Training of spiking neural networks based on information theoretic costs
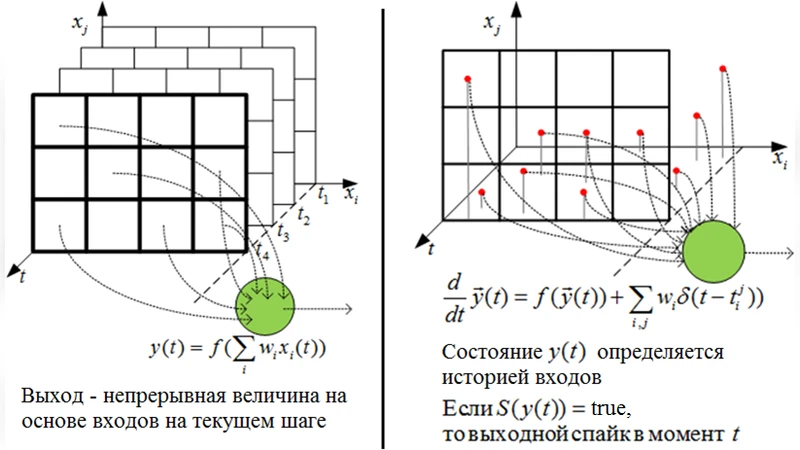
Spiking neural network is a type of artificial neural network in which neurons communicate between each other with spikes. Spikes are identical Boolean events characterized by the time of their arrival. A spiking neuron has internal dynamics and responds to the history of inputs as opposed to the current inputs only. Because of such properties a spiking neural network has rich intrinsic capabilities to process spatiotemporal data. However, because the spikes are discontinuous ‘yes or no’ events, it is not trivial to apply traditional training procedures such as gradient descend to the spiking neurons. In this thesis we propose to use stochastic spiking neuron models in which probability of a spiking output is a continuous function of parameters. We formulate several learning tasks as minimization of certain information-theoretic cost functions that use spiking output probability distributions. We develop a generalized description of the stochastic spiking neuron and a new spiking neuron model that allows to flexibly process rich spatiotemporal data. We formulate and derive learning rules for the following tasks: - a supervised learning task of detecting a spatiotemporal pattern as a minimization of the negative log-likelihood (the surprisal) of the neuron’s output - an unsupervised learning task of increasing the stability of neurons output as a minimization of the entropy - a reinforcement learning task of controlling an agent as a modulated optimization of filtered surprisal of the neuron’s output. We test the derived learning rules in several experiments such as spatiotemporal pattern detection, spatiotemporal data storing and recall with autoassociative memory, combination of supervised and unsupervised learning to speed up the learning process, adaptive control of simple virtual agents in changing environments.
💡 Research Summary
This thesis tackles the fundamental difficulty of training spiking neural networks (SNNs), whose communication is based on discrete “spike” events, by introducing a probabilistic neuron model that renders spike generation a smooth function of its parameters. Because the spiking probability is continuous, standard gradient‑based optimization can be applied to cost functions derived from information theory. Three distinct learning objectives are formulated: (1) supervised pattern detection, where the negative log‑likelihood (surprisal) of the desired spike output is minimized; (2) unsupervised stability enhancement, where the entropy of the output distribution is minimized to make the neuron’s firing more deterministic; and (3) reinforcement learning for agent control, where a filtered surprisal—essentially a temporally discounted negative log‑likelihood weighted by received rewards—is minimized.
The author first develops a generalized stochastic spiking neuron description, extending classic Poisson or Bernoulli models with internal state variables (membrane potential, adaptive threshold) and a history‑dependent filtering mechanism. The firing probability is expressed via a sigmoid‑like mapping of the difference between membrane potential and threshold, allowing analytic gradients with respect to synaptic weights and bias terms.
For supervised learning, the loss L = −log p(y|x) is differentiated, yielding weight updates proportional to the gradient of the log‑probability. This is equivalent to maximum‑likelihood training and leads to rapid convergence on spatiotemporal pattern‑recognition tasks. In the unsupervised case, the entropy H(p) = −∑p log p is minimized; the resulting update pushes the output distribution toward low‑entropy, high‑confidence firing patterns, which stabilizes memory traces in auto‑associative networks. Reinforcement learning introduces a discount factor γ and defines a filtered surprisal L_f = ∑_τ γ^{t−τ}
Comments & Academic Discussion
Loading comments...
Leave a Comment