Strategies and Principles of Distributed Machine Learning on Big Data
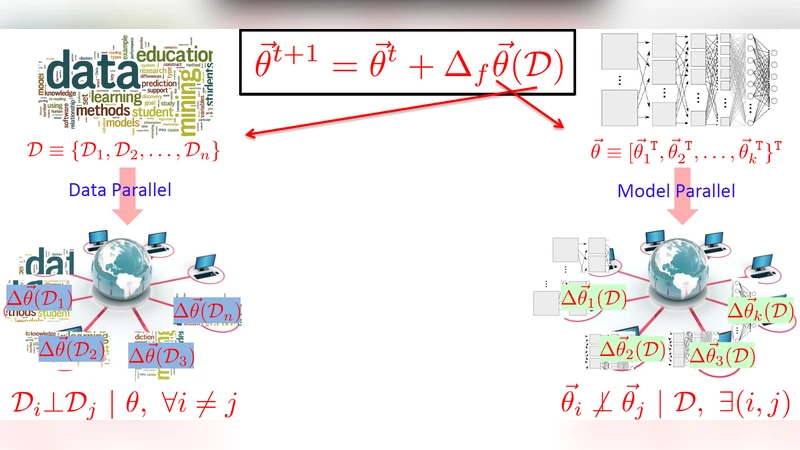
The rise of Big Data has led to new demands for Machine Learning (ML) systems to learn complex models with millions to billions of parameters, that promise adequate capacity to digest massive datasets and offer powerful predictive analytics thereupon. In order to run ML algorithms at such scales, on a distributed cluster with 10s to 1000s of machines, it is often the case that significant engineering efforts are required — and one might fairly ask if such engineering truly falls within the domain of ML research or not. Taking the view that Big ML systems can benefit greatly from ML-rooted statistical and algorithmic insights — and that ML researchers should therefore not shy away from such systems design — we discuss a series of principles and strategies distilled from our recent efforts on industrial-scale ML solutions. These principles and strategies span a continuum from application, to engineering, and to theoretical research and development of Big ML systems and architectures, with the goal of understanding how to make them efficient, generally-applicable, and supported with convergence and scaling guarantees. They concern four key questions which traditionally receive little attention in ML research: How to distribute an ML program over a cluster? How to bridge ML computation with inter-machine communication? How to perform such communication? What should be communicated between machines? By exposing underlying statistical and algorithmic characteristics unique to ML programs but not typically seen in traditional computer programs, and by dissecting successful cases to reveal how we have harnessed these principles to design and develop both high-performance distributed ML software as well as general-purpose ML frameworks, we present opportunities for ML researchers and practitioners to further shape and grow the area that lies between ML and systems.
💡 Research Summary
The paper “Strategies and Principles of Distributed Machine Learning on Big Data” addresses the pressing challenge of training machine learning (ML) models that contain millions to billions of parameters on clusters ranging from dozens to thousands of machines. The authors argue that the design of large‑scale ML systems should not be left solely to systems engineers; rather, deep statistical and algorithmic insights from the ML community are essential to achieve both correctness and performance.
The work is organized around four fundamental questions that receive little attention in traditional ML research: (1) how to distribute an ML program across a cluster, (2) how to bridge computation with inter‑machine communication, (3) how to perform that communication, and (4) what exactly should be communicated. By examining the intrinsic properties of ML workloads—error tolerance, dynamic structural dependencies, and non‑uniform convergence—the authors derive a set of design principles that differ markedly from those used for transaction‑oriented workloads such as sorting or database queries.
Key properties of ML programs
- Error tolerance: Approximate updates still lead to convergence, allowing the system to tolerate small numerical errors and to use asynchronous communication without jeopardizing final model quality.
- Dynamic structural dependencies: Relationships among parameters evolve during training, which means static data partitioning is sub‑optimal; instead, the system should adaptively co‑locate highly dependent parameters.
- Non‑uniform convergence: Some parameters converge in a few iterations while others need many more; therefore communication frequency can be reduced for already‑converged parameters, focusing bandwidth on the “hard” parts of the model.
Design principles derived from these properties
-
Distribution strategy – Adopt a parameter‑server (PS) architecture as the backbone, but augment it with hierarchical partitioning of both data and parameters. Work units (mini‑batches, coordinate blocks, topic partitions) are scheduled dynamically based on workload characteristics.
-
Computation‑communication bridge – Use a “compute‑then‑communicate” pattern: workers perform a substantial amount of local computation before synchronizing, and only trigger communication when local updates exceed a significance threshold.
-
Communication model – Move away from strict Bulk‑Synchronous Parallel (BSP) barriers. Instead employ limited‑staleness models such as Stale‑Synchronous Parallel (SSP) or pipelined asynchronous schemes that hide network latency while still providing convergence guarantees.
-
What to communicate – Transmit only the delta (Δ) or sparse updates rather than the full parameter vector. Once a parameter has effectively converged, it can be “frozen” and excluded from further communication, dramatically reducing bandwidth usage.
The paper validates these principles with two concrete case studies. For Lasso regression, a coordinate‑descent algorithm is mapped onto a PS system where each worker updates a block of coefficients and sends only the sparse change to the central server. Experiments show near‑linear speed‑up and communication cost reduced to O(1) per iteration. For large‑scale topic modeling, stochastic gradient descent is combined with a PS that handles the massive word‑topic matrix; the system achieves several‑fold speed‑ups over traditional MapReduce‑style implementations.
A comparative analysis highlights the trade‑offs of existing platforms: Hadoop/Spark provide ease of programming but suffer from BSP‑induced stalls; GraphLab offers a flexible vertex‑programming abstraction but requires non‑trivial rewrites of many ML algorithms. The proposed PS‑centric approach occupies a middle ground, delivering high performance while preserving a relatively simple programming interface.
In the conclusion, the authors outline future research directions: (i) automated detection of dynamic dependencies for smarter partitioning, (ii) rigorous convergence analysis for asynchronous and stale‑synchronous schemes, and (iii) integration with emerging hardware accelerators (GPUs, FPGAs, RDMA networks). Overall, the paper presents a cohesive “ML‑centric” systems design framework that aligns algorithmic properties with hardware realities, offering a practical roadmap for building efficient, scalable distributed ML systems in the era of Big Data.
Comments & Academic Discussion
Loading comments...
Leave a Comment