Serifos: Workload Consolidation and Load Balancing for SSD Based Cloud Storage Systems
Achieving high performance in virtualized data centers requires both deploying high throughput storage clusters, i.e. based on Solid State Disks (SSDs), as well as optimally consolidating the workloads across storage nodes. Nowadays, the only practical solution for cloud storage providers to offer guaranteed performance is to grossly over-provision the storage nodes. The current workload scheduling mechanisms used in production do not have the intelligence to optimally allocate block storage volumes based on the performance of SSDs. In this paper, we introduce Serifos, an autonomous performance modeling and load balancing system designed for SSD-based cloud storage. Serifos takes into account the characteristics of the SSD storage units and constructs hardware dependent workload consolidation models. Thus Serifos is able to predict the latency caused by workload interference and the average latency of concurrent workloads. Furthermore, Serifos leverages an I/O load balancing algorithm to dynamically balance the volumes across the cluster. Experimental results indicate that Serifos consolidation model is able to maintain the mean prediction error of around 10% for heterogeneous hardware. As a result of Serifos load balancing, we found that the variance and the maximum average latency are reduced by 82% and 52%, respectively. The supported Service Level Objectives (SLOs) on the testbed improve 43% on average latency, 32% on the maximum read and 63% on the maximum write latency.
💡 Research Summary
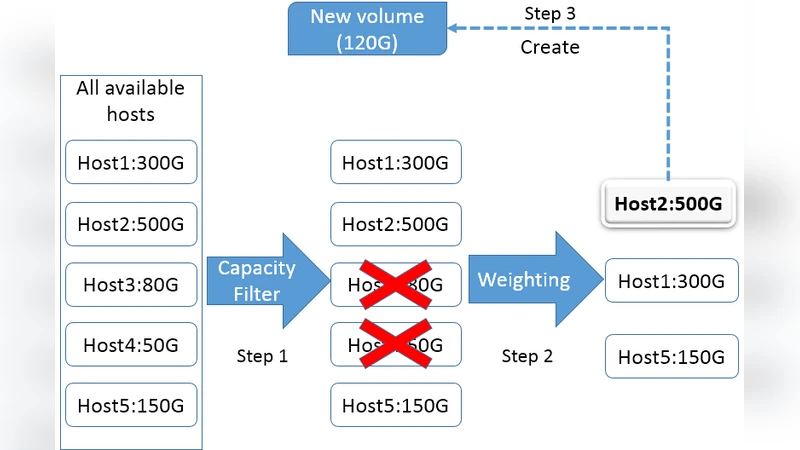
Serifos is an autonomous performance‑modeling and I/O load‑balancing framework designed specifically for SSD‑based cloud block‑storage clusters. The authors begin by highlighting a critical gap in current production schedulers such as OpenStack Cinder’s “Available Capacity” algorithm, which allocate volumes solely on the basis of free space and ignore the performance impact of SSD internal mechanisms (garbage collection, over‑provisioning, write amplification). This omission leads to severe workload interference, unpredictable latency, and frequent SLO violations, forcing providers to over‑provision storage resources.
To address this, Serifos first builds hardware‑specific consolidation models that predict the average latency of a set of concurrent workloads on a given SSD host. The modeling methodology follows SNIA recommendations: each SSD is securely erased, “aged” with a heavy sequential write workload, and then subjected to a comprehensive synthetic benchmark suite generated with Fio. The benchmark explores 660 distinct workload configurations defined by three parameters – write ratio (W, 0‑100 %), randomness (X, 10‑100 %), and block size (S, 4‑256 KB). For each configuration the average request latency (µs) is measured.
Using the collected data, the authors apply multiple linear regression and, where beneficial, polynomial regression with interaction and squared terms. ANOVA tests reveal that W and S are the dominant predictors of latency, while X contributes only marginally. Interaction terms are statistically significant in a few cases but have small coefficients, allowing the final models to remain relatively simple. Six separate models are trained—three for each of the two SSD families (Intel DC S3500 and S3610) and two for different workload intensity intervals—yielding adjusted R² values between 0.94 and 0.99. The mean prediction error (MRE) stays below 10 % across heterogeneous hardware, a substantial improvement over prior SSD single‑workload models that reported errors up to 20 %.
With accurate latency predictions in hand, Serifos introduces a latency‑aware load‑balancing algorithm. At regular intervals it gathers the current I/O load of every storage host, uses the consolidation models to estimate the resulting average and 99th‑percentile latencies for all possible volume placements, and identifies the volume whose migration would most reduce the global latency tail. Before initiating a migration, the algorithm evaluates the cost (network bandwidth consumption, data volatility, migration time) and proceeds only if the expected latency gain outweighs the cost. This approach mirrors VM live migration for compute resources but adapts it to the shared‑resource nature of block storage, where moving a volume can affect multiple tenants.
The experimental evaluation runs on a testbed consisting of Dell R430 servers equipped with a single Intel DC S3500 or S3610 SSD each, Ubuntu 14.04 LTS, and OpenStack Cinder. The baseline scheduler is Cinder’s default Available Capacity. Workloads are executed with an I/O depth of 8 for one‑minute intervals, repeated five times; the fifth iteration’s results are used as the steady‑state measurements. Results show that Serifos maintains an average prediction error of ≈10 %, reduces the overall latency variance by 82 %, and cuts the maximum average latency by 52 % after load balancing. More strikingly, the 99th‑percentile read latency improves by 32 % and write latency by 63 %, translating into a 43 % average latency improvement for the supported SLOs.
The paper acknowledges several limitations. The models are trained offline on a fixed set of synthetic patterns and may not capture abrupt workload spikes or long‑term workload evolution. Only three workload dimensions are considered; additional factors such as I/O depth, queue depth, or multi‑threaded access patterns could further refine predictions. Moreover, the migration decision logic currently assumes a static network environment and does not incorporate predictive network congestion.
Future work is outlined to address these gaps: (1) integrate online learning to continuously update model coefficients as real workloads arrive; (2) extend the feature set to include dynamic I/O queue metrics and tenant‑level QoS parameters; (3) develop a global optimizer that jointly considers storage latency, network latency, and energy consumption; and (4) evaluate the approach on larger, geographically distributed cloud deployments.
In summary, Serifos demonstrates that SSD‑aware performance modeling combined with a latency‑driven load‑balancing policy can dramatically improve the predictability and efficiency of multi‑tenant cloud block storage. By reducing the need for massive over‑provisioning while meeting tighter SLOs, Serifos provides a practical pathway for cloud providers to leverage the full potential of modern enterprise SSDs.
Comments & Academic Discussion
Loading comments...
Leave a Comment