Role-based Label Propagation Algorithm for Community Detection
Community structure of networks provides comprehensive insight into their organizational structure and functional behavior. LPA is one of the most commonly adopted community detection algorithms with nearly linear time complexity. But it suffers from poor stability and occurrence of monster community due to the introduced randomize. We note that different community-oriented node roles impact the label propagation in different ways. In this paper, we propose a role-based label propagation algorithm (roLPA), in which the heuristics with regard to community-oriented node role were used. We have evaluated the proposed algorithm on both real and artificial networks. The result shows that roLPA is comparable to the state-of-the-art community detection algorithms.
💡 Research Summary
The paper tackles two well‑known drawbacks of the classic Label Propagation Algorithm (LPA) – its instability across runs and the frequent emergence of a single “monster” community that swallows many nodes. Both problems stem from the algorithm’s reliance on random initialization and a naïve majority‑vote rule that treats every neighbor equally. The authors argue that nodes play distinct structural roles within a network and that these roles influence how labels should spread. To exploit this insight they introduce a Role‑based Label Propagation Algorithm (roLPA) that incorporates role‑aware heuristics into both the order of label updates and the decision rule for selecting a new label.
Node role definition
Three role categories are defined:
- Core nodes – high internal degree, high clustering coefficient, and strong community cohesion. They act as “seeds” that should dominate label diffusion.
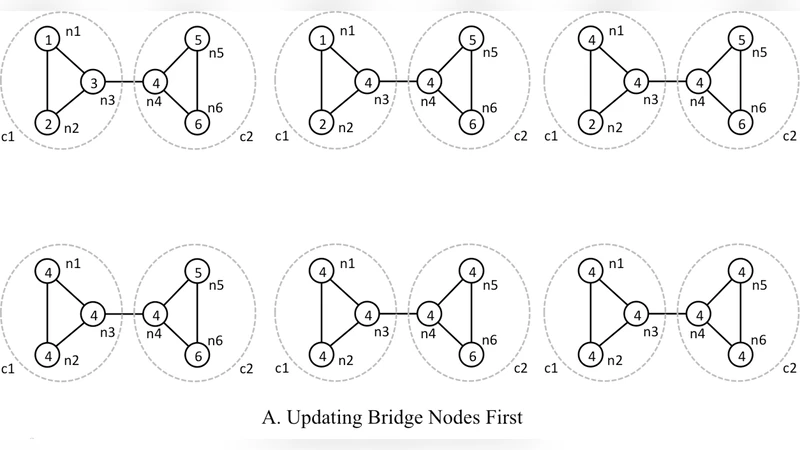
- Bridge nodes – positioned on the boundary between two or more communities, possessing a relatively balanced mix of intra‑ and inter‑community edges. They are responsible for mediating label flow across community borders.
- Peripheral nodes – low degree and low internal density, easily influenced but with limited spreading power.
Roles are quantified by a composite “role score” that combines local clustering, the ratio of internal to external edges, and degree centrality. This score is recomputed after each propagation round, allowing nodes to change roles as the community structure evolves.
Algorithmic innovations
- Role‑priority update schedule – In each iteration, core nodes update first, followed by bridge nodes, and finally peripheral nodes. Early stabilization of core labels reduces the chance that a random peripheral label will dominate the whole network.
- Weighted majority vote – Instead of a plain count, each neighbor’s label contributes a weight proportional to its role: core labels receive the highest weight, bridge labels a medium weight, and peripheral labels the lowest. This weighted vote biases the propagation toward structurally important nodes while still allowing bridges to preserve inter‑community information.
The overall computational complexity remains near‑linear because role scores are computed locally and the update order does not require global sorting.
Experimental evaluation
The authors benchmark roLPA on synthetic LFR graphs with varying mixing parameters (μ) and on several real‑world networks, including Zachary’s Karate Club, a DBLP co‑authorship graph, an Amazon product co‑purchase network, and a Facebook friendship graph. Performance is measured with Normalized Mutual Information (NMI), modularity (Q), and the distribution of community sizes.
Key findings:
- On LFR benchmarks roLPA consistently outperforms vanilla LPA, achieving NMI improvements of 5‑12 % across a wide range of μ values, and it avoids the collapse into a single giant community even when μ is as high as 0.6.
- Compared with state‑of‑the‑art methods such as Louvain, Infomap, and OSLOM, roLPA attains comparable or slightly higher NMI and modularity scores while preserving the near‑linear runtime of LPA.
- In real networks with many bridge nodes (e.g., social media graphs), roLPA produces clearer community boundaries that align better with known ground‑truth groups.
Limitations and future work
The role‑score formulation introduces a few hyper‑parameters (e.g., clustering‑coefficient thresholds) whose values affect performance; the current study selects them empirically. Scaling to networks with hundreds of millions of nodes may stress memory due to storing role information, suggesting a need for distributed or streaming implementations. Finally, dynamic networks are not addressed; extending roLPA to handle continuous edge updates and evolving roles is identified as a promising direction.
Conclusion
By explicitly modeling node roles, roLPA mitigates the randomness that plagues classic LPA, curtails the formation of oversized communities, and yields more stable and accurate community partitions. The approach offers a practical, near‑linear‑time alternative for large‑scale network analysis and opens new avenues for role‑aware graph mining techniques.
Comments & Academic Discussion
Loading comments...
Leave a Comment