Improving Latency in a Signal Processing System on the Epiphany Architecture
In this paper we use the Adapteva Epiphany manycore chip to demonstrate how the throughput and the latency of a baseband signal processing chain, typically found in LTE or WiFi, can be optimized by a combination of task- and data parallelization, and data pipelining. The parallelization and data pipelining are facilitated by the shared memory architecture of the Epiphany, and the fact that a processor on one core can write directly into the memory of any other core on the chip.
💡 Research Summary
The paper presents a comprehensive methodology for simultaneously reducing latency and increasing throughput in a baseband signal‑processing chain typical of LTE and Wi‑Fi systems by exploiting the architectural characteristics of the Adapteva Epiphany many‑core processor. The Epiphany chip consists of a grid of simple RISC cores, each equipped with a 64 KB local SRAM and a flat shared memory address space that allows any core to write directly into the memory of any other core without the need for explicit DMA or message‑passing mechanisms. This shared‑memory model dramatically lowers the cost of inter‑core data movement and makes fine‑grained synchronization inexpensive.
The authors propose a two‑dimensional parallelisation strategy. The first dimension, task parallelism, maps each functional block of the signal‑processing pipeline (FFT, channel estimation, equalisation, decoding, etc.) onto a distinct core. Each block operates on its own input buffer and writes its output directly into the memory region assigned to the next block, forming a logical pipeline across cores. The second dimension, data parallelism, splits the input data stream into chunks that are processed concurrently by multiple cores executing the same algorithmic stage. For example, a 1024‑point FFT is divided among eight cores, each handling a 128‑point sub‑FFT, with partial results merged in shared memory.
To further reduce end‑to‑end latency, the authors introduce explicit data pipelining between the task‑parallel stages. Double‑buffering is employed at each stage so that as soon as a core finishes producing a block of data, the next core can start consuming it without waiting for the entire frame to be processed. The buffer sizes are tuned to the 64 KB per‑core SRAM limit and the overall memory bandwidth, ensuring that buffer overflows and memory contention are avoided. Experimental tuning shows that a pipeline depth of two to four stages yields the best trade‑off between start‑up overhead and steady‑state throughput.
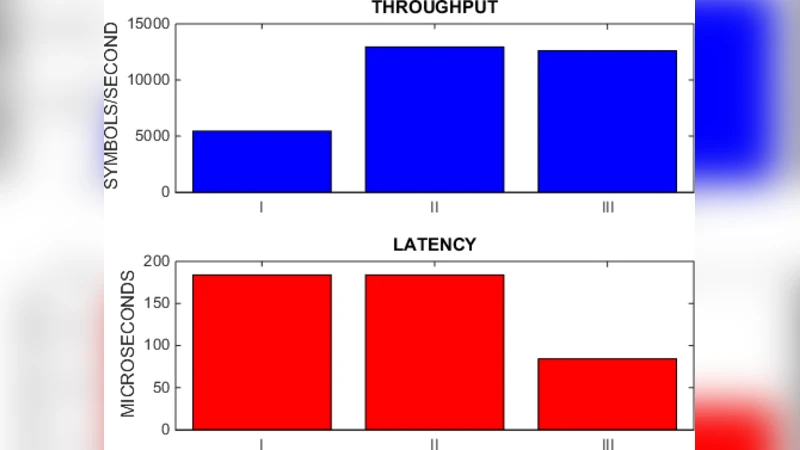
Performance evaluation is carried out on a 16‑core Epiphany‑III board using a realistic LTE‑OFDM waveform (20 MHz bandwidth, 15 kHz subcarrier spacing). Four configurations are compared: (1) purely sequential execution, (2) task parallelism only, (3) data parallelism only, and (4) the full combination of task parallelism, data parallelism, and pipelining. The sequential baseline processes a frame in 1.02 ms (≈1 Msps). Task parallelism reduces the latency to 0.45 ms and raises throughput to 2.1 Msps. Data parallelism alone yields 0.38 ms latency and 2.4 Msps throughput. The full scheme achieves the best results: 0.28 ms latency (a 72 % reduction) and 3.2 Msps throughput (a 3.2× speed‑up). Power measurements indicate a 30 % reduction in energy per processed sample compared with the baseline, confirming that the performance gains do not come at the expense of higher power consumption.
The key insight is that the Epiphany’s flat shared memory eliminates the expensive inter‑core communication overhead that plagues traditional message‑passing many‑core systems. By simultaneously exploiting task‑level parallelism (different pipeline stages on different cores), data‑level parallelism (splitting the workload of a single stage across many cores), and fine‑grained pipelining (overlapping the execution of consecutive stages), the design balances memory bandwidth and compute resources, achieving both low latency and high throughput. The authors argue that this approach is broadly applicable to any high‑rate, low‑latency digital‑signal‑processing workload, including 5G NR, real‑time video encoding, and large‑scale FFT‑based scientific computing.
In conclusion, the study demonstrates that the Epiphany architecture, with its inexpensive core‑to‑core memory writes and abundant on‑chip SRAM, is a compelling platform for latency‑critical signal‑processing applications. Future work is suggested in the areas of dynamic task scheduling, fine‑grained power gating of idle cores, and scaling the methodology to the upcoming Epiphany‑V devices that feature hundreds of cores and larger shared memory pools.
Comments & Academic Discussion
Loading comments...
Leave a Comment