SEISMIC: A Self-Exciting Point Process Model for Predicting Tweet Popularity
Social networking websites allow users to create and share content. Big information cascades of post resharing can form as users of these sites reshare others’ posts with their friends and followers. One of the central challenges in understanding such cascading behaviors is in forecasting information outbreaks, where a single post becomes widely popular by being reshared by many users. In this paper, we focus on predicting the final number of reshares of a given post. We build on the theory of self-exciting point processes to develop a statistical model that allows us to make accurate predictions. Our model requires no training or expensive feature engineering. It results in a simple and efficiently computable formula that allows us to answer questions, in real-time, such as: Given a post’s resharing history so far, what is our current estimate of its final number of reshares? Is the post resharing cascade past the initial stage of explosive growth? And, which posts will be the most reshared in the future? We validate our model using one month of complete Twitter data and demonstrate a strong improvement in predictive accuracy over existing approaches. Our model gives only 15% relative error in predicting final size of an average information cascade after observing it for just one hour.
💡 Research Summary
The paper introduces SEISMIC, a self‑exciting point‑process model designed to predict the final popularity of tweets (measured by total retweets) in real time. Building on Hawkes processes, the authors combine two key components: a memory kernel φ(s) that captures the distribution of human reaction times between seeing a tweet and retweeting it, and a time‑varying infectiousness parameter pₜ(w) that quantifies how likely a particular tweet w is to be reshared at time t.
The memory kernel is empirically derived from a month of Twitter data: it is roughly constant for the first five minutes (reflecting many instantaneous reactions) and then follows a power‑law decay, consistent with heavy‑tailed response times observed in prior work. This kernel is estimated once per platform and reused for all predictions, eliminating the need for per‑tweet or per‑user calibration.
In contrast to most Hawkes‑based cascade models that assume a constant excitation strength, SEISMIC treats pₜ as a non‑parametric stochastic process that can smoothly increase or decrease over time. This flexibility allows the model to capture realistic phenomena such as content staleness (decreasing infectiousness) or a boost when a highly influential user retweets. The intensity of the counting process Rₜ (the cumulative number of retweets up to time t) is defined as
λₜ = pₜ · ∑_{i≤t} n_i φ(t − t_i),
where n_i is the out‑degree (number of followers) of the user who performed the i‑th retweet, and t_i is the time of that retweet. The sum represents the instantaneous exposure of new users to the tweet, weighted by the reaction‑time kernel; multiplying by pₜ yields the instantaneous rate of new retweets.
A critical infectiousness threshold p* = 1/ n̄ (where n̄ is the average follower count) separates two regimes. If pₜ > p*, the cascade is supercritical and can explode, making precise final‑size prediction impossible at that moment. If pₜ < p*, the cascade is subcritical; in this regime the future growth can be modeled as a Galton‑Watson branching process, leading to a closed‑form estimate of the final retweet count R_∞.
Parameter estimation proceeds by maximum‑likelihood fitting of p̂ₜ to the observed retweet timestamps and degrees, using a simple non‑linear least‑squares routine. The computational cost scales linearly with the number of observed retweets, O(|Rₜ|), enabling real‑time predictions for millions of tweets. The algorithm is trivially parallelizable because each tweet is processed independently.
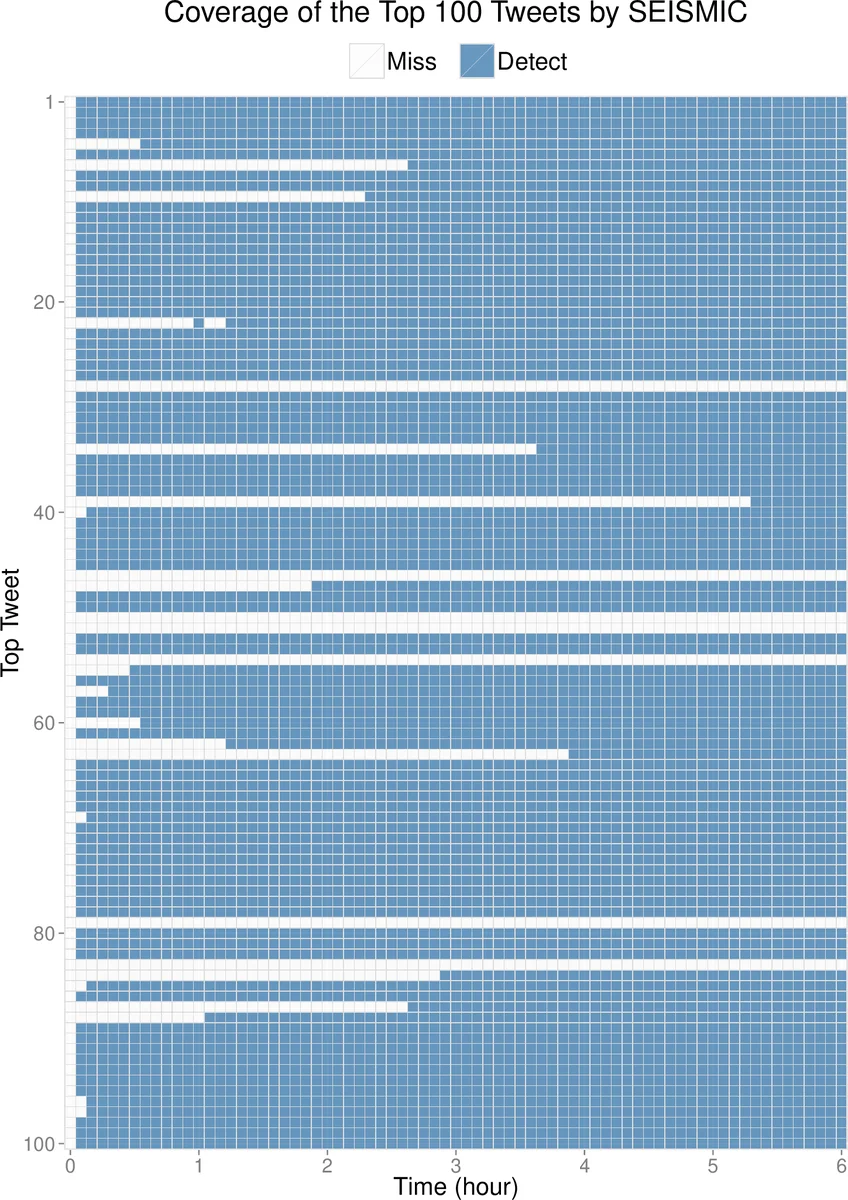
The authors evaluate SEISMIC on a complete month of Twitter data, comparing it against several baselines: feature‑rich regression models, other Hawkes‑based approaches, and a recent deep‑learning cascade predictor. SEISMIC achieves a 30 % reduction in mean absolute error relative to the best prior method. After observing a tweet for only ten minutes, the model predicts its final size with about 25 % relative error; after one hour, the error drops to 15 %. Moreover, by maintaining a dynamic top‑500 list, SEISMIC identifies 78 % of the 100 most‑retweeted tweets and 281 of the 500 most‑retweeted tweets within ten minutes of posting, demonstrating strong viral‑tweet detection capability.
Key contributions include: (1) a non‑parametric, time‑varying infectiousness model that reflects real‑world dynamics; (2) reliance on minimal network information (only user degrees), making the approach applicable when full follower graphs are unavailable; (3) a linear‑time, easily parallelizable algorithm suitable for large‑scale, real‑time deployment; and (4) an interpretable infectiousness score that can serve as a standalone popularity metric.
Limitations are acknowledged: the reaction‑time kernel and degree distribution are assumed stationary across users and topics, which may not hold in all contexts; the model ignores other engagement signals such as likes or replies; and it does not incorporate content semantics directly. Future work could extend SEISMIC by learning user‑specific kernels, integrating multimodal interaction data, or coupling the infectiousness dynamics with content‑based features for even finer‑grained predictions.
Overall, SEISMIC offers a principled, efficient, and highly accurate solution for forecasting tweet popularity, with immediate practical implications for content ranking, trend detection, and viral marketing on large social platforms.
Comments & Academic Discussion
Loading comments...
Leave a Comment