How to Apply Markov Chains for Modeling Sequential Edit Patterns in Collaborative Ontology-Engineering Projects
With the growing popularity of large-scale collaborative ontology-engineering projects, such as the creation of the 11th revision of the International Classification of Diseases, we need new methods and insights to help project- and community-managers to cope with the constantly growing complexity of such projects. In this paper, we present a novel application of Markov chains to model sequential usage patterns that can be found in the change-logs of collaborative ontology-engineering projects. We provide a detailed presentation of the analysis process, describing all the required steps that are necessary to apply and determine the best fitting Markov chain model. Amongst others, the model and results allow us to identify structural properties and regularities as well as predict future actions based on usage sequences. We are specifically interested in determining the appropriate Markov chain orders which postulate on how many previous actions future ones depend on. To demonstrate the practical usefulness of the extracted Markov chains we conduct sequential pattern analyses on a large-scale collaborative ontology-engineering dataset, the International Classification of Diseases in its 11th revision. To further expand on the usefulness of the presented analysis, we show that the collected sequential patterns provide potentially actionable information for user-interface designers, ontology-engineering tool developers and project-managers to monitor, coordinate and dynamically adapt to the natural development processes that occur when collaboratively engineering an ontology. We hope that presented work will spur a new line of ontology-development tools, evaluation-techniques and new insights, further taking the interactive nature of the collaborative ontology-engineering process into consideration.
💡 Research Summary
The paper presents a novel application of Markov chain modeling to the change‑logs of large‑scale collaborative ontology‑engineering projects, using the development of the 11th revision of the International Classification of Diseases (ICD‑11) as a case study. The authors argue that while collaborative ontology projects have become increasingly important for structuring health data, there is a lack of quantitative methods that capture the sequential nature of user actions during ontology construction and maintenance. To fill this gap, they adopt Markov chains—a well‑established stochastic framework for modeling sequential processes—to uncover regularities, predict future edits, and provide actionable insights for tool designers, interface developers, and project managers.
Data preparation: The authors extracted the complete edit history of ICD‑11, which consists of hundreds of thousands of log entries. Each entry was normalized into a tuple containing the user identifier, timestamp, edit type (e.g., property addition, modification, deletion, concept movement, hierarchical navigation), and the target ontology element. By ordering the logs per user, they built discrete action sequences that reflect how individual contributors move through the ontology and the editing interface.
Modeling pipeline: The core methodological contribution is a step‑by‑step pipeline for fitting Markov chain models of varying order (1‑ to 5‑step memory). For each candidate order, transition probability matrices are estimated from the observed sequences. Model selection is performed using information‑theoretic criteria (AIC, BIC) together with cross‑validation to avoid over‑fitting while maximizing predictive power. The optimal order is identified as the one that balances model complexity and fit to the data.
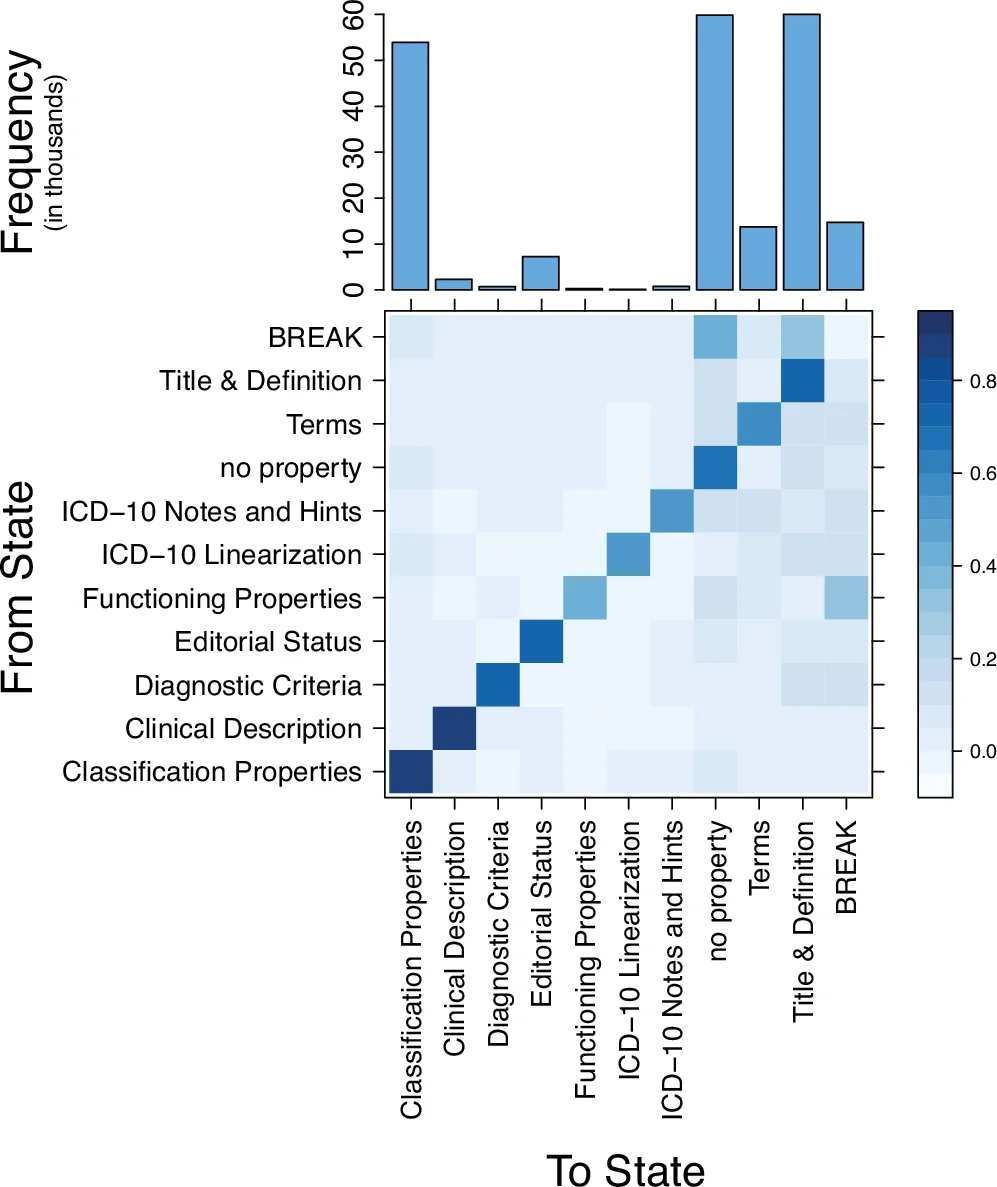
Findings: The empirical analysis shows that most user behavior is best captured by second‑ or third‑order Markov chains, indicating that contributors typically base their next edit on the two or three most recent actions rather than on a single immediate predecessor. Specific transition patterns emerge: (1) users often edit the same concept repeatedly, moving from property modification to addition or deletion; (2) navigation along the ontology hierarchy follows both top‑down and bottom‑up routes, with comparable probabilities; (3) interface sections (e.g., “Definition”, “Terms”, “Causal Properties”) are switched in a cyclic fashion, suggesting a multi‑section workflow rather than a linear one. These patterns are visualized as transition probability matrices, which can be directly incorporated into predictive modules.
Practical implications: By forecasting the most likely next edit, the Markov model enables several concrete enhancements. Editing tools can present context‑aware suggestions, auto‑complete fields, or warnings about potential conflicts before a user commits a change. User‑interface designers can prioritize the most frequently accessed sections, streamline navigation, or dynamically highlight the next probable editing target. Project managers gain a monitoring dashboard that flags deviations from typical transition patterns, allowing early intervention when a contributor’s activity stalls or diverges from expected workflows.
Limitations and future work: The study acknowledges that log data may contain missing or erroneous entries, and that the observed actions do not fully capture user intent (e.g., exploratory vs. purposeful edits). The current approach treats edit types as discrete states, which limits the modeling of continuous attribute changes or more nuanced collaborative dynamics. Future research directions include extending the framework to hidden Markov models or deep‑learning sequence models (LSTM, Transformer) to capture latent states and longer‑range dependencies, as well as applying the methodology to other collaborative ontology platforms such as Wikidata or the OBO Foundry to test generalizability.
Conclusion: The authors demonstrate that Markov chain analysis provides a powerful, interpretable means of extracting structural regularities from collaborative ontology‑engineering logs. Their pipeline not only reveals how users navigate and edit ontologies but also offers a foundation for predictive assistance, interface optimization, and project‑level oversight. By bridging stochastic sequence modeling with ontology‑engineering practice, the paper opens a new avenue for building smarter, more collaborative knowledge‑representation systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment