Multi-Way, Multilingual Neural Machine Translation with a Shared Attention Mechanism
We propose multi-way, multilingual neural machine translation. The proposed approach enables a single neural translation model to translate between multiple languages, with a number of parameters that grows only linearly with the number of languages. This is made possible by having a single attention mechanism that is shared across all language pairs. We train the proposed multi-way, multilingual model on ten language pairs from WMT'15 simultaneously and observe clear performance improvements over models trained on only one language pair. In particular, we observe that the proposed model significantly improves the translation quality of low-resource language pairs.
💡 Research Summary
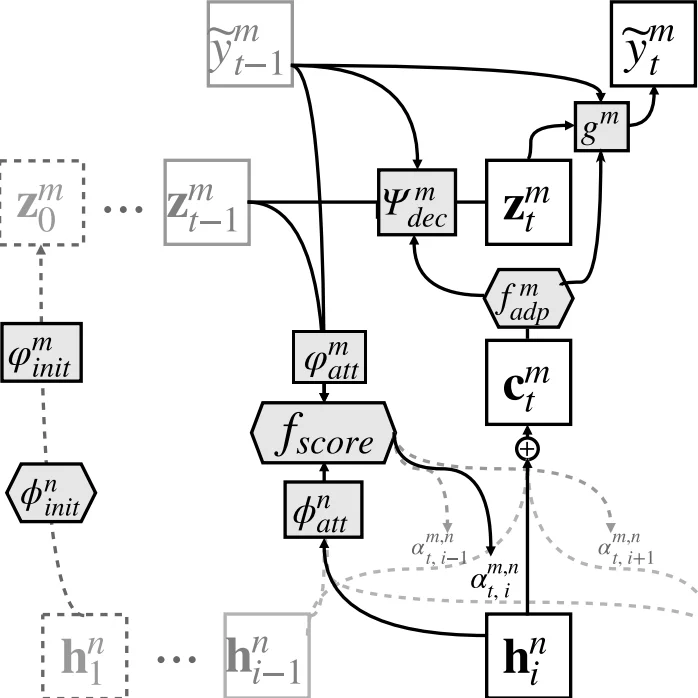
The paper introduces a multi‑way, multilingual neural machine translation (NMT) architecture that shares a single attention mechanism across all language pairs while keeping the number of parameters linear in the number of languages. Traditional attention‑based NMT models require a separate attention module for each source‑target pair because the alignment function is considered language‑specific. This leads to a quadratic growth of parameters (O(L²) for L languages) and limits the ability of the model to transfer knowledge between language pairs, especially for low‑resource languages.
To overcome these limitations, the authors propose a model consisting of N encoders (one per source language) and M decoders (one per target language) that all connect to a common attention scorer f_score. Each encoder is a bidirectional recurrent network (LSTM or GRU) that produces a sequence of context vectors. Since the dimensionality of these vectors may differ across languages, a linear projection (Wₙ^adp, bₙ^adp) maps them into a shared space of dimension d. An additional non‑linear transformation φₙ^att (implemented as element‑wise tanh) prepares the vectors for the shared attention. The shared attention computes relevance scores e_{t,i}=f_score(h_i, z_{t‑1}, E_y
Comments & Academic Discussion
Loading comments...
Leave a Comment