Listen, Attend, and Walk: Neural Mapping of Navigational Instructions to Action Sequences
We propose a neural sequence-to-sequence model for direction following, a task that is essential to realizing effective autonomous agents. Our alignment-based encoder-decoder model with long short-term memory recurrent neural networks (LSTM-RNN) translates natural language instructions to action sequences based upon a representation of the observable world state. We introduce a multi-level aligner that empowers our model to focus on sentence “regions” salient to the current world state by using multiple abstractions of the input sentence. In contrast to existing methods, our model uses no specialized linguistic resources (e.g., parsers) or task-specific annotations (e.g., seed lexicons). It is therefore generalizable, yet still achieves the best results reported to-date on a benchmark single-sentence dataset and competitive results for the limited-training multi-sentence setting. We analyze our model through a series of ablations that elucidate the contributions of the primary components of our model.
💡 Research Summary
The paper tackles the problem of translating free‑form natural language navigation instructions into executable action sequences for autonomous agents. Rather than relying on hand‑crafted linguistic resources such as parsers, seed lexicons, or re‑ranking modules, the authors propose a fully end‑to‑end neural architecture that learns directly from paired instruction‑action data. The core of the system is a sequence‑to‑sequence model built from long short‑term memory (LSTM) recurrent networks, organized in an encoder‑decoder framework with a novel multi‑level attention mechanism.
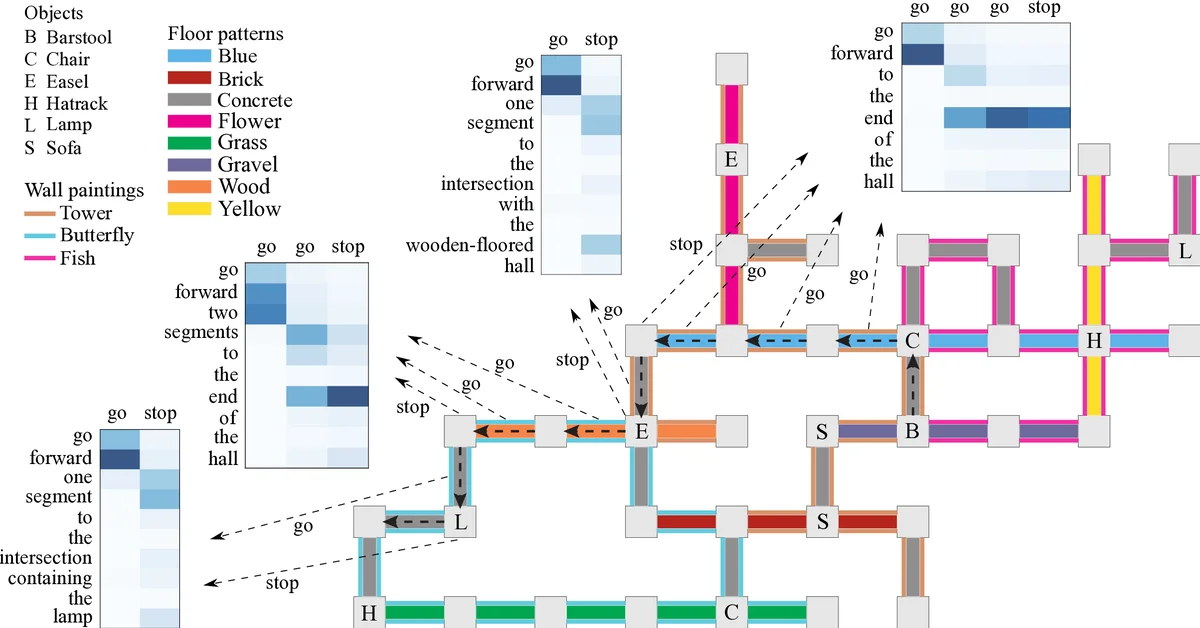
The encoder processes the input sentence bidirectionally. Each word is represented as a one‑hot vector and fed into forward and backward LSTMs, producing hidden annotations that capture both preceding and succeeding context. These annotations are concatenated to form a rich representation for each token. The attention mechanism departs from standard practice by incorporating not only the high‑level hidden states but also the original low‑level word vectors. At each decoding step t, a score βₜⱼ is computed by a single‑layer perceptron that takes the previous decoder state sₜ₋₁, the word vector xⱼ, and the hidden annotation hⱼ as inputs. After a softmax normalization, the resulting weights αₜⱼ define a context vector zₜ as a weighted sum of the concatenated (xⱼ; hⱼ) pairs. This multi‑level context enables the decoder to directly align salient lexical items (e.g., “easel”, “lamp”) with the current perceptual world state.
The decoder is another LSTM that, at each time step, receives three inputs: the current observable world state yₜ (including floor pattern, wall painting, and objects visible at the agent’s line‑of‑sight), the attention‑derived context zₜ, and the previous hidden state sₜ₋₁. It outputs a probability distribution over a small, predefined action vocabulary (e.g., “move forward”, “turn left”, “turn right”). The model is trained to maximize the likelihood of the correct action sequence given the instruction and world states, using cross‑entropy loss and the Adam optimizer.
Experiments are conducted on the benchmark navigation dataset introduced by MacMahon, Stankiewicz, and Kuipers (2006), which contains three virtual worlds populated with patterned hallways, wall paintings, and objects at intersections. The dataset includes noisy, misspelled, and sometimes contradictory human‑written instructions, making it a realistic testbed. Two settings are evaluated: a single‑sentence task with 2,000 training pairs, and a multi‑sentence (paragraph) task with only a few hundred pairs. In the single‑sentence scenario, the proposed model achieves the highest reported accuracy, surpassing previous state‑of‑the‑art approaches that use CCG parsers, lexical induction, and re‑ranking. In the multi‑sentence setting, despite the limited data, the model remains competitive with the best existing systems, all of which depend on additional linguistic resources.
A series of ablation studies isolates the contributions of each component. Removing bidirectionality from the encoder degrades performance, confirming the value of forward and backward context. Excluding the low‑level word vectors from the attention mechanism reduces accuracy by roughly 4–5%, demonstrating the importance of multi‑level alignment. Omitting the world state input from the decoder leads to significant errors in action selection, highlighting the necessity of grounding language in perceptual information. Overall, the analysis shows that the combination of bidirectional encoding, multi‑level attention, and explicit world‑state conditioning is essential for robust instruction following.
The authors conclude that their architecture offers a generalizable, resource‑light solution for grounded language understanding in robotics. By learning the mapping from language to actions without any external linguistic annotations, the system can be more easily transferred to new domains or real‑world robots. Future work is suggested in three directions: (1) deploying the model on physical robots to assess robustness against sensor noise and dynamic environments, (2) extending the attention mechanism to incorporate visual features directly, and (3) exploring hierarchical decoding strategies for longer, more complex plans. The paper thus advances the field of language‑grounded navigation by demonstrating that a carefully designed neural sequence‑to‑sequence model can rival or exceed more elaborate symbolic pipelines.
Comments & Academic Discussion
Loading comments...
Leave a Comment