Disk storage management for LHCb based on Data Popularity estimator
This paper presents an algorithm providing recommendations for optimizing the LHCb data storage. The LHCb data storage system is a hybrid system. All datasets are kept as archives on magnetic tapes. The most popular datasets are kept on disks. The algorithm takes the dataset usage history and metadata (size, type, configuration etc.) to generate a recommendation report. This article presents how we use machine learning algorithms to predict future data popularity. Using these predictions it is possible to estimate which datasets should be removed from disk. We use regression algorithms and time series analysis to find the optimal number of replicas for datasets that are kept on disk. Based on the data popularity and the number of replicas optimization, the algorithm minimizes a loss function to find the optimal data distribution. The loss function represents all requirements for data distribution in the data storage system. We demonstrate how our algorithm helps to save disk space and to reduce waiting times for jobs using this data.
💡 Research Summary
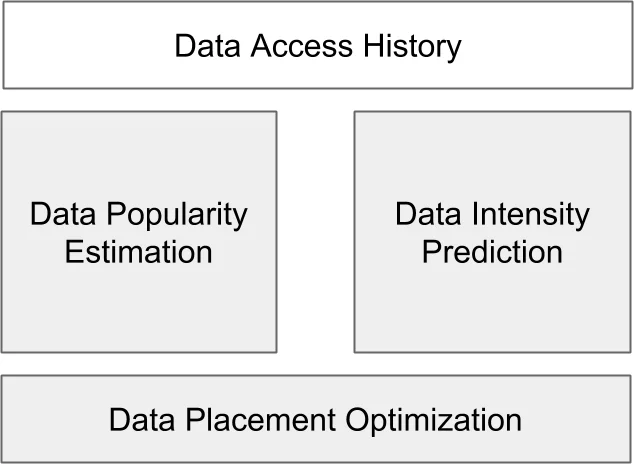
The paper addresses the challenge of efficiently managing the hybrid storage system (disk + tape) used by the LHCb experiment, where all datasets are archived on magnetic tape and only the most frequently accessed datasets are kept on faster but more expensive disk storage. The authors propose a three‑module algorithm that (1) predicts the future popularity of each dataset, (2) forecasts its future usage intensity, and (3) determines an optimal placement (disk vs. tape) and the number of disk replicas for each dataset by minimizing a cost‑based loss function.
Popularity Estimator – The first module treats popularity prediction as a supervised classification problem. Using the last 26 weeks of weekly access counts, datasets are labeled “popular” (0) if they have been accessed at least once, otherwise “unpopular” (1). From the first 78 weeks of history the authors engineer a set of ten descriptive features (e.g., number of active weeks, weeks since last access, inter‑access interval statistics, mass‑center of the time series, etc.) and combine them with static metadata (size, file type, creation week, etc.). A Gradient Boosting Classifier is trained on half of the data and validated on the other half, producing for each dataset a probability of being “unpopular”. This probability is then transformed into a popularity score that serves as a threshold for disk removal.
Intensity Predictor – Because the LHCb usage series are sparse, classic parametric time‑series models (ARIMA, ANN, etc.) are unsuitable. The authors therefore apply a non‑parametric Nadaraya‑Watson kernel smoother with a Gaussian kernel, selecting the bandwidth via Leave‑One‑Out cross‑validation (maximum width 30 weeks). After smoothing, a rolling‑mean filter is applied; the resulting value at the most recent week is taken as the predicted weekly usage intensity (I_i).
Placement Optimizer – The core of the method is a loss function that captures three cost components: (i) disk storage cost (C_{\text{disk}}) multiplied by the size of each replica and a penalty term (\alpha I_i) that discourages too few replicas, (ii) tape storage cost (C_{\text{tape}}) for datasets kept only on tape, and (iii) a “miss” cost (C_{\text{miss}}) incurred when a dataset removed from disk must be restored from tape. The binary variable (\delta_i) indicates whether dataset (i) stays on disk, and (m_i) marks a mis‑classification (disk removal followed by later use). The optimal number of replicas for a dataset kept on disk is derived analytically as (R_{p,i}^{\text{opt}} = \sqrt{\alpha I_i}). The optimizer searches for the popularity threshold and replica numbers that minimize the total loss.
Experimental Evaluation – The authors evaluate the approach on 7 375 datasets that were created and first accessed before week 78. The first 78 weeks of each dataset’s weekly access counts are used as input, while the last 26 weeks serve as a test period. Cost parameters are set to emphasize limited disk space: (C_{\text{disk}}=100), (C_{\text{tape}}=1), (C_{\text{miss}}=2000). Download time is modeled with per‑GB disk and tape transfer rates (0.1 h/GB and 3 h/GB) and a fixed tape‑to‑disk restoration overhead of 24 h.
Two baselines are compared: (a) a simple Last‑Recently‑Used (LRU) policy that removes any dataset not accessed in the last (N) weeks, and (b) the proposed method with different maximum replica limits (4 and 7). Results show that both methods achieve similar disk‑space savings (≈60 % of the original), but the proposed method dramatically reduces the number of “wrong removings” (datasets mistakenly deleted from disk) from thousands (LRU) to single‑digit counts. Moreover, with a maximum of 7 replicas the method can save up to 40 % of disk space while cutting overall download time by up to 30 % compared with the baseline.
Conclusions and Outlook – The study demonstrates that even with sparse usage histories, a combination of engineered time‑series features, non‑parametric smoothing, and a cost‑driven optimization framework can effectively balance storage cost, data availability, and access latency in a large‑scale scientific experiment. The explicit loss function allows operators to tune the trade‑off between replica redundancy (controlled by (\alpha)) and restoration penalties, making the approach adaptable to evolving resource constraints. Future work could extend the framework to online learning for real‑time adaptation, incorporate multi‑site replication strategies, and refine the miss‑cost model based on actual restoration workloads. The authors also provide a Python implementation and a web service for reproducible experimentation.
Comments & Academic Discussion
Loading comments...
Leave a Comment