An End-to-End Neural Network for Polyphonic Piano Music Transcription
We present a supervised neural network model for polyphonic piano music transcription. The architecture of the proposed model is analogous to speech recognition systems and comprises an acoustic model and a music language model. The acoustic model is…
Authors: Siddharth Sigtia, Emmanouil Benetos, Simon Dixon
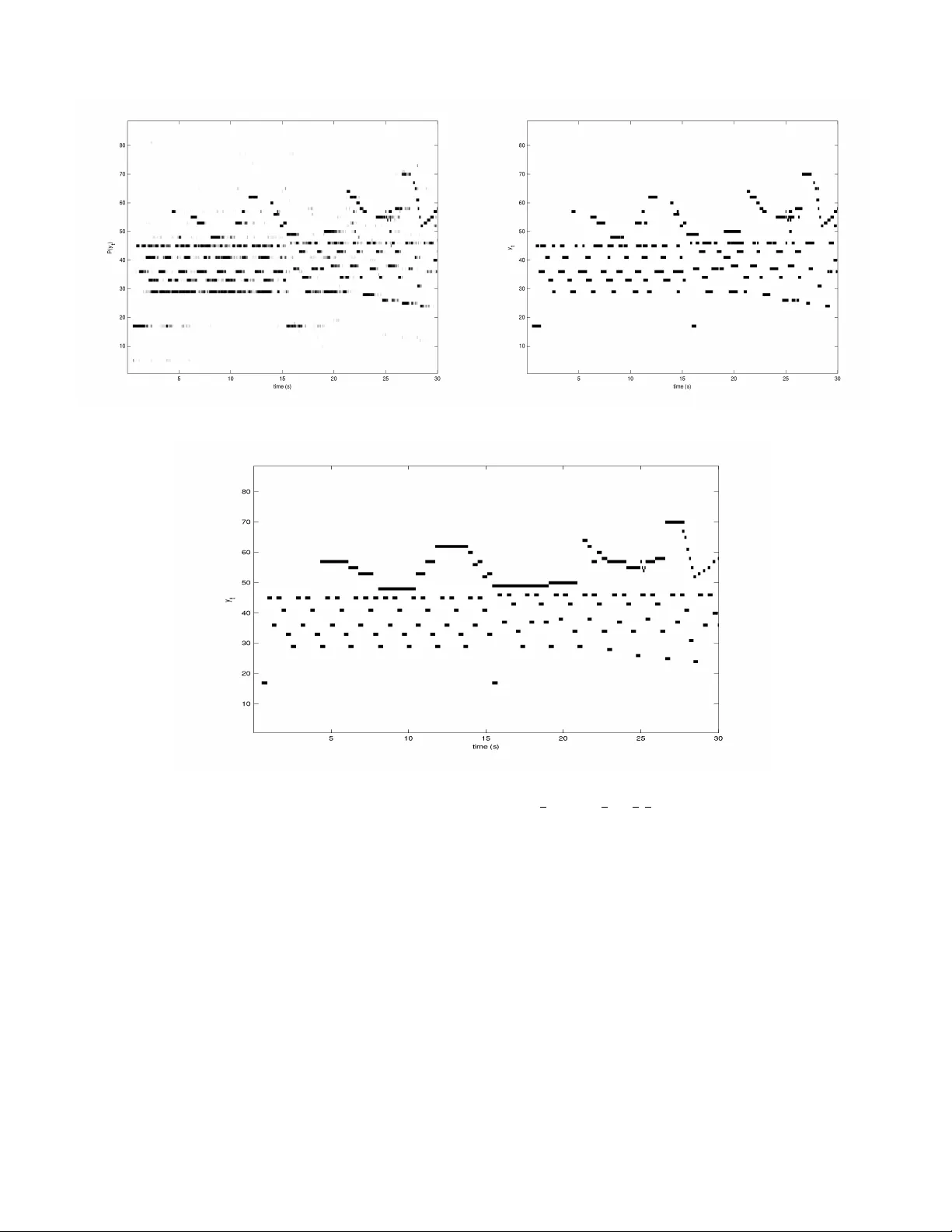
1 An End-to-End Neural Network for Polyphonic Piano Music T ranscription Siddharth Sigtia, Emmanouil Benetos, and Simon Dixon Abstract —W e present a super vised neural network model f or polyphonic piano music transcription. The architectur e of the proposed model is analogous to speech recognition systems and comprises an acoustic model and a music language model . The acoustic model is a neural network used f or estimating the probabilities of pitches in a frame of audio. The language model is a recurr ent neural network that models the correlations between pitch combinations ov er time. The proposed model is general and can be used to transcribe polyphonic music without imposing any constraints on the polyphony . The acoustic and language model pr edictions are combined using a pr obabilistic graphical model. Inference over the output v ariables is performed using the beam search algorithm. W e perform two sets of experiments. W e in vestigate v arious neural network ar chitectures for the acoustic models and also in vestigate the effect of combining acoustic and music language model predictions using the pr oposed architec- ture. W e compare performance of the neural network based acoustic models with two popular unsupervised acoustic models. Results show that convolutional neural network acoustic models yields the best performance across all evaluation metrics. W e also observe improved performance with the application of the music language models. Finally , we present an efficient variant of beam search that improves performance and reduces run- times by an order of magnitude, making the model suitable for real-time applications. Index T erms —A utomatic Music T ranscription, Deep Learning, Recurrent Neural Networks, Music Language Models. EDICS Category: A UD-MSP , A UD-MIR, MLR-DEEP I . I N T RO D U C T I O N A UTOMA TIC Music Transcription (AMT) is a fundamen- tal problem in Music Information Retriev al (MIR). AMT aims to generate a symbolic, score-like transcription, giv en a polyphonic acoustic signal. Music transcription is considered to be a dif ficult problem e ven by human experts and current music transcription systems fail to match human performance [1]. Polyphonic AMT is a difficult problem because concur- rently sounding notes from one or more instruments cause a complex interaction and ov erlap of harmonics in the acoustic signal. V ariability in the input signal also depends on the specific type of instrument being used. Additionally , AMT systems with unconstrained polyphony have a combinatori- ally very large output space, which further complicates the modeling problem. T ypically , variability in the input signal is captured by models that aim to learn the timbral properties The authors are with the Centre for Digital Music, School of Electronic Engineering and Computer Science, Queen Mary University of London, E1 4NS, London, U.K. EB is supported by a Royal Academy of Engineering Research Fellowship (grant no. RF/128). Email: { s.s.sigtia,emmanouil.benetos,s.e.dixon } @qmul.ac.uk of the instrument being transcribed [2], [3], while the issues relating to a large output space are dealt with by constraining the models to have a maximum polyphon y [4], [5]. The majority of current AMT systems are based on the principle of describing the input magnitude spectrogram as a weighted combination of basis spectra corresponding to pitches. The basis spectra can be estimated by v arious tech- niques such as non-negati ve matrix factorisation (NMF) and sparse decomposition. Unsupervised NMF approaches [6], [7] aim to learn a dictionary of pitch spectra from the training examples. Howe ver purely unsupervised approaches can often lead to bases that do not correspond to musical pitches, therefore causing issues with interpreting the results at test time. These issues with unsupervised spectrogram factorisation methods are addressed by incorporating harmonic constraints in the training algorithm [8], [9]. Spectrogram factorisation based techniques were extended with the introduction of probabilistic latent component analysis (PLCA) [10]. PLCA aims to fit a latent variable probabilistic model to normalised spectrograms. PLCA based models are easy to train with the expectation-maximisation (EM) algorithm and hav e been extended and applied extensi vely to AMT problems [11], [3]. As an alternativ e to spectrogram factorisation techniques, there has been considerable interest in discriminativ e ap- proaches to AMT . Discriminati ve approaches aim to directly classify features extracted from frames of audio to the output pitches. This approach has the advantage that instead of constructing instrument specific generative models, complex classifiers can be trained using large amounts of training data to capture the variability in the inputs. When using discriminativ e approaches, the performance of the classifiers is dependent on the features extracted from the signal. Recently , neural networks hav e been applied to raw data or low lev el representations to jointly learn the features and classifiers for a task [12]. Ov er the years there have been many experiments that ev aluate discriminative approaches for AMT . Poliner and Ellis [13] use support vector machines (SVMs) to classify normalised magnitude spectra. Nam et. al. [14] superimpose an SVM on top of a deep belief network (DBN) in order to learn the features for an AMT task. Similarly , a bi-directional recurrent neural network (RNN) is applied to magnitude spectrograms for polyphonic transcription in [15]. In large vocabulary speech recognition systems, the infor - mation contained in the acoustic signal alone is often not sufficient to resolve ambiguities between possible outputs. A language model is used to provide a prior probability of the current word gi ven the pre vious words in a sentence. Statistical language models are essential for large vocabulary speech 2 recognition [16]. Similarly to speech, musical sequences ex- hibit temporal structure. In addition to an accurate acoustic model, a model that captures the temporal structure of music or a music language model (MLM), can potentially help improv e the performance of AMT systems. Unlike speech, language models are not common in most AMT models due to the challenging problem of modelling the combinatorially large output space of polyphonic music. T ypically , the outputs of the acoustic models are processed by pitch specific, two-state hidden Markov models (HMMs) that enforce smoothing and duration constraints on the output pitches [3], [13]. Howe ver , extending this to modelling the high-dimensional outputs of a polyphonic AMT system has proved to be challenging, although there are some studies that explore this idea. A dynamic Bayesian network is used in [17], to estimate prior probabilities of note combinations in an NMF based transcrip- tion framew ork. Similarly in [18], a recurrent neural network (RNN) based MLM is used to estimate prior probabilities of note sequences, alongside a PLCA acoustic model. A sequence transduction frame work is proposed in [19], where the acoustic and language models are combined in a single RNN. The ideas presented in this paper are extensions of the preliminary experiments in [20]. W e propose an end-to-end architecture for jointly training both the acoustic and the lan- guage models for an AMT task. W e ev aluate the performance of the proposed model on a dataset of polyphonic piano music. W e train neural netw ork acoustic models to identify the pitches in a frame of audio. The discriminativ e classifiers can in theory be trained on complex mixtures of instrument sources, without having to account for each instrument separately . The neural network classifiers can be directly applied to the time-frequency representation, eliminating the need for a separate feature extraction stage. In addition to the deep feed-forward neural network (DNN) and RNN architectures in [20], we explore using con volutional neural nets (Con- vNets) as acoustic models. Con vNets were initially proposed as classifiers for object recognition in computer vision, but hav e found increasing application in speech recognition [21], [22]. Although Con vNets hav e been applied to some problems in MIR [23], [24], they remain unexplored for transcription tasks. W e also include comparisons with two state-of-the- art spectrogram factorisation based acoustic models [3], [8] that are popular in AMT literature. As mentioned before, the high dimensional outputs of the acoustic model pose a challenging problem for language modelling. W e propose using RNNs as an alternativ e to state space models like factorial HMMs [25] and dynamic Bayesian networks [17], for modeling the temporal structure of notes in music. RNN based language models were first used alongside a PLCA acoustic model in [18]. Ho wever , in that setup, the language model is used to iterativ ely refine the predictions in a feedback loop resulting in a non-causal and theoretically unsatisfactory model. In the hybrid framew ork, appr oximate inference over the output variables is performed using beam search. Howe ver beam search can be computationally expensi ve when used to decode long temporal sequences. W e apply the efficient hashed beam search algorithm proposed in [26] for inference. The new inference algorithm reduces decoding time by an order of magnitude and makes the proposed model suitable for real-time applications. Our results show that con volutional neural network acoustic models outperform the remaining acoustic models over a number of ev aluation metrics. W e also observe improved performance with the application of the music language models. The rest of the paper is organised as follo ws: Section II describes the neural network models used in the e xperiment, Section III discusses the proposed model and the inference al- gorithm, Section IV details model ev aluation and experimental results. Discussion, future work and conclusions are presented in Section V. I I . B A C K G RO U N D In this section we describe the neural network models used for the acoustic and language modelling. Although neural networks are an old concept, the y hav e recently been applied to a wide range of machine learning problems with great success [12]. One of the primary reasons for their recent success has been the av ailability of large datasets and large- scale computing infrastructure [27], which makes it feasible to train networks with millions of parameters. The parameters of any neural network architecture are typically estimated with numerical optimisation techniques. Once a suitable cost func- tion has been defined, the derivati ves of the cost with respect to the model parameters are found using the backpropagation algorithm [28] and parameters are updated using stochastic gradient descent (SGD) [29]. SGD has the useful property that the model parameters are iteratively updated using small batches of data. This allows the training algorithm to scale to very large datasets. The layered, hierarchical structure of neural nets makes end-to-end training possible, which implies that the network can be trained to predict outputs from lo w- lev el inputs without extracting features. This is in contrast to many other machine learning models whose performance is dependent on the features extracted from the data. Their ability to jointly learn feature transformations and classifiers makes neural networks particularly well suited to problems in MIR [30]. A. Acoustic Models 1) Deep Neural Networks : DNNs are powerful machine learning models that can be used for classification and regres- sion tasks. DNNs are characterised by having one or more layers of non-linear transformations. Formally , one layer of a DNN performs the following transformation: h l +1 = f ( W l h l + b l ) . (1) In Equation 1, W l , b l are the weight matrix and bias for layer l , 0 ≤ l ≤ L and f is some non-linear function that is applied element-wise. For the first layer , h 0 = x , where x is the input. In all our experiments, we fix f to be the sigmoid function ( f ( x ) = 1 1+ e − x ). The output of the final layer h L is transformed according to the giv en problem to yield a posterior probability distribution ov er the output variables P ( y | x, θ ) . The parameters θ = { W l , b l } L 0 , 3 (a) DNN (b) RNN (c) Con vNet Fig. 1. Neural network architectures for acoustic modelling. are numerically estimated with the backpropagation algorithm and SGD. Figure 1a shows a graphical representation of the DNN architecture, the dashed arro ws represent intermediate hidden layers. For acoustic modelling, the input to the DNN is a frame of features, for example a magnitude spectrogram or the constant Q transform (CQT) and the DNN is trained to predict the probability of pitches present in the frame p ( y t | x t ) at some time t . 2) Recurrent Neural Networks : DNNs are good classi- fiers for stationary data, like images. Ho wever , they are not designed to account for sequential data. RNNs are natural extensions of DNNs, designed to handle sequential or temporal data. This makes them more suited for AMT tasks, since con- secutiv e frames of audio exhibit both short-term and long-term temporal patterns [31]. RNNs are characterised by recursive connections between the hidden layer acti vations at some time t and the hidden layer acti v ations at t − 1 , as sho wn in Figure 1b. Formally , the hidden layer of an RNN at time t performs the following computation: h t l +1 = f ( W f l h t l + W r l h t − 1 l + b l ) . (2) In Equation 2, W f l is the weight matrix from the input to the hidden units, W r l is the weight matrix for the recurrent connection and b l are the biases for layer l . From Equation 2, we can see that the recursive update of the hidden state at time t , implies that h t is implicitly a function of all the inputs till time t , x t 0 . Similar to DNNs, RNNs are made up of one or more layers of hidden units. The outputs of the final layer are transformed with a suitable function to yield the desired distribution ov er the ouputs. The RNN parameters θ = n W f l , W r l , b l o L 0 are calculated using the back propagation through time algorithm (BPTT) [32] and SGD. For acoustic modelling, the RNN acts on a sequence of input features to yield a probability distribution over the outputs P ( y t | x t 0 ) , where x t 0 = { x 0 , x 1 , . . . , x t } . 3) Conv olutional Networks : Con vNets are neural nets with a unique structure. Con volutional layers are specifically de- signed to preserve the spatial structure of the inputs. In a con volutional layer , a set of weights act on a local region of the input. These weights are then repeatedly applied to the entire input to produce a featur e map . Conv olutional layers are characterised by the sharing of weights across the entire input. As sho wn in Figure 1c, Con vNets are comprised of alternating con volutional and pooling layers, follo wed by one or more fully connected layers (same as DNNs). Formally , the repeated application of the shared weights to the input signal constitutes a con volution operation: h j,k = f ( X r W r,j x r + k − 1 + b j ) . (3) The input x is a vector of inputs from different channels, for example RGB channels for images. Formally , x = { x 0 , x 1 , . . . } , where each input x i represents an input channel. Each input band x i has an associated weight matrix. All the weights of a con volutional layer are collectively represented as a four dimensional tensor . Giv en an m × n re gion from a feature map h , the max pooling function returns the maximum activ ation in the region. At an y time t , the input to the Con vNet is a windo w of 2 k + 1 feature frames x t + k t − k . The outputs of the final layer yield the posterior distribution distribution P ( y t | x t + k t − k ) . There are se veral motiv ations for using Con vNets for acoustic modelling. There are man y experiments in MIR that suggest that rather than classifying a single frame of input, better prediction accuracies can be achiev ed by incorporating information over several frames of inputs [26], [33], [34]. T ypically , this is achiev ed either by applying a context window around the input frame or by aggregating information over time by calculating statistical moments over a window of frames. Applying a context window around a frame of low lev el spectral features, like the short time fourier transform (STFT) would lead to a very high dimensional input, which is impractical. Secondly , taking mean, standard deviation or other statistical moments makes very simplistic assumptions about the distribution of data ov er time in neighbouring frames. Con vNets, due to their architecture [12], can be directly applied to sev eral frames of inputs to learn features along 4 both, the time and the frequency axes. Additionally , when using an input representation like the CQT , Con vNets can learn pitch-inv ariant features, since inter-harmonic spacings in music signals are constant across log-frequency . Finally , the weight sharing and pooling architecture leads to a reduction in the number of Con vNet parameters, compared to a fully connected DNN. This is a useful property giv en that very large quantities of labelled data are difficult to obtain for most MIR problems, including AMT . B. Music Languag e Models Giv en a sequence y = y t 0 , we use the MLM to define a prior probability distrib ution P ( y ) . y t is a high-dimensional binary vector that represents the notes being played at t (one time-step of a piano-roll representation). The high dimensional nature of the output space makes modelling y t a challenging prob- lem. Most post-processing algorithms make the simplifying assumption that all the pitches are independent and model their temporal evolution with independent models [13]. Howe ver , for polyphonic music, the pitches that are acti ve concurrently are highly correlated (harmonies, chords). In this section, we describe the RNN music language models first introduced in [35]. 1) Generative RNN : The RNNs defined in the earlier sections were used to map a sequence of inputs x to a sequence of outputs y . At each time-step t , the RNN outputs the conditional distribution P ( y t | x t 0 ) . Howe ver RNNs can be used to define a distribution ov er some sequence y by connecting the outputs of the RNN at t − 1 to the inputs of the RNN at t , resulting in a distribution of the form: P ( y ) = P ( y 0 ) Y t> 0 P ( y t | y t − 1 0 ) (4) Although an RNN predicts y t conditioned on the high dimensional inputs y t − 1 0 , the individual pitch outputs y t ( i ) are independent, where i is the pitch index (Section IV -C). As mentioned earlier, this is not true for polyphonic music. Boulanger-Le wandowski et. al. [35] demonstrate that rather than predicting independent distributions, the parameters of a more complicated parametric output distribution can be conditioned on the RNN hidden state. In our experiments, we use the RNN to output the biases of a neural autoregressiv e distribution estimator (NADE) [35]. 2) Neural A utogressive Distribution Estimator : The N ADE is a distribution estimator for high dimensional binary data [36]. The NADE was initially proposed as a tractable alternativ e to the restricted Boltzmann machine (RBM). The N ADE estimates the joint distribution o ver high dimensional binary variables as follows: P ( x ) = Y i P ( x i | x i − 1 0 ) . The NADE is similar to a fully visible sigmoid belief network [37], since the conditional probability of x i is a non-linear function of x t 0 . The N ADE computes the conditional distribu- tions according to: h i = σ ( W : ,
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment