neural information processing systems (eds Cortes & Lawrence). 10 Hairer , E., Nörsett, S. & W anner , G. 1987 Solving Ordinary Differential Equations I – Nonstiff Problems . Springer . 11 Halko, N., Martinsson, P .-G. & T ropp, J. 2011 Finding structure with randomness: probabilistic algorithms for constructing approximate matrix decompositions. SIAM review , 53 (2), 217–288. 12 Harmeling, S., Hirsch, M., Sra, S. & Schölkopf, B. 2009 Online blind deconvolution for astronomical imaging. In International conference on computational photography , pp. 1–7. 13 Hennig, P . 2013 Fast pr obabilistic optimization from noisy gradients. In Int. Conf. on Machine Learning . 14 Hennig, P . 2015 Probabilistic interpretation of linear solvers. SIAM J. Optimization , 25 (1), 234–260. 15 Hennig, P . & Hauberg, S. 2014 Probabilistic solutions to differ ential equations and their application to Riemannian statistics. In Artif. int. and statistics , vol. 33. JMLR, W&CP . 16 Hennig, P . & Kiefel, M. 2013 Quasi-Newton methods – a new direction. J. of Machine Learning Research , 14 , 834–865. 17 Hestenes, M. & Stiefel, E. 1952 Methods of conjugate gradients for solving linear systems. Journal of Research of the National Bur eau of Standards , 49 (6), 409–436. 18 Hoerl, A. & Kennard, R. 2000 Ridge regr ession: Biased estimation for nonorthogonal problems. T echnometrics , 42 (1), 80–86. 19 Hutter , M. 2010 Universal artificial intelligence . Springer . 20 Iman, R. L. & Helton, J. C. 1988 An investigation of uncertainty and sensitivity analysis techniques for computer models. Risk analysis , 8 (1), 71–90. 21 Jeffreys, H. 1961 Theory of pr obability . Oxford. 22 Kennedy , M. C. & O’Hagan, A. 2001 Bayesian calibration of computer models. Journal of the Royal Statistical Society: Series B , 63 (3), 425–464. 23 Kiureghian, A. D. & Ditlevsen, O. 2009 Aleatory or epistemic? Does it matter? Structural Safety , 31 (2), 105–112. 24 Knuth, D. & Par do, L. 1976 Analysis of a simple factorization algorithm. Theoretical Computer Science , 3 (3), 321–348. 25 Krige, D. 1951 A statistical approach to some mine valuation and allied problems on the witwatersrand. Ph.D. thesis, University of the W itwatersrand. 26 Lauritzen, S. & Spiegelhalter , D. 1988 Local computations with probabilities on graphical structures and their application to expert systems. J. R. Stat. Soc. , 50 , 157–224. 27 Lee, S. & Chen, W . 2009 A comparative study of uncertainty pr opagation methods for black- box-type problems. Structural and Multidisciplinary Optimization , 37 (3), 239–253. 28 Liberty , E., W oolfe, F ., Martinsson, P .-G., Rokhlin, V . & T ygert, M. 2007 Randomized algorithms for the low-rank approximation of matrices. Proceedings of the National Academy of Sciences , 104 (51), 20 167–20 172. 29 Minka, T . 2000 Deriving quadratur e rules from Gaussian pr ocesses. T ech. rep., Carnegie Mellon U. 30 Nazareth, L. 1979 A r elationship between the BFGS and conjugate gradient algorithms and its implications for new algorithms. SIAM J Numerical Analysis , 16 (5), 794–800. 31 Neal, R. 2001 Annealed importance sampling. Statistics and Computing , 11 (2), 125–139. 32 Nocedal, J. & W right, S. 1999 Numerical Optimization . Springer . 17 rspa.ro yalsocietypub lishing.org Proc R Soc A 0000000 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33 Nordsieck, A. 1962 On numerical integration of ordinary dif ferential equations. Mathematics of Computation , 16 (77), 22–49. 34 O’Hagan, A. 1991 Bayes–Hermite quadrature. Journal of statistical planning and inference , 29 (3), 245–260. 35 O’Hagan, A. 1992 Some Bayesian numerical analysis. Bayesian Statistics , 4 , 345–363. 36 Osborne, M., Duvenaud, D., Garnett, R., Rasmussen, C., Roberts, S. & Ghahramani, Z. 2012 Active Learning of Model Evidence Using Bayesian Quadrature. In Advances in Neural Information Processing Systems (NIPS) , pp. 46–54. 37 Parks, M., de Sturler , E., Mackey , G., Johnson, D. & Maiti, S. 2006 Recycling krylov subspaces for sequences of linear systems. SIAM Journal on Scientific Computing , 28 (5), 1651–1674. 38 Rasmussen, C. & W illiams, C. 2006 Gaussian Processes for Machine Learning . MIT . 39 Rasmussen, C. E. & Ghahramani, Z. 2003 Bayesian Monte Carlo. In Advances in neural information processing systems (eds S. Becker & K. Obermayer), vol. 15. 40 Schober, M., Duvenaud, D. & Hennig, P . 2014 Probabilistic ODE solvers with Runge-Kutta means. In Advances in Neural Information Processing Systems (eds Cortes & Lawr ence). 41 Shental, O., Siegel, P ., W olf, J., Bickson, D. & Dolev , D. 2008 Gaussian belief propagation solver for systems of linear equations. In IEEE International Symposium on Information Theory , pp. 1863–1867. IEEE. 42 Skilling, J. 1991 Bayesian solution of ordinary differ ential equations. Maximum Entropy and Bayesian Methods . 43 Sozzetti, A., Giacobbe, P ., Lattanzi, M., Micela, G., Morbidelli, R. & T inetti, G. 2014 Astrometric detection of giant planets around nearby m dwarfs: the gaia potential. Monthly Notices of the Royal Astronomical Society , 437 (1), 497–509. 44 T ikhonov , A. N. 1943 On the stability of inverse pr oblems. In Dokl. akad. nauk sssr , vol. 39, pp. 195–198. 45 van der V aart, A. & van Zanten, J. 2011 Information rates of nonparametric Gaussian pr ocess methods. Journal of Machine Learning Research , 12 , 2095–2119. 46 van Loan, C. 2000 The ubiquitous Kronecker product. J of Computational and Applied Mathematics , 123 , 85–100. 47 W ahba, G. 1990 Spline models for observational data . No. 59 in CBMS-NSF Regional Conferences series in applied mathematics. SIAM.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment