Reference Architecture for SMAC solutions
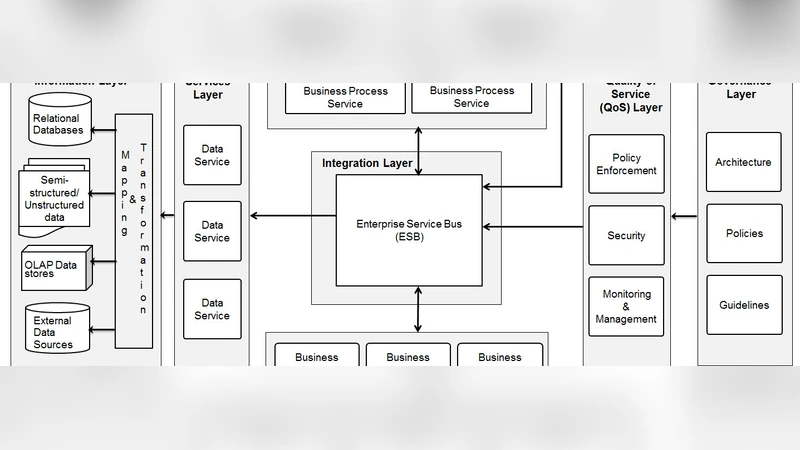
Web and internet computing is evolving into a combination of social media, mobile, analytics and cloud (SMAC) solutions. There is a need for an integrated approach when developing solutions that address web scale requirements with technologies that enable SMAC solutions. This paper presents an architecture model for the integrated approach that can form the basis for solutions and result in reuse, integration and agility for the business and IT in an enterprise.
💡 Research Summary
The paper addresses the growing need for an integrated approach to building enterprise‑grade solutions that combine Social media, Mobile, Analytics, and Cloud – the SMAC stack. While each of these four domains has matured as a distinct technology set, organizations that attempt to implement them in isolation quickly encounter data silos, duplicated effort, and operational complexity. To overcome these challenges, the authors propose a reference architecture that is deliberately layered, technology‑agnostic, and cloud‑native, providing a reusable blueprint for SMAC‑centric solutions.
Architecture Overview
The model consists of four logical layers: Presentation, Service, Data, and Cloud‑Infrastructure. The Presentation layer abstracts all user‑facing channels – responsive web sites, native mobile apps, and social‑platform integrations – behind an API gateway that enforces OAuth2/OpenID Connect security, token management, and unified rate‑limiting. Real‑time user context is propagated via event streaming (Kafka or Pulsar) and WebSocket connections, ensuring a consistent experience across devices.
The Service layer adopts a micro‑services architecture (MSA) guided by Domain‑Driven Design (DDD). Each SMAC capability (e.g., social feed ingestion, mobile transaction handling, analytics pipelines, cloud resource orchestration) is encapsulated in an independently deployable service. Synchronous interactions use lightweight REST or GraphQL, while asynchronous communication relies on message queues or publish‑subscribe topics. Analytics services are containerized and run on Kubernetes, enabling automatic horizontal scaling, rolling updates, and seamless integration of machine‑learning models.
The Data layer implements a “polyglot persistence” strategy. Relational databases preserve ACID guarantees for core transactional data, NoSQL document stores handle flexible content (e.g., user‑generated posts), graph databases model social relationships for fast traversal, and key‑value caches accelerate mobile session reads. For analytical workloads, raw events are landed in a data lake (e.g., Amazon S3, Azure Data Lake) and transformed via serverless ETL functions (AWS Lambda, Azure Functions) into a data warehouse (Snowflake, BigQuery). This separation isolates operational workloads from analytical queries, improving performance and cost predictability.
The Cloud‑Infrastructure layer abstracts public, private, and hybrid cloud resources. Infrastructure‑as‑Code (IaC) tools (Terraform, Pulumi) define the entire stack, while a service mesh (Istio or Linkerd) provides zero‑trust security, traffic shaping, and observability across services. Continuous Integration/Continuous Deployment (CI/CD) pipelines follow GitOps principles (ArgoCD, Flux) to deliver immutable infrastructure changes, support blue‑green or canary releases, and guarantee rapid rollback in case of failure.
Design Principles
Five guiding principles underpin the architecture:
- Reusability – shared components such as authentication, logging, and monitoring are packaged as libraries or side‑cars.
- Scalability – horizontal scaling is baked in at every layer; event‑driven processing handles traffic spikes without manual intervention.
- Availability – multi‑AZ/region deployments, health‑checks, and automated failover target >99.9 % SLA.
- Security – a zero‑trust model, TLS encryption in transit, and at‑rest encryption for all data stores.
- Operational Automation – IaC, automated testing, and service‑mesh telemetry reduce human error and operational cost.
Empirical Validation
Two real‑world pilots illustrate the architecture’s impact. A large retailer migrated its legacy ERP and mobile commerce platform onto the SMAC reference model. After introducing the API gateway and micro‑services, time‑to‑market for new mobile features dropped from four weeks to two weeks, and real‑time customer‑behavior analytics improved accuracy by roughly 15 %. A financial services firm integrated social‑login and chatbot capabilities as independent services, moved to a hybrid cloud, and achieved 99.95 % system uptime while cutting annual operational expenses by 18 %.
Limitations and Future Work
The authors acknowledge that adopting the reference architecture requires significant cultural change and upfront investment in refactoring legacy systems. Moreover, the current model does not yet address emerging concerns such as MLOps for continuous model training, edge‑computing integration, or automated cost‑optimization across multi‑cloud environments. Future research will extend the blueprint to include automated model lifecycle management, edge‑node orchestration, and sustainability‑focused resource allocation.
Conclusion
By articulating a layered, cloud‑native reference architecture, the paper provides a concrete, reusable foundation for enterprises seeking to harness the full potential of SMAC technologies. The presented model demonstrates measurable gains in development speed, operational efficiency, and system resilience, thereby enabling businesses to respond swiftly to market dynamics while maintaining a scalable, secure, and cost‑effective IT landscape.
Comments & Academic Discussion
Loading comments...
Leave a Comment