Impact of degree truncation on the spread of a contagious process on networks
Understanding how person-to-person contagious processes spread through a population requires accurate information on connections between population members. However, such connectivity data, when collected via interview, is often incomplete due to par…
Authors: Guy Harling, Jukka-Pekka Onnela
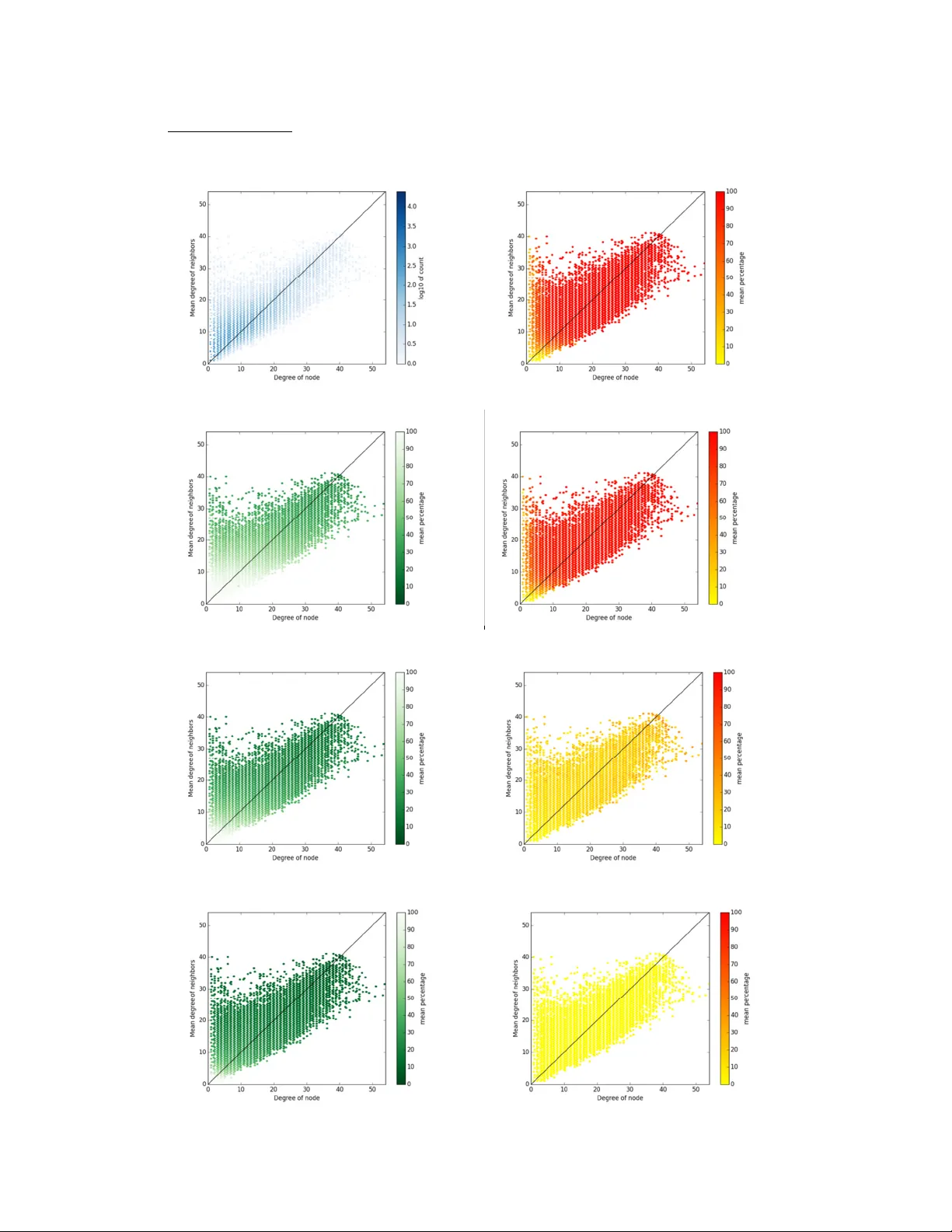
1 Title : Impact of degree truncation on the spread of a contagious proc ess on networks Running head : Degree truncation and contagious processes on networks Authors : Guy Harlin g, 1 Jukka-Pekka Onnela. 2 1. Department of Global Health and Population, Harvard T.H. Ch an School of Pu blic Health 2. Department of Biostatistics, Harv ard T.H. Chan School o f Public Health Email addresses : gharlin g@hsph.harvard.edu ; o nnela@hsph.harvard.edu Corresponding au thor : Jukka-Pekka Onnela, Department of Biostatist ics, Harvard T.H. Chan School of Public Health, 677 Hun tington Avenue, Boston, MA 02115. Acknowled gements : We thank members of the Onnela lab for feedback on earlier versions of this paper. This research was supported b y P30 AG034420. 2 Abstract Understanding how pers on-to-person contagious processes spr ead through a population requires accurate information on connections betwe en populatio n members. However, such connectivit y data, when collected via int erview, is often incomplete due to partial r ecall, respondent fati gue or study design, e.g., fix ed choice designs (FCD) truncate out-de gree b y limiting the number of contacts each respondent can report. Past research has shown how FCD truncation affects network properties, but its implications for predicted sp eed and size of spreadin g processes remain largely unexplo red. To study the impact of degree truncation on spr eading processes, we generated collections of synthetic n etworks containing specific prope rties (degree distribution, degree-assortativit y, clustering), and also used em pirical social network dat a from 75 villages in Karnataka, India. We sim ulated FCD using various truncation thresholds and ran a susceptibl e- infectious-recovered (SIR ) process on each netwo rk. We found that spreading processes propagated on truncated networks resulted in slower and smalle r epidemics, with a sudd en decrease in prediction accurac y at a level of truncation that varied b y network type. Our results have implications be yond FCD to truncation due to any limited sampling from a larger network. We conclude that knowledge of network stru cture is im portant for understanding the accurac y of predictions of process sp read on degree truncated networks. Keywords : Social networks; C ontact networks; Epidem ics; Truncation; Spreading processes; Validity; Fixed choice de sign; Network epidemiolog y 3 Introduction Our understanding of how disease, knowled ge and man y other phenomena spread throu gh a population can often be improved b y investigating the populati on’s social or other contact structure, which can be naturall y conceptualized as a network ( Newman, 2002; P astor-Satorras et al., 2015). In the case of human pop ulations, this contact structure is oft en gathered through th e use of questionnaires or s urveys that typicall y ask respondents to name som e of their contacts (Burt, 1984; Holland & Leinh ardt, 1973). Generat ing population-level network structures from such data requires one of two possible approaches (Marsden, 2005). One a pproach is to delineate a population of interest, i nterview ever y person in the population, and collect uni que identifiers for each respondent’s contacts; this allows the mapping of the tru e sociocentri c network within that population. The alternati ve is to sample the populatio n of interest and collect information about each respondent an d his or her contacts; thi s results in a collection of egocentric networks from that population. Eith er approach enables the ex traction of network features that can b e used to fit a graph model, such as one of the mo dels in the famil y of exponential random graphs (ERGMs) (Lusher et al., 2012), which allows the s ubsequent generation of network graphs consistent with the fitted features of t he observed networks. The f eatures that ma y be extracted from egocentric network s are however quite limited, makin g sociocentric n etworks the preferred design, resources allowin g. Both egocentric and sociocentric approa ches can place a consider able burden on the respond ent to recall numerous contacts and describe each in d etail (McCart y e t al., 2007). As a r esult, most sample surve y questionnaires, in both egocentric and s ociocentric designs, limit the contacts sought from a respondent, for ex ample by the content, in timacy level, geographic location or time frame of the relations hip elucidated (Campbell & Lee, 1991). A common m ethod is to limit 4 the number of contacts a respondent des cribes. This may be done directly, e.g. b y asking “who are your five closest friend s with whom you regularly socialize?” It may also be done indirectl y, e.g. by asking “who are the friends with whom you socialize” but then onl y asking follow-up questions about the first f ive named (Burt, 1984; Kogovsek et al., 2010). A l ess-common variant of the second approach is for the interview er to ask follow-up questi ons on a random subset of named contacts. More recentl y, there has been increasing interest in l everaging large-scale data on digitall y mediated social interactions ran ging from emails to onli ne social networking services to mob ile phone communication. Call detail records, resulting from mobil e phone calls and text and multimedia messages, ha ve become especiall y popular for capturing one-to-one social interactions in large populati ons (Blondel et al., 2015; Onnela et al., 2007 a; Onnela et al., 2007b). Social networks are constru cted from thes e data typicall y by aggregating longitudinal interactions over a time window of fix ed length, where the features of the resulting networks are fairly sensitive to the wid th of the aggregation window (Krin gs et al., 2012). Although some ad hoc approaches have bee n proposed, so far there a re no statistically principled methods available for setting the window wi dth. This leads to effective network de gree truncation t hat is not a consequence of stud y design per se but rather is induced b y the network construction process. While our focus here is degree truncation resulting from st udy design, we poin t out that man y of our findings are applicabl e in other settings as well . All of the above approac hes potentiall y lead to truncation of the number of observed cont acts. There is longstanding concern within the sociologi cal literature that such trun cation might affect 5 estimates of network properties, includi ng various forms of cent rality (Holland & Leinhardt, 1973). However, there are countervail ing resource and data qualit y benefits to avoiding respondent and interviewer fati gue (McCart y et al., 2007). While inv estigating the effect of degree truncation on structural prope rties of networks is an i mportant problem, substanti ve interest often lies in making inferences about how a dynamical process on t he network, such as epidemic spread, might be affected b y truncation. S urprisingl y, while both the impact of degree truncation on structural properties of n etworks and the im pact of structural properties on the spread of a d ynamic process through a networked population have been investi gated, the joint implications of the two processes h ave not yet been elucidated. To integrate ke y ideas from the two corpora, we review first t he literature on the impact of trunc ating reported contacts on structural network properties, and s econd the literature on th e impact of structural network properties on spread d ynamics, to arrive at hypotheses regardin g how truncatio n might change expected spreading process o utcomes. While our work was mot ivated b y epidemic disease processes, our anal ysis should be applicable to any process that c an be modeled using compartmental models of epidemi c spread. We test the predictions o f our hypotheses with simulation mod els using both synthetic, structured networks, and empirically observed netwo rks. Spreading processes on n etworks can be modeled b y generating ensembles o f networks weighted by their similarit y to observed egocentric data on certain ke y structural features, e.g., usin g Exponential R andom Graph Models (Lusher et al., 2012), or in a Bayesian framework th e networks can be sampled from an esti mated posterior dist ribution of networks consistent wit h the observed data (Go yal et al., 2014). Once the graphs have been generated, a series of dynamic processes are run across this collection of graphs (J enness et al., 2015). However, using this modeling approach to explore the imp act of truncation woul d conflate two processes: the 6 truncation process and th e network generation process. In order to focus on the former, we generate multiple realizations of synthetic full-network datasets with spe cific network properties, and additionally utilize a collection of empiricall y observed sociocentric n etworks that can be interpreted as multipl e network realizations from a larger meta-popul ation. As a result, we are able to isolate the effect of de gree truncation and ex plore its impact on spreadin g processes on networks with ver y different structural properties. The impact o f contact truncation on str uctural network properties Limiting the number of connections (“alte rs”) reported b y a respondent (“ego”) in both egocentric and sociocentri c designs is known as a f ixed choice design (FCD) (Holland & Leinhardt, 1973). This limit ation right-censors (impos es an upper bound on) an ego’s out-d egree (the number of alters nom inated by an ego). In sociocentric studies out-degree truncation m ay in turn reduce the in-degree of ot hers, because some ex isting ties may end up unreported due to t he constraints on out-degree. (In directed networks the mean in-de gree and mean out-de gree must match, since each edge adds o ne to the out-degree of the “source” nod e and one to the in -degree of the “sink” node.) Thus in the corresponding undi rected network, obtained from th e directed network simpl y by ignoring the directions of the edges and conside ring a mutual or two-wa y nomination as a single ed ge, the truncated (observ ed) total degree (either in or out) will be: where is the FCD trunca tion value and each individual’s degree in the trun cated network graph. For node with , edge between ego and alter will be maint ained for certain only if , otherwise ego must nominate alter in order for the ed ge to be observed. FCD 7 can be conducted in two wa ys, as outlined above. The more-comm on approach of focusin g on the first or fewer names reported ( “weighted truncation ”) is likel y to lead to bias towards stronger contacts, since s tronger ties are likel y to be more salient to a respondent. Thi s approach should thus maxim ize the proportion of a respond ent’s social interactions that i s captured. The less-common approach o f drawing a random subs et of all named contacts (“unwei ghted truncation”) will provide a broader picture o f the types of conta cts a respondent has – notabl y increasing the chance of obs erving weak ties – at the cost of observin g a smaller proportion of the respondent’s total social i nteraction. FCD is known to impact several canonical network characteristics, but its effects depend on the stru cture of the complete network graph (Kos sinets, 2006); we consider next some key properties. Degree distribution and ass ortativity. Wh ile the impact of FCD on the netw ork degree distribution is almost always to reduce its mean and variance, its precise effect depends on both the first and second mo ment of the degree distributio n and on the ratio of to the mean degree . Lower ratios generall y increase (strictly, never decrease) the num ber of edges dropped. Networks with higher-vari ance degree dist ributions will also typically lose more edges for a given ratio, insofar as such networks h ave a larger proportion of nodes with degree greater than , and thus for an y given edge both and are at higher risk of being truncated, leading to the edge being dropped. Loss of edges in high-var iance networks ma y, however, be offset b y degree-assortativity (Kossinets, 2006), often quant ified by the Pearson correlation coefficient of degrees of connected nodes: , where is the fraction of all ed ges that join nodes of degree and , and are the fraction of edges that sta rt and end, respectivel y, at nodes of degree or , 8 respectively, and and are the standard deviations of di stributions of and (Newman, 2003b). If the network is degree-disassortative, su ch as the scale-free Barabási-Albert netwo rk where and (B arabási & Albert, 1999 ), then edges t hat might be censored by the adjacent high-degree no de are less likely to also be censored b y the adjacent low-de gree node, and thus dropped e ntirely in the truncated network (V ázquez & Moreno, 200 3). Degree- assortative, high-variance networks a re thus likely to see th e greatest change in ; human contact networks are t ypically somewhat degree-assortati ve, and while communi cation contacts have fat-tailed degree dist ributions with hi gh variance, physical contact networks ar e more degree-homogeneous (O nnela et al., 2007a; Onne la et al., 2007b; Salathé et al., 2010). The level of degree-assortativit y in a network is not itself s ystematically affected by FCD, so long as ed ges are dropped without regard to the st rength of each connection (Kossinets, 2 006; Lee et al., 2006). However, if individuals are more likel y to report stronger connections, and t ies between individuals of sim ilar degree are more likely to be strong – which i s suggested b y the combination of findings th at homophilous ti es are more likely to be transitive (Louch, 2000; Marsden, 1987) and those with greate r transitivit y (Onnela et al., 2007b) tend to be stronger – then FCD might be expected to artificiall y inflate . Clustering . Local clustering can be me asured in at least two different wa ys: (i) Triadi c clustering : the mean of l ocal clustering coefficien t , where is the ratio of the number of ties present between all neighbors of nod e and , the number of pairs o f neighbors of (Watts & Strogatz, 1998); (ii) Focal clustering : the level of global triadic clos ure, that is the ratio of triangles – where , and are all present – to pat hs of length two, i.e., if ( and ex ist, they form a path of len gth two (Newman, 2010). C lustering may also occur at higher levels of aggregation in th e network, for example in the pre sence of network 9 communities where, loos ely speaking, the densit y of edges within a set of nodes belon ging to a communit y is higher than the average densit y of edges across the whole graph (Fortunato, 2010; Porter et al., 2009). One way to quantif y this community-level clustering is b y modularity, , where is the proportion of edges in the netwo rk that connect nodes in communit y to other nodes in communit y and is the proportion of ends of edges that are attached to nodes in commun ity (Newman, 2006). The value of mod ularit y can be normalized using the degree distribut ion of the network as , is the number of edges in the network and is equal to one if and zero otherwi se. This normalization makes modularity values more readily comparable across networks (Newman, 2010). When truncation is unwe ighted, we expect FCD t o reduce clustering at the triadi c and communit y levels as it effectively results in random edge removal. When tr uncation is weighted, however, FCD might lea d to an increase in clusterin g: if within-cluster edges are stron ger than others, the y are more likely to be preserved. Path lengths . In removing ties, unweighted FCD will reduce the fractional size of the larg est connected component ( LCC), , and will often increase the average path l ength between nodes of the LCC , . If FCD is weighted, howev er, the rate at which falls may be reduced, at the expense of a faster de cline in , as peripherall y (weakly) connected nodes are preferentiall y dropped from the LCC. In a network wi th a dense core, the is likely to be better preserved in a degree-disassortative th an in a degree-assortative netw ork under FCD – due to the lower probabilit y of ties within the core being dropp ed from both ends (Kossin ets, 2006). This effect will be more prono unced if the ties withi n this core are also stronger than ot her ties, 10 and thus more likely to be preserved. For some specific threshol d value of FCD the LCC will fragment, and two previou sly connected nodes ma y become disconnected. While the above discussion, as is common in network characteriz ations, considers shortest paths , random spreading processes, li ke random walks, rarel y take the shortest path from between two given nodes and . Because of this, the length o f the shortest path between n odes and in a fully observed network typicall y underestimates the len gth of the path taken b y a stochastic spreading process. Partial observation of the network, such as that in duced by degree truncation, inflates the lengths of sh ortest paths, but does of cou rse not alter the length of the actual unobserved paths taken b y the spreading process. For this reason, perhaps som ewhat paradoxically, shortest paths inferred from pa rtially observed networks can provide more accurate predictions of th e path lengths taken b y spreading processes than thos e based on full y observed networks (Onnela & Christakis, 2012). The impact o f structural network properti es on spreading processes There is a burgeoning literature on t he effect of various network prop erties on s preading process outcomes (Barrat et al., 20 08; Newman, 2002; Pas tor-Satorras et al., 2015). Under assumptions of population homogeneit y, relatively simple solutions can be found for ke y properties; however these results rarel y hold once we allow for an y non-trivial network structure (Keeli ng & Eames, 2005). We first outline canonical results und er homo geneity, and then consider how structur al network properties impact spreading processes. We focus on two asp ects of an outbreak: the early stage and the final state. To si mplify our analysis, we follow the tradition in t his literature and focus on models that ass ume degree infectivity, where an infectious indi vidual can infect all 11 their neighbors in just one ti me step, rather than un it infectivit y, where they can onl y infect one of their neighbors per time step (S taples et al., 2015). In the early stages, we are t ypically interested in two related qu antities: the basi c reproduction number , the number of new incident c ases (newly infected individuals) a rising from each currently infected individual in a full y-susceptible populati on; and , the initial exponential (or faster) growth rate of an epidemic. is defined in all settings as a function of , where is the probabilit y of infection per period and the number of contacts per peri od, and the rate at which individuals recover (or die), , where D is the mean duration of in fectiousness. I n a homogeneous mass-act ion model for an infection where recov ery leads to imm unity, i.e. a Susceptible-Infected-Rec overed (SIR) model, , w here ensures a large outb reak with non-zero probabilit y (Hethcote, 2000). is conceptuall y equal to in the first period, b ut thereafter is not well-defi ned analyticall y – even in homogenous models – and is t ypically measured empiricall y as the second moment of the epidemic cu rve in its initi al growth phase (Vynnycky & White, 2010). At t he end of an outbreak, we can evaluate its overall im pact via the attack rate , the proportion of th e population ever infected. Degree distribution and ass ortativity. I n a network s etting, can be viewed as the avera ge number of edges throu gh which an individual infe cts their neighbors across the whole period of their infectiousness if all t heir neighbors are susceptibl e. The probability of infection, , for each node can be conceptualized (for d egree infectivit y) in terms of their degree and their nei ghbors’ infection statuses. In a de gree-homogenous network, an epidemic will probabili stically take off if ; when networks are degree-hetero geneous, the likelihood of epidemic take -off becomes a function of th e first and second mome nts of the degree distribut ion (Newman, 2002). In an infinitely large scal e-free network where , , and thus an epidemic 12 occurs in all cases, regardless of the infection and recover y parameters (Barthelem y et al., 2005; Boguñá et al., 2003; Ma y & Lloyd, 2001; Pastor-Satorras & Vespignani, 2001). More generally, higher degree heterogene ity increases . Similarl y , higher degree- assortativit y increases the chances of epidemic take-off. On finite networks the probabilist ic threshold for epidemic take-off has a low er-bound of , the average degree of nearest neighbors, which is also the driver of both degenerate resul ts: in a homogeneous network and in an infinitel y large scale-free netwo rk (Boguñá et al., 2003). This is intui tive, since the number of one’s nei ghbors bounds the num ber of infections one can generat e. The speed of epidemic growth i s closely related to and . On an infinit e size, scale-free network, is extensive, since once infection r eaches high-degree nodes it spreads to a finite fraction of persons at the nex t time point (Vazquez, 2006a). More generall y, an epidemic on any scale-free network will s ee growth at a power law rate such that earl y in the epidemic infection levels will be greater than i s predicted by homogeneous m odels, in which growth rates are exponential (Vazquez, 2 006b). More generall y still, degree-assortativity has long been known to lead to f aster epidemic take- off, but a lower final epidemi c size, conditional on t he number of nodes and t ies within a network (Gupta et al., 19 89). This result arises fro m a dense core of high-degree nodes i n which infection is rapidly passed, i n combination with l onger paths to peripheral, low-degree nodes where chains of infection are more likely to die out. Clustering . The most straightforward effect of triadi c clustering, for a given degree distribut ion, is to reduce the average num ber of infections each infected person caus es. This reduction i s due 13 to newly-infected individuals having fewer suscep tible neighbors: the conta ct who infected you is likely also have had th e opportunity to infect your other contacts (Keeling, 2005; M iller, 2009; Molina & Stone, 2012). T his does not strictl y imply a lower , since refers to a completel y susceptible population, however this phenom enon increases the epidemic t hreshold in the same manner that a fall in would (Moli na & Stone, 2012). Sim ilarly, the epidemic growth rate is somewhat slowed b y this reduction in the proportion of sus ceptible alters (Eames, 2008 ). In many networks, e. g. Erd ő s–Rényi graphs (Erd ő s & Rén yi, 1959), for a given network densi t y, increased clustering also leads to a smaller , which necessarily reduces the maximum possible epidemic siz e (Newman, 2003a). However, with in the LCC clustering in creases the density of the network (Serrano & Boguná, 2006), providing more local path ways from an infected to a susceptible indivi dual. This reduces the protective effect of any alters who have recovered without infecting an e go, and thus some sim ulations have found clustering increases the attack rate (Keeling, 2005; Newman, 2003a ). Overall, cliques alone appear to hav e marginal effects on epidemic d ynamics, however the processes which drive clique formation – such as homophi ly by nodal attributes or geo graphic proximit y –lead to networks di splaying clustering that also contain o ther topological features – such as degree-assortativ ity or heterogeneit y – which do significantly affect epidemi cs, leading to processes on clustered networks looking ver y different from those on non-clust ered ones (Badham & Stocker, 2010 ; Molina & Stone, 2012; Vol z et al., 2011). Broader communit y structure in networks acts in much the same fashion as cli ques, reducing due to limited capacity to pass infection from one communit y to the next (Salathé & Jones, 2010 ); although epidemics are unhindered, or even sped up, b y inter-communit y ties when overlapping, rather than distinctl y separated, comm unities are built into networks (Reid & Hurle y, 2011). 14 Conjectured imp act of degree truncation on spreading processes Based on the above resul ts, we formulate some ini tial hypotheses about the likely impact of out- degree truncation on the behavior of spr eading processes on the resul ting network. First and foremost, truncation will reduce the number of ed ges in the network, since som e edges are now not observed. This leads to a reduction in mean degree and is li kel y to increase average path lengths and reduce the si ze of the ; as a result, both and will be reduced. T he reduction in may however be offset by reduced variance in degree – sin ce out-degree variance is st rictl y reduced by truncation and in-degree varian ce is likel y to drop too. Second, degree truncation b y tie strength may lead to an i nflation of degree-assortativit y, if assortative ties are stronger on average and thus more likel y to be preserved. This sh ould lead to smaller, faster epidemics – especially if assortativit y is created by preferentiall y dropping core-periphery links. Finall y, degree truncation b y tie strength will have an unpredictable effe ct on clustering – dependin g on the relationship between tie strength and communit y structure. Notabl y, if the two are strongly positivel y correlated, truncation m ay increase comm unity structure as weak ties are pref erentially dropped. If clustering is increased, bot h and A are likely to fall. Methods To test the above h ypotheses about the impact of degree truncation on s preading process outcomes, we: (1) simulat ed a truncation process on a ran ge of networks; (2 ) simulated a spreading process on the o riginal (fully observed or ‘full’ networ k) and truncated networks a large number of times; a nd (3) compared epidemic out come values for the full and truncated 15 networks (Figure 1). In the following, we describe in detail t he following: (A) the network generation process; (B) the truncation process; and (C ) the spreading process. A. Network stru ctures We considered four t ypes of synthetic networks t hat we call Degree-Assor tative, Triadic Clustering, Focal Cluster ing, and Power-Law networks, and in addition w e considered networks based on empirical data (details b elow). For unweighted s ynthetic networks, we used edge overlap as prox y for tie strength, defined as the fraction of shar ed network neighbors of a connected dyad: , where is the number of neighbors and have in common, and and are their degrees (Onnela et al., 2007b). Overlap was shown to be strongl y correlated with tie strength, as conjectured b y the weak t ies hypothesis several decades earlier (Granovetter, 197 3). The empirical social netwo rks were collected in 75 villages in Karnataka, Indi a, which were surve yed as part of a microfinance int ervention study in 2006 (Banerjee et al., 2013a, 2013 b). We defined an edge between two indi viduals to exist if either person reported any of the t welve t ypes of social interaction asked about in t he study. We began synthetic network const ruction b y generating a collection of degree sequences, wher e a degree sequence is a list of node degrees of a network. To generate 100 D egree-Assortative, Triadic Clustering, and Focal Clus tering networks, each consis ting of nodes, we drew 100 degree sequences of length from a Poisso n distribution wher e , as an approximation t o a binomial distribution wit h large N. We used the con figuration model to generate an initial graph realizati on for each degree sequence (Moll o y & Reed, 1995), and t hen rewired the networks, ed ge by edge, in order to o btain a collection of calibrated netwo rks such that each network closel y matches a target value of a chosen characte ristic, specificall y: 16 1. Degree-Assortative . This was achieved b y: (i) selecting two disj oint edges and uniformly at random; (ii) computi ng whether removi ng the two edges and replacing them with edge s and would increase network assortativi ty; and if so (iii) making this change. 2. Triadic Clust ering . This was achieved b y: (i) choosing an ego and two of its alters, and , who were not conn ected to one-another; (ii) addi ng the edge to the network, thus forming a triangle; and (iii) removing an edge selected uniforml y at random conditional on that edge not being part of a triangle, thus ensuring increased triadic clustering. 3. Focal Clustering . Thi s was achieved b y : (i) selecting three nodes , and un iformly at random; (ii) adding edges and if the y did not already exist; (iii) choosing uniforml y at random in the network the s ame number of edges that were just added (excluding edges and in the selection); (iv) comput ing whether removing this second set of edges would result in a net increase in focal clust ering – if so, removing them; if not, re peating steps (iii) and (iv ). We generated three versi ons of each type of s ynthetic network b y calibrating assortativit y, triadic clustering, and focal clus tering to the minimum, median and max imum values of th ese quantities observed in the 75 Karnataka vill ages (Table 1). To generate Power-Law networks, th e fourth t ype of synthetic network, we drew degree sequences from a power-law dist ribution , using the values 3, 2.5 and 2 for the degree exponent . W e discarded any ungraphable sequen ces, i.e. those where an y value greater than was drawn. We a gain used the configuration model to generate an initial graph 17 realization for each degree sequenc e. Note that lower values o f are associated with d egree distributions t hat have increasingly fat tails. For each of the four t ypes of synthetic networks, for each level of calibration we generated 100 independent representative networks usin g the above methods, for a total o f 1200 networks. B. Truncatio n We simulated degree truncation of the form t ypicall y seen in surveys, by placing a ceiling on the number of contacts, , that can be reported b y a respondent, and then reconst ructed the contact graph created from all sam pled contacts. To do this, we first conve rted the network into a directed graph. We then selectively removed directed edges starting from each individual , beginning with the edge havin g the smallest edge overlap val ue (the “weakest” edge); we were thus condu cting truncation by tie stren gth. We truncated at , taking values of , so that the maxim um out-degree of individuals was half the mean degree in the full network, the sam e as its mean degree, or twice its m ean degree. After truncating each individual’s out-degree, we collapsed the di rected graph int o an undirected one based on all remaining ties. Examples of this truncation process on 20-node networks are shown in Figure 2. We measured a range of network properties for each full and truncated network, inclu ding mean degree, degree-assortativ ity, triadic and focal clustering, and normalized m odularity – this last based on a graph partiti on for each network using the Louvain method (Blondel et al., 2008). 18 C. Spreading p rocess We ran a Susceptible- Infected-Recovered (SIR) mod el on the networks defined b y the per-period (per time step) probabilities (the probability of an infectious individual infecting each susceptible contact) and (the probabil ity of an infectious in dividual recovering). Each spreading process began with five initial i nfections, chosen uniforml y at random among the nodes of a network, and each S IR model was run 1 00 times on the full and degree truncat ed variants of each of the 10 0 networks. We measure d two categories of outco mes across all of the 10,000 runs (100 runs per network fo r 100 networks) of each s ynthetic network t ype (7,500 for the Karnataka village data), including result s from those runs for which at least 10% of individuals were ever infected: first, t ime to infection of the 10 th percentile of the population (epidemic growth : mean and 95% range); and s econd, the propor tion of nodes ever infected (the attack rate : mean and 95% range). Results Summary statistics for all n etworks at all levels of truncation ar e shown in Supplementar y Table 1. In all networks, both s ynthetic and empirical, out -degree truncation consistentl y reduced mean degree as expected, most strongly in Power- Law and Focal Clustering netw orks. Truncation strongly reduced degree-assortati vity in all cases ex cept for Power-Law networks, which we re already degree-disassortative, overwhelmin g any differences originall y seen across levels o f calibration; this effect was weaker for the Karnataka networks than for s ynthetic networks other than Power-Law. Modularit y increased with truncation in all networks except for Degree- Assortative ones (which had very high initial mod ularity). With the exception of P ower-Law and 19 Karnataka networks, where modul arit y rose smooth ly with increasing truncation , most of the increase only occurred once networks were truncated at half mean de gree. Both triadic and focal clustering fell, and the rose, consistentl y with increasing truncation for all networks in which clustering was init ially present. When epidemics were simul ated on the full networks, t he attack rate was ≥ 10% in almost every simulation (over 97.5%), with t he exception of Degree-Assortati ve networks where onl y around 90% of simulatio ns reached (Supplementary Table 2). Truncating networks at had almost no impact on the proporti on of epidemics with for any network, but further truncation led to a s harp fall-off. At truncation none of the clustered network epidemics reached , and onl y the Power-Law networks, t he Degree-Assort ative networks calibrated to the lowest level of assortativit y and the Karnataka networks had more than 2% of their epidemic reach the threshold. Without t runcation, 10% of all nodes were infecte d within 20 tim e steps on all networks except for the degree-assortative ones – whi ch also showed the greatest ran ge of (Table 2). Truncation at increased in all cases, but not b y large amounts; h owever truncation at both raised mean and its variance – notabl y in the cases of degree-asso rtative and triadic clustering networks (Fig ure 3A). For those netwo rks in which an y runs reached at truncation, both the mean and varian ce of increased as networks b ecame highl y fractured. Network structure had a greater impact on than on , with clear differences even on full networks (Figure 3B ). Truncation at had almost no i mpact on ex cept in the cases of Power-Law, and to a lesser ex tent Degree-Assortat ive, networks. However truncation at 20 leads to a mean rou ghly halving for all cases exce pt the Karnataka network s, where on ly falls by about a quarter. Once trunc ation reached , no network t ype averaged . Discussion Simulating a generic spreading process on a range of networks cont aining different stru ctures, we find that the speed and d egree to which predictions o f process outcomes – specificall y initial growth rate and final size – are affected b y out-degree trun cation varies greatl y. All processes are eventuall y pre dicted to have limi ted impact, however how much trun cation is required va ries. Notably, our abilit y to predict process outcomes is degraded more r apidly on st y lized s ynthetic networks than on a set of empirical social contact networks from villages i n Karnataka state, India. Central to understanding the effect of out-degree tr uncation on predictions o f spreading process outcomes is the transition when t he network becomes fragmented and the siz e of the largest connected component rapidl y decreases. In our anal yses, the Power-Law and Degree-Assortati ve networks showed slow declines in predicted process outcomes as t runcation increased, while the loss of accuracy was mor e rapid for both Triadic C lustering and Focal Clust ering networks – which lost fidelit y early on – and the Karnataka networks – which m aintained fidelit y for longer (Figure 3). The speed of ini tial growth was notabl y more variable for Degree-Assortative compared to all other net work types for both no truncation and truncation at , reflecting the importance of the initial infection sites when netw orks contain both highl y and lowly connected regions. This variation in findings su ggests that knowledge of the stru cture of a network for which one wishes to pred ict process spread is cruc ial in determining the level of resour ces that 21 should place into measurin g the full extent of the network it self: locall y clustered networks ma y require more contacts, w hile those with fat-tailed degree distributions ma y require fewer. Of course, knowing the mea n out-degree of a network i s a pre-requisite to determining the level of truncation that can be tolerated. In contrast to our conject ures, in no case did trunc ation increase either speed or size of process spread. The impact of truncation i n reducing the number of observ ed ties appeared to overwh elm all other processes, not le ast by affecting the network char acteristics of the t runcation networks: truncation at led to the Degree-Assortative networ ks being entirel y non-assortative and the Triadic Clustering and Focal Clus tering networks displ aying very limited clustering; onl y modularity appeared to b e maintained or even increased as th e FCD thresho ld was lowered – potentially because of the breakup of the netwo rk int o increasingly numbers of unconne cted components. Further investigation might find levels of truncation at which epi demics severit y is over-estimated, but in practical terms our findings point to a consistent underestimate of sp eed and attack rate using data truncated b y strength. In addition to network-level out comes, it is inst ructive to consider variabilit y in outcomes at the individual level. Wh ile it is clear that individuals with hi gher out-degree are more likel y to become infected, it is also lik ely that those with more-connected nei ghbors will become infected more often, since these connected nei ghbors are more likel y to be infected in the first place. This association can be seen in Figure 4 fo r the Karnataka networks (and Supplementar y Figure 3 for synthetic networks). Low degree individuals are unlikel y to be infected regardless of how w ell- connected their neighbors are, but for ou r exemplar infection neighbor degree has little impact for those with own degre e greater than ten (Figure 4B). As truncation increases – and has a disproportionate impact on ties dropped to higher -degree neighbors – indiv iduals with lower 22 mean degree neighbors are predi cted to be infected l ess often than those with the same degree, but lower mean neighbor degree (Figure 4C and D). Thi s effect is particular ly visible at the common FCD value of . These findings highlight that not onl y ca n truncati on impact population-level predictions of infection risk, but the y may also differentiall y affect individual- level predictions. There are several wa ys in which this analysis could be ex tended. First, it might be inform ative to consider unweighted, rather than wei ghted, truncation . Weighted truncation is l ikely to minimize mis-estimation of local spreadin g processes, since close-knit groups are likel y to be maintained at the expense of a realist ic picture of cross-comm unity connections. Unwei ghted truncation, in contrast, is likel y to reduce the speed of epidemic spread generall y, but maintain weak ties that span structural holes in t he network(Burt, 2004). Second, one could invest igate spreading processes based on edge weights, or using unit inf ectivity. Third, it might be worthwhil e to run these analyses for a wide range of truncation levels, i n order to evaluate which networks hav e more or less rapid transitions from relativel y accurate epidemic predictions to relatively inaccurate ones, and at what l evel of truncation these transitions occur. Such an anal ysis would be particularly useful in the contex t of a specific empi rical network and spreadin g process, rather than in the theoretical cases presented in t his paper, as a pre cursor to the cond uct of data collection in a surve y. While we have used a ran ge of network structures a nd a standard spreading process, our re sults are limited to t he cases we have considered, and thus investigation of other structures and processes mi ght be worthwhile. The ultimate goal of our anal ysis is to arrive at more accur ate predictions of process outcom es in the context of truncated contact data, the t ype of data that ar e common in the stud y of infectious diseases and public health int erventions. In addition to our sim ulation approach, there is the 23 potential for anal ytic work to evaluate the level of mis-prediction likel y to arise under a given level of degree truncatio n, for given network stru ctures. Ultimatel y, this should allow for us to adjust predictions for truncation. Such an approach mi ght use statistical or mechanistic network models to simul ate full networks congruent with both the estim ated rate of truncation, and observed characteristics of th e truncated network; si mulations could then be run on t hese simulated networks to pr edict process outcomes. As noted above, although we have framed out- degree truncation here as resultin g from the adoption o f FCD, our methods are agnostic to the cause of truncation. Consequentl y our results ma y generalize to settings where some other mechanism, such as social st igma in the case of self-reported sex ual networks, might lead to out- degree truncation. Finally, there has been increasing rese arch activit y in the past few years into digitall y mediated social networks, such as those resulti ng from mobile phone call and communication patterns. Reliance on these t ypes of data requires the investigator to specif y the width of the data aggregation window and other similar parameters, leading to effective degree truncation t hat is similar in its effects to the truncation r esulting here from st ud y design. It seems plausible that some of the insights we have obtained h ere, as well as som e of our methods, could be translated to this research context. Conclusion We have shown, via simulatio n, that truncation of a network via FCD has a s ystematic impact on how processes are predicted to s pread across this network. However, the d egree of impact varies strongly by the level of tr uncation, and we find tha t the transition level – at which im pact on 24 predicted process outcomes sh ifts from small to consid erable – varies b y network structure. Supplementary informati on on the structure of the full network – potentially estimated from past egocentric or sociocentri c studies in the same or s imilar populations – will thus often be crucial for increasing the accura cy of predictions of process s pread for truncated network data. 25 References Badham, J., & Stocker, R. (2010). The impact o f network clustering an d assortativity on epidemic behaviour. Theoretical Pop ulation Biology, 77 (1), 71-75. Banerjee, A., Chandrasekhar, A. G., Duflo, E. , & Jackson, M. O. (2013a). The Diff usion of Microfinance . (V9).Retrieved from http:// hdl.handle.net/1902.1/21538 Banerjee, A., Chandrasekhar, A. G., Duflo, E. , & Jackson, M. O. (2013b). The diff usion of microfinance. Science, 341 (6144). Barabási, A.-L., & Albert, R. (1999). Emergen ce of scaling in random networks . Science, 286 (5439), 509-512. Barrat, A., Barthelemy, M., & Vespignani, A. (200 8). Dyna mical processes on complex networks : Cambridge University Press. Barthelemy, M., Barrat, A., Pastor-Satorra s, R., & Vespignani, A. (2005). Dyna mical patterns of epidemic outbreaks in complex heterogeneous net works. [Research Support , Non-U.S. Gov't]. Journal of Theoretical Biology, 235 (2), 275- 288. doi: 10.1016/j.jtb i.2005.01.011 Blondel, V. D., Decuyper, A., & Krings, G. (2015). A survey of results on mob ile phone datasets analysis. arXiv prepr int arXiv:1502.03406 . Blondel, V. D., Guillaume, J.-L., La mbiotte, R., & Lefebvre, E. (2008). Fast unf olding of communities in large networks. Journal of S tatistical Mechanics: Theory a nd Experiment, 2008 (10), P10008. Boguñá, M., Pastor-Satorras, R., & Vespignani, A. (2003). Absence of epidemi c threshold in scale-free networks with degree correlations. [Research Support, Non-U.S. Gov't]. Physi cal Review Letters, 90 (2), 028701. Burt, R. S. (1984). Network items and the gener al social survey. Social ne tworks, 6 (4), 293-339. Burt, R. S. (2004). Structural holes and g ood ideas1. American j ournal of sociology, 110 (2), 349-399. Campbell, K. E., & Lee, B. A . (1991). Name generators in surveys of personal networks. Social networks, 13 (3), 203-221. Eames, K. T. (2008). Modelling disea se spread through random and reg ular contacts in clustered populations. Theoretical Populati on Biology, 73 (1), 104-111. Erdős, P., & Rényi, A. (195 9). On random graphs I. Publicationes Mathema ticae, 6 , 290-297. Fortunato, S. (2010). Community detect ion in graphs. Physics Reports, 486 (3), 75-174. Goyal, R., Blitzstein, J., & de Gruttola, V. (2014). Sampling networks from their posterior predictive distribution. Network Science, 2 (01), 107-131. Granovetter, M. S. (1973). The strength of weak ties. Amer ican journal of sociology , 1360-1380. 26 Gupta, S., Anderson, R. M., & May, R. M. (1989). Networks of sexual contacts: implications for the pattern of spread of HIV. AID S, 3 (12), 807-818. Hethcote, H. W. (2000). The mathemat ics of infectious diseases. SI AM review, 42 (4), 599-653. Holland, P. W., & Leinhardt, S. (1973). The structural implications of measurement error in sociometry. Journal of Mathematica l Sociology, 3 (1), 85-111. Jenness, S., Goodreau, S. M., & Morris, M. (2015). EpiModel: Mat hematical Modeling of Infectiou s Disease. R package version 1.2.1. Retrieved fr om http://CRAN.R - project.org/package=EpiModel Keeling, M. (2005). The implications of network structure for epide mic dynamics. Theoretical Population Biology, 67 (1), 1-8. Keeling, M. J., & Eames, K. T. (200 5). Networks and epide mic models. Journal of The Royal Society Interface, 2 (4), 295-307. Kogovsek, T., Mrzel, M., & Hlebec, V. (2010). " Plea se Name the First Two People y ou Would Ask for Help": The Effect of Limitation of t he Number of Alters on Network C omposition. Advances in Methodology & Statistics/Met odoloski zvezki, 7 (2). Kossinets, G. (2006). Effects of missing data in social networks. Social net works, 28 (3), 247-268. Krings, G., Karsai, M., Bernhard sson, S., Blondel, V. D., & Saramäki, J. (2012). E ffects of time window size and placement on the structure of an aggregated communication networ k. EPJ Data Science, 1 (4), 1-16. Lee, S. H., Kim, P.-J., & Jeong , H. (2006). Statistical properties of sa mpled networks. Physical Review E, 73 (1), 016102. Louch, H. (2000). Personal n etwork integration: transitivity and homophily in strong-tie relations. Social Networks, 22 (1), 45-64. Lusher, D., Koskinen, J., & Robins, G. (2 012). Exponential random graph models for social networks: Theory, methods, and ap plications : Cambridge University Press. Marsden, P. V. (1987). Core discus sion networks of Americans. American Sociological Review , 122- 131. Marsden, P. V. (2005). Recent develop ments in network measurement. M odels and methods in social network analysis, 8 , 30. May, R. M., & Lloyd, A. L. (2001). Inf ection dynamics on scale-free network s. Physical Review E, 64 (6), 066112. McCarty, C., Killworth, P. D., & Rennell, J. (200 7). Impact of methods for red ucing respondent burden on personal network stru ctural measures. Social networks, 2 9 (2), 300-315. Miller, J. C. (2009). Spread of infecti ous disease through cluster ed populations. Journal of The Roya l Society Interface, 6 (41), 1121-1134. 27 Molina, C., & Stone, L. (2012). Modelling the spread of diseases in clustered ne tworks. Journal of Theoretical Biology, 315 , 110-118. Molloy, M., & Reed, B. A. (1995). A cr itical point for random graphs with a giv en degree sequence. Random structures and algorithms, 6 (2/3), 161-180. Newman, M. E. (2002). Spread of ep idemic disease on networks. Physical Rev iew E, 66 (1), 016128. Newman, M. E. (2003a). Properties of highly clustered networks. Physical Rev iew E, 68 (2), 026121. Newman, M. E. (2006). Modularity and com munity structure in networks. Proceedings of the National Academy of Sciences, 103 (23), 8577 -8582. Newman, M. E. (2010). Networks: An Introduction : Oxford University Pres s. Newman, M. E. J. (2003b). Mixing patterns in networks. Physical Review E, 67 (2), 1-13. doi: 10.1103/PhysRevE.67.026126 Onnela, J.-P., & Christakis, N. A. (2012). Spreading paths in partially observed social networks. Physical Review E, 85 (3), 036106. Onnela, J.-P., Saramäki, J., Hy vönen, J., Szabó, G., De Menezes, M. A., Kaski, K. , . . . Kertész, J. (2007a). Analysis of a large-scale w eighted network of one-to-one human co mmunication. New Journal of Physics, 9 (6), 179. Onnela, J.-P., Saramäki, J., Hy vönen, J., Szabó, G., Lazer, D., Kaski, K., . . . Bar abási, A.-L. (2007b). Structure and tie strengths in m obile communication n etworks. Proceedings of the National Academy of Sciences, 104 (18), 7332-7336. Pastor-Satorras, R., Castellano, C., Van Mieghem, P., & Vespignani, A. (2015). E pidemic processes in complex networks. arXiv pr eprint arXiv:1408.2701 . Pastor-Satorras, R., & Vespignani, A. (2001). Epi demic spreading in scale-fre e networks. Physical Review Letters, 86 (14), 3200. Porter, M. A., Onnela, J.-P., & Mucha, P. J. (2009) . Communities in networks. Notices of t he AMS, 56 (9), 1082-1097. Reid, F., & Hurley, N. (2011). D iffusion in networks with overlapping communit y structure. Paper presented at the Data Mining Workshop s (ICDMW), 2011 IEEE 11th International Conference on. Salathé, M., & Jones, J. H. (2010). Dyna mics and control of diseases in netw orks with community structure. PLoS Computational Biol ogy, 6 (4), e1000736. Salathé, M., Kazandjieva, M., Lee, J. W. , Levis, P., Feldman, M. W., & Jone s, J. H. (2010). A high- resolution human contact network for infect ious disease transmission. Proceedings of the National Academy of Sciences, 107 (51), 22020 -22025. Serrano, M. Á., & Boguná, M. (2006). Perco lation and epidemic thresholds in clustered networks. Physical Review Letters, 97 (8), 088701. 28 Staples, P. C., Ogburn, E. L., & Onnela, J.-P. (2015). Incorporating Conta ct Network Structure in Cluster Randomized Trials. ar Xiv preprint arXiv:1505.00044 . Vazquez, A. (2006a). Polynomial growth in bran ching processes with divergi ng reproductive number. Physical Review Letters, 96 (3), 038702. Vazquez, A. (2006b). Spreading dynamics on small-world network s with connectivity fluctuat ions and correlations. Physical Rev iew E, 74 (5), 056101. Vázquez, A., & Moreno, Y. (2003). Re silience to damage of graph s with degree correlations. Physical Review E, 67 (1), 015101. Volz, E. M., Miller, J. C., Galvani, A., & Meyer s, L. A. (2011). Effects of heterog eneous and clustered contact patterns on infectious di sease dynamics. PLoS Computati onal Biology, 7 (6), e1002042. Vynnycky, E., & White, R. (2010). An introdu ction to infectious disease modelli ng : Oxford University Press. Watts, D. J., & Strogatz, S. H. (1998). Collective dyna mics of ‘small-world’networks. Natur e, 393 (6684), 440-442. 29 Supplementary materia l Supplementary Table 1: Descriptive st atistics for the calibrated n etwork graphs (mean and 95% confidence intervals) Supplementary Table 2: P ercentage of epidemic simul ation runs infecting at least 10% of the population Supplementary Figure 1: Tim e to infection of 10% of all indi viduals on networks, amon gst epidemic simulation runs i nfecting at least 10% of the population Supplementary Figure 2: Epidemi c attack rate on networks, amon gst epidemic sim ulation runs infecting at least 10% of the population. Supplementary Figure 3: Mean nei ghbor degree vs. own d egree for full and t runcated synthetic networks 30 Table 1: Target charact eristic values for calibrated syn thetic networks Minimum Median Maximum Degree-assorta tivity co efficient (r ) 0.283 0.421 0.797 Triadic c lustering coefficie nt (c ) 0.249 0.284 0.353 Focal clusteri ng coef ficient (t) 0.163 0.249 0.326 Power-law de gree expone nt ( γ ) -3.0 -2.5 -2.0 31 Table 2: Population-leve l outcomes am ongst epidemic simulation r uns infecting at least 10% of the population No truncation Truncation at twice mean degree Truncation at mean degree Truncation at half mean degree Time to infection of 1 0% of population Degree-Assortative 35.0 [20.0 - 85.0] 51.0 [27.9 - 120.9] 119.9 [67.1 - 185.0] 138.0 [81.0 - 188 .0] Triadic Clustering 17.0 [12.0 - 27.0] 22.0 [15.0 - 34.0] 61.0 [36.0 - 127.0] Focal Clustering 18.0 [11.0 - 39.0] 32.0 [20.0 - 65.0] 96.9 [51.9 - 174.4] Power-Law 8.0 [5.0 - 19.0] 16.9 [9. 0 - 38.0] 40.0 [17.9 - 107.1] 72.9 [ 35.0 - 153.1] Karnataka villages 15.0 [9.0 - 27.0] 21.0 [12.3 - 40.0] 43.0 [23.0 - 100.9] 88.4 [3 9.0 - 175.4] Percentage o f all individuals ever infectious Degree-Assortative 46.6 [39.3 - 52.8] 39.5 [27.4 - 47.2] 15.2 [10.4 - 26.4] 11.5 [10.2 - 16.6] Triadic Clustering 85.8 [83.4 - 87.9] 84.4 [81.6 - 86.7] 41.8 [18.8 - 54.1] Focal Clustering 60.2 [55.0 - 65.0] 58.0 [51.0 - 63.2] 15.7 [10.5 - 27.4] Power-Law 58.8 [51.5 - 65.1] 41.1 [32.6 - 48.2] 22.2 [12.6 - 30.0] 15.9 [10.6 - 27.5] Karnataka villages 78.1 [68.9 - 83.9] 76.2 [65.6 - 82.9] 57.5 [20.1 - 70.9] 13.9 [10.3 - 24.2] Percentage o f 47,500 epidemics infecting at least 10% of the population 96.5 93 .1 66.0 7.1 Figures show mean and 95% ranges for a ll runs from 10,000 simulations (7,500 f or Karnataka villages) for which at lea st of 10% of individuals were ever infected. Note that the pr oportion of retained networks fa lls as the level of tr uncation rises (see Supplementa ry Table 2 for details); empty cells represent simulation types w here no runs reached the 10% threshold. A ll network structur es are those with highest ne twork properties in each ca tegor y (see Methods and Table 1). 32 Figure 1: Schem atic of study methodology (1) For sy nthetic networks, 100 degree sequences were were generate d. For the Karnataka village data, 75 empirical village datase ts were used, and step 2 skipped. (2) Each degree sequence was converted into a networ k graph using the conf iguration model, and then each synthe tic graph was calibrate d based on target network value s. (3) All networks were tr uncated at twice mean , mean and half mean degree. (4) 100 epidemics were run acr oss each full and truncate d network. 33 Figure 2: Toy exam ples of truncation process for different synthetic graphs This figure shows thr ee graphs each containing 20 nodes and with a mea n degree of approximately 5. Each was generated by calibrating a c onfiguration-generated graph thro ugh rewiring to achieve specific target values of different ne twork characteristics. The top row shows each c alibrated graph with edge s marked in grey; the bottom row su perimposes in orang e the edges removed by truncating by tie strength at an out-degree of 3. 34 Figure 3: Epidem ic outcomes for simulation runs infec ting at least 10% of the pop ulation across six network struc tures A. B. Figures show mean and 95% ranges for a ll runs from 10,000 simulations (7,500 f or Karnataka villages) for which at lea st of 10% of individuals were ever infected. Simulation typ es are defined by out-deg ree truncation (Circle s: no truncation; Hexagon s: truncation at twice mean degree; Squares: trunca tion at mean degree; Triangles: trun cation at half mean degree). All network structure s are those with highest ne twork properties in each ca tegor y (see Methods and Table 1; full results fo r each network struc ture are available in Supplementary Figure 1 and Supplementary F igure 2). Empty lines represent simulation ty pes where no runs reac hed the 10% threshold. 35 Figure 4: Mean neighbor d egree vs. own d egree for full and trun cated Karnataka village contact networks A. Density of ties in full graph (lo g-scale); B-D: Mean proportion of epidemic runs in which the node was infected (linear s cale). The black diagonal line shows points of equal node and mean neighbor degree. In the f ull graph, most nodes are in fected most of the time, except those wit h either very low degree or ver y low mean neighbor degree. When trun cated at mean degree those with middling degree and mean neighbor degree are infected less often. When t runcated at half mean degree almost no n odes are ever infected. 36 Supplementary materia l Title : Impact of degree truncation on the spread of a contagious proc ess on networks 37 Suppleme ntary Table 1: Descriptive stat istics for the calibrate d network graphs (mean and 95% confidence inte rvals) A. Mean degree Not truncated Truncated at Truncated at Truncated at Karnataka villa ges 8.39 [7.84 - 8.97] 7.21 [6.72 - 7.60] 5.54 [4.77 - 5.65] 3.90 [2.78 - 3.95] Synthetic networks : Degree-Assortative r = 0.283 7.86 [7.86 - 7.86] 7.68 [7.67 - 7.68] 5.74 [5.72 - 5.76] 3.22 [3.20 - 3.24] r = 0.421 7.86 [7.86 - 7.86] 7.64 [7.63 - 7.65] 5.67 [5.65 - 5.69] 3.16 [3.13 - 3.18] r = 0.797 7.86 [7.86 - 7.86] 7.54 [7.53 - 7.55] 5.40 [5.38 - 5.42] 2.93 [2.91 - 2.95] Triadic Clustering c = 0.249 7.75 [7.75 - 7.75] 7.40 [7.39 - 7.42] 5.56 [5.53 - 5.58] 3.12 [3.10 - 3.13] c = 0.284 7.75 [7.75 - 7.75] 7.39 [7.36 - 7.40] 5.55 [5.52 - 5.57] 3.19 [3.17 - 3.20] c = 0.353 7.75 [7.75 - 7.75] 7.31 [7.29 - 7.33] 5.51 [5.48 - 5.53] 3.32 [3.30 - 3.33] Focal Clustering t = 0.163 7.95 [7.95 - 7.95] 6.84 [6.78 - 6.88] 4.49 [4.46 - 4.54] 2.57 [2.54 - 2.59] t = 0.249 7.95 [7.95 - 7.95] 6.29 [6.17 - 6.37] 4.07 [4.00 - 4.12] 2.32 [2.28 - 2.35] t = 0.326 7.95 [7.95 - 7.95] 5.84 [5.73 - 5.92] 3.76 [3.67 - 3.83] 2.15 [2.11 - 2.20] Power-Law γ = 3 7.78 [7.66 - 7.83] 6.58 [6.50 - 6.63] 4.70 [4.66 - 4.74] 2.89 [2.87 - 2.91] γ = 2.5 7.40 [7.04 - 7.55] 6.22 [5.97 - 6.33] 4.60 [4.56 - 4.65] 2.91 [2.89 - 2.93] γ = 2 6.18 [5.89 - 6.46] 4.78 [4.44 - 5.02] 4.00 [3.51 - 4.18] 2.88 [2.85 - 2.91] 38 B. Degree-assortativity Not truncated Truncated at Truncated at Truncated at Karnataka villa ges 0.33 [0.30 - 0.37] 0.23 [0.20 - 0.25] 0.11 [0.09 - 0.13] 0.02 [-0.02 - 0.05] Synthetic networks d efined by : Degree-Assortative r = 0.283 0.28 [0.28 - 0.28] 0.25 [0.25 - 0.26] -0 .02 [-0.03 - -0.01] -0 .19 [-0.20 - -0.18] r = 0.421 0.42 [0.42 - 0.42] 0.38 [0.37 - 0.38] -0 .00 [-0.01 - 0.01] -0 .19 [-0.20 - -0.17] r = 0.797 0.80 [0.80 - 0.80] 0.69 [0.68 - 0.69] -0 .00 [-0.02 - 0.01] -0 .20 [-0.21 - -0.18] Triadic Clustering c = 0.249 -0.05 [-0.06 - -0.04] -0.10 [-0.11 - -0.09] -0 .16 [-0.17 - -0.15] -0 .25 [-0.27 - -0.24] c = 0.284 -0.05 [-0.06 - -0.04] -0.10 [-0.11 - -0.09] -0 .17 [-0.18 - -0.16] -0 .26 [-0.27 - -0.25] c = 0.353 -0.06 [-0.07 - -0.05] -0.11 [-0.12 - -0.10] -0 .18 [-0.19 - -0.17] -0 .27 [-0.28 - -0.26] Focal Clustering t = 0.163 0.26 [0.23 - 0.29] 0.11 [0.09 - 0.12] -0 .07 [-0.08 - -0.06] -0 .18 [-0.20 - -0.17] t = 0.249 0.50 [0.46 - 0.55] 0.12 [0.11 - 0.14] -0 .10 [-0.11 - -0.08] -0 .20 [-0.22 - -0.19] t = 0.326 0.68 [0.65 - 0.72] 0.08 [0.07 - 0.10] -0 .14 [-0.15 - -0.13] -0 .23 [-0.25 - -0.21] Power-Law γ = 3 -0.04 [-0.06 - -0.03] -0.11 [-0.13 - -0.09] -0 .12 [-0.15 - -0.10] -0 .14 [-0.18 - -0.10] γ = 2.5 -0.10 [-0.13 - -0.08] -0.14 [-0.16 - -0.12] -0 .14 [-0.16 - -0.11] -0 .14 [-0.16 - -0.12] γ = 2 -0.22 [-0.24 - -0.20] -0.24 [-0.26 - -0.21] -0 .23 [-0.26 - -0.21] -0 .22 [-0.25 - -0.20] 39 C. Modularity Not truncated Truncated at Truncated at Truncated at Karnataka villa ges 0.79 [0.77 - 0.82] 0.81 [0.79 - 0.84] 0.84 [0.82 - 0.86] 0.87 [0.84 - 0.90] Synthetic networks d efined by : Degree-Assortative r = 0.283 0.29 [0.29 - 0.29] 0.30 [0.30 - 0.30] 0.40 [0.40 - 0.41] 0.66 [0.65 - 0.66] r = 0.421 0.28 [0.28 - 0.29] 0.30 [0.30 - 0.30] 0.41 [0.40 - 0.41] 0.66 [0.66 - 0.67] r = 0.797 0.28 [0.28 - 0.28] 0.30 [0.30 - 0.30] 0.44 [0.43 - 0.45] 0.71 [0.71 - 0.72] Triadic Clustering c = 0.249 0.46 [0.45 - 0.46] 0.46 [0.45 - 0.46] 0.48 [0.48 - 0.49] 0.68 [0.67 - 0.68] c = 0.284 0.47 [0.47 - 0.48] 0.47 [0.47 - 0.48] 0.49 [0.49 - 0.50] 0.67 [0.67 - 0.68] c = 0.353 0.50 [0.49 - 0.50] 0.50 [0.49 - 0.50] 0.52 [0.51 - 0.52] 0.66 [0.66 - 0.67] Focal Clustering t = 0.163 0.66 [0.65 - 0.67] 0.62 [0.61 - 0.63] 0.60 [0.59 - 0.60] 0.76 [0.76 - 0.77] t = 0.249 0.82 [0.81 - 0.83] 0.78 [0.77 - 0.79] 0.72 [0.72 - 0.74] 0.81 [0.81 - 0.82] t = 0.326 0.90 [0.89 - 0.91] 0.87 [0.86 - 0.89] 0.83 [0.81 - 0.84] 0.86 [0.85 - 0.87] Power-Law γ = 3 0.36 [0.36 - 0.36] 0.32 [0.31 - 0.32] 0.43 [0.43 - 0.44] 0.68 [0.67 - 0.69] γ = 2.5 0.36 [0.35 - 0.36] 0.34 [0.33 - 0.35] 0.45 [0.45 - 0.46] 0.68 [0.67 - 0.68] γ = 2 0.37 [0.36 - 0.38] 0.43 [0.41 - 0.45] 0.50 [0.49 - 0.56] 0.68 [0.67 - 0.68] 40 D. Triadic c lustering coefficient Not truncated Truncated at Truncated at Truncated at Karnataka villa ges 0.64 [0.63 - 0.66] 0.60 [0.57 - 0.61] 0 .50 [0.48 - 0.51] 0.34 [0.27 - 0.37] Synthetic networks d efined by : Degree-Assortative r = 0.283 0.01 [0.01 - 0.01] 0.01 [0.01 - 0.01] 0 .00 [0.00 - 0.01] 0.00 [0.00 - 0.00] r = 0.421 0.01 [0.01 - 0.01] 0.01 [0.01 - 0.01] 0 .00 [0.00 - 0.01] 0.00 [0.00 - 0.00] r = 0.797 0.01 [0.01 - 0.01] 0.01 [0.01 - 0.01] 0 .01 [0.01 - 0.01] 0.00 [0.00 - 0.00] Triadic Clustering c = 0.249 0.29 [0.29 - 0.30] 0.26 [0.26 - 0.26] 0 .13 [0.12 - 0.13] 0.03 [0.03 - 0.04] c = 0.284 0.34 [0.34 - 0.34] 0.30 [0.29 - 0.30] 0 .15 [0.15 - 0.16] 0.04 [0.04 - 0.05] c = 0.353 0.43 [0.43 - 0.43] 0.37 [0.36 - 0.37] 0 .20 [0.19 - 0.20] 0.07 [0.06 - 0.07] Focal Clustering t = 0.163 0.37 [0.37 - 0.38] 0.28 [0.27 - 0.28] 0 .12 [0.12 - 0.13] 0.04 [0.04 - 0.05] t = 0.249 0.43 [0.42 - 0.44] 0.30 [0.29 - 0.31] 0 .15 [0.13 - 0.15] 0.06 [0.05 - 0.06] t = 0.326 0.45 [0.44 - 0.46] 0.31 [0.30 - 0.32] 0 .16 [0.15 - 0.17] 0.06 [0.05 - 0.07] Power-Law γ = 3 0.04 [0.03 - 0.05] 0.02 [0.02 - 0.02] 0 .01 [0.01 - 0.01] 0.00 [0.00 - 0.01] γ = 2.5 0.09 [0.07 - 0.13] 0.04 [0.03 - 0.05] 0 .02 [0.02 - 0.03] 0.01 [0.01 - 0.01] γ = 2 0.21 [0.19 - 0.22] 0.05 [0.04 - 0.06] 0 .03 [0.03 - 0.03] 0.02 [0.01 - 0.02] 41 E. Focal clustering c oefficient Not truncated Truncated at Truncated at Truncated at Karnataka villa ges 0.19 [0.17 - 0.21] 0.18 [0.16 - 0.19] 0 .16 [0.15 - 0.17] 0.11 [0.08 - 0.12] Synthetic networks d efined by: Degree-Assortative r = 0.283 0.00 [0.00 - 0.00] 0.00 [0.00 - 0.00] 0 .00 [0.00 - 0.00] 0.00 [0.00 - 0.00] r = 0.421 0.01 [0.00 - 0.01] 0.00 [0.00 - 0.00] 0 .00 [0.00 - 0.00] 0.00 [0.00 - 0.00] r = 0.797 0.01 [0.01 - 0.01] 0.01 [0.01 - 0.01] 0 .00 [0.00 - 0.00] 0.00 [0.00 - 0.00] Triadic Clustering c = 0.249 0.07 [0.07 - 0.07] 0.06 [0.06 - 0.06] 0 .03 [0.03 - 0.03] 0.01 [0.01 - 0.01] c = 0.284 0.08 [0.08 - 0.08] 0.07 [0.07 - 0.07] 0 .03 [0.03 - 0.03] 0.01 [0.01 - 0.01] c = 0.353 0.09 [0.08 - 0.09] 0.07 [0.07 - 0.07] 0 .04 [0.04 - 0.04] 0.01 [0.01 - 0.01] Focal Clustering t = 0.163 0.16 [0.16 - 0.16] 0.11 [0.10 - 0.11] 0 .05 [0.04 - 0.05] 0.01 [0.01 - 0.02] t = 0.249 0.25 [0.25 - 0.25] 0.14 [0.13 - 0.14] 0 .06 [0.06 - 0.06] 0.02 [0.02 - 0.02] t = 0.326 0.33 [0.33 - 0.33] 0.15 [0.15 - 0.16] 0 .07 [0.06 - 0.07] 0.02 [0.02 - 0.03] Power-Law γ = 3 0.02 [0.02 - 0.02] 0.01 [0.01 - 0.01] 0 .00 [0.00 - 0.00] 0.00 [0.00 - 0.00] γ = 2.5 0.03 [0.02 - 0.03] 0.01 [0.01 - 0.01] 0 .00 [0.00 - 0.00] 0.00 [0.00 - 0.00] γ = 2 0.04 [0.04 - 0.05] 0.01 [0.01 - 0.01] 0 .00 [0.00 - 0.00] 0.00 [0.00 - 0.00] 42 F. Average shortest path in Largest Connec ted Component Not truncated Truncated at Truncated at Truncated at Karnataka villa ges 4.10 [3.89 - 4.36] 4.43 [4.19 - 4.68] 5 .30 [5.00 - 5.82] 7.09 [6.56 - 9.23] Synthetic networks d efined by : Degree-Assortative r = 0.283 3.61 [3.61 - 3.62] 3.65 [3.65 - 3.65] 4 .17 [4.16 - 4.18] 6.17 [6.13 - 6.23] r = 0.421 3.65 [3.65 - 3.65] 3.69 [3.69 - 3.69] 4 .22 [4.21 - 4.23] 6.36 [6.29 - 6.41] r = 0.797 3.88 [3.87 - 3.88] 3.91 [3.90 - 3.91] 4 .47 [4.47 - 4.48] 7.36 [7.28 - 7.46] Triadic Clustering c = 0.249 3.71 [3.70 - 3.72] 3.78 [3.77 - 3.79] 4 .22 [4.20 - 4.23] 6.35 [6.28 - 6.42] c = 0.284 3.70 [3.70 - 3.72] 3.78 [3.77 - 3.79] 4 .21 [4.20 - 4.23] 6.11 [6.05 - 6.17] c = 0.353 3.69 [3.68 - 3.70] 3.78 [3.77 - 3.79] 4 .20 [4.18 - 4.22] 5.75 [5.70 - 5.80] Focal Clustering t = 0.163 4.09 [4.07 - 4.12] 4.21 [4.18 - 4.23] 4 .91 [4.88 - 4.94] 7.94 [7.84 - 8.07] t = 0.249 4.61 [4.56 - 4.66] 4.73 [4.68 - 4.78] 5 .39 [5.34 - 5.45] 8.33 [8.26 - 8.47] t = 0.326 5.23 [5.10 - 5.39] 5.34 [5.20 - 5.51] 5 .98 [5.83 - 6.17] 8.85 [8.60 - 9.14] Power-Law γ = 3 3.35 [3.30 - 3.38] 3.61 [3.56 - 3.64] 4 .25 [4.18 - 4.30] 6.34 [6.12 - 6.51] γ = 2.5 3.16 [3.09 - 3.23] 3.43 [3.36 - 3.51] 3 .93 [3.79 - 4.06] 5.52 [5.22 - 5.80] γ = 2 3.07 [3.03 - 3.10] 3.50 [3.45 - 3.54] 3 .85 [3.79 - 3.93] 4.70 [4.59 - 4.83] : Mean degree of nodes in a given gra ph. For definitions of , c, , and and how they define each synthetic netwo rk type, please see main text of pape r. 43 Supplementary Table 2: Percentage of epidemic simulation run s infecting a t least 10% of the population Not truncated T runcated at T runcated at T runcated at Karnat aka villag es 99.5 99.3 90.4 11.9 Synthetic ne two rks defined by : Degree-Assortative r = 0. 283 91.1 90.1 76.0 11.7 r = 0. 421 89.9 88.9 69.3 8.7 r = 0. 797 89.1 82.6 26.7 1.0 Triadic Clusterin g c = 0.2 49 99.8 99.8 87.3 0.0 c = 0.2 84 99.9 99.8 92.1 0.0 c = 0.3 53 99.8 99.8 95.9 0.0 Focal Clustering t = 0.1 63 99.6 99.4 55.6 0.0 t = 0.2 49 98.9 98.3 66.0 0.0 t = 0.3 26 97.5 96.4 66.7 0.0 Power-Law γ = 3 98.6 92.1 43.6 9.7 γ = 2. 5 98.9 95.1 51.9 15.0 γ = 2 97.5 89.1 56.3 23.8 Figures are percentage poin ts of 10,000 runs (s ynthetic networks) or 7500 runs (Karnataka villages). 44 Supplementary Figure 1 : Time to infection of 10% of all individu als on networks, amongst epidemic simulation runs infecting at least 10% of th e population A: Karnataka villages; B: De gree-Assortative; C: Triadic Cl ustering; D: Focal Clus tering; E: Power-Law networks. Fi gures show mean and 95 % ranges for all runs fro m 10,000 sim ulations (7,500 for Karnataka villages) for whi ch at least of 10% of individuals were ever infected. Simulation t ypes are defined by truncation (see legend) and lev el of calibrat ion – darker shading represents stronger calibr ation towards higher values of network p roperties (see Table 1). Empt y lines represent simulatio n types where no runs reached the 10 % threshold. 45 Supplementary Figure 2 : Epidemic attack rate on networks , amongst epidemic simulation runs infecting at least 10% of the population . A: Karnataka villages; B: De gree-Assortative; C: Triadic Cl ustering; D: Focal Clus tering; E: Power-Law networks. Fi gures show mean and 95 % ranges for all runs fro m 10,000 sim ulations (7,500 for Karnataka villages) for whi ch at least of 10% of individuals were ever infected. Simulation t ypes are defined by truncation (see legend) and lev el of calibrat ion – darker shading represents stronger calibr ation towards higher values of network p roperties (see Table 1). Empt y lines represent simulatio n types where no runs reached the 10 % threshold. 46 Supplementary Figure 3 : Mean neighbor degr ee vs. own degree for f ull and truncated synthetic networks For each set of figures be low: A. Full graph; B: graph truncated at twic e mean degree; C: g raph truncated at mean degree; D: graph truncated at half mean degree. Wi thin each cell, darker=mor e: Blue (A1): Initial density of ties (log-scale); Green (B 1, C1, D1): Mean proport ion of neighbors dropped (lin ear scale); Red- Yellow (A2, B2, C2, D2) : Mean proportion of epidemi c runs in which the node was infe cted (linear scale). The black diagonal l ine shows points of equal node and m ean neighbor de gree. 47 I. Degree-Assortative A1. A2. B1. B2. C1. C2. D1. D2. 48 II. Triadic Clustering A1. A2. B1. B2. C1. C2. D1. D2. 49 III. Focal Clustering A1. A2. B1. B2. C1. C2. D1. D2. 50 IV. P ower-Law degree distribu tion A1. A2. B1. B2. C1. C2. D1. D2. 51 V. Karnataka villages A1. A2. B1. B2. C1. C2. D1. D2.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment