A Novel Minimum Divergence Approach to Robust Speaker Identification
In this work, a novel solution to the speaker identification problem is proposed through minimization of statistical divergences between the probability distribution (g). of feature vectors from the test utterance and the probability distributions of…
Authors: Ayanendranath Basu, Smarajit Bose, Amita Pal
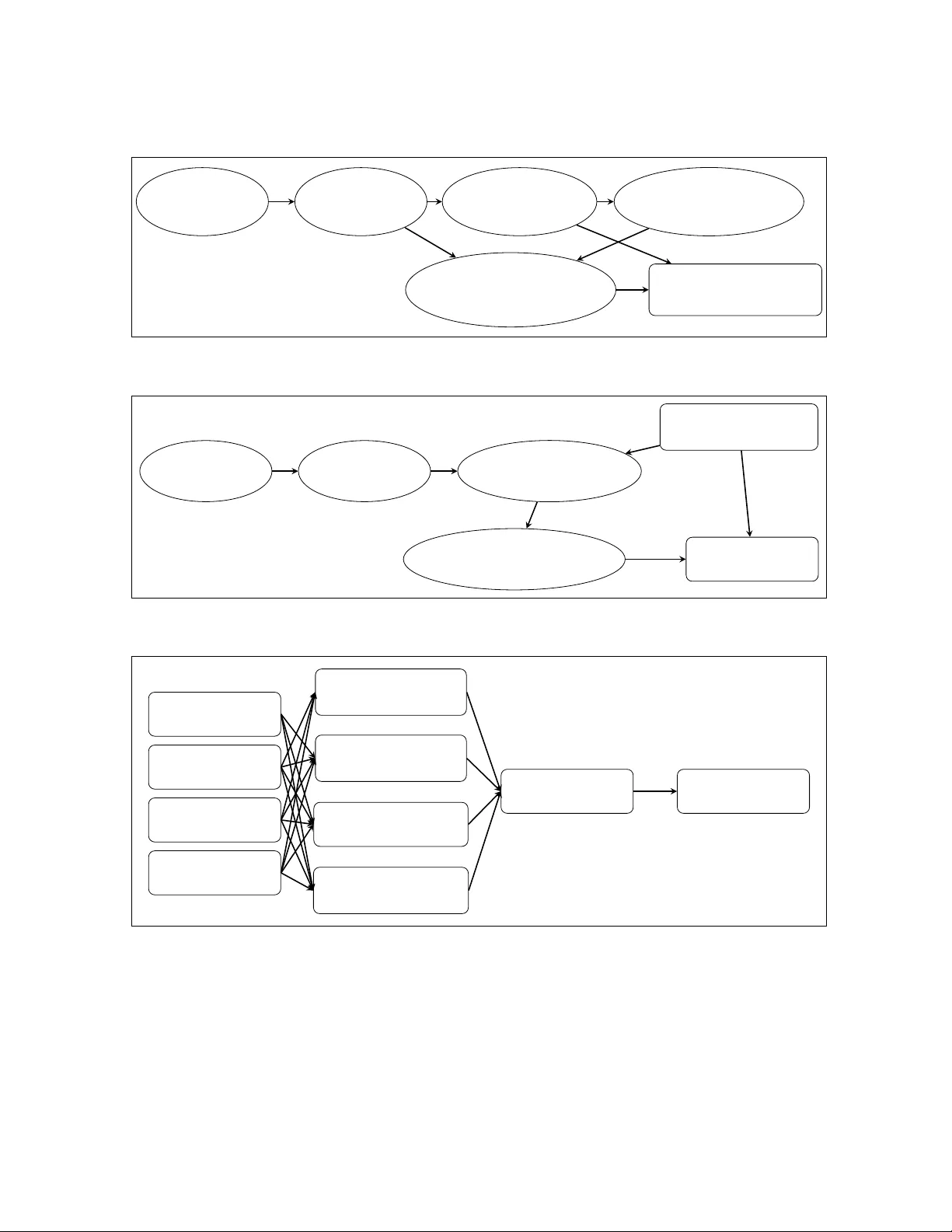
A No v el Minim um Div ergence Approac h to Robust Sp eak er Iden tification Ay anendranath Basu Smara jit Bose Amita P al Anish Mukherjee Debasmita Das In terdisciplinary Statistical Researc h Unit Indian Statistical Institute 203 B. T. Road, Kolk ata 700108, India e-mail: ayanb asu@isic al.ac.in, smar ajit@isic al.ac.in, p amita@isic al.ac.in anishmk9@gmail.c om, deb asmita88@yaho o.c om Abstract In this work, a nov el solution to the speaker identification problem is prop osed through mini- mization of statistical div ergences betw een the probability distribution ( g ) of feature v ectors from the test utterance and the probabilit y distributions of the feature vector corresponding to the sp eak er classes. This approac h is made more robust to the presence of outliers, through the use of suitably mo dified v ersions of the standard div ergence measures. The relev an t solutions to the minim um distance metho ds are referred to as the minimum rescaled mo dified distance estimators (MRMDEs). Three measures w ere considered – the lik eliho o d disparit y , the Hellinger distance and P earson’s c hi-square distance. The prop osed approach is motiv ated b y the observ ation that, in the case of the likelihoo d disparity , when the empirical distribution function is used to estimate g , it b ecomes equiv alent to maximum lik eliho o d classification with Gaussian Mixture Mo dels (GMMs) for sp eaker classes, a highly effective approach used, for example, by Reynolds [22] based on Mel F requency Cepstral Co efficients (MFCCs) as features. Significan t improv ement in classification accuracy is observ ed under this approach on the b enc hmark sp eech corpus NTIMIT and a new bilingual sp eech corpus NISIS, with MF CC features, both in isolation and in combination with delta MF CC features. Moreo v er, the ubiquitous principal comp onent transformation, b y itself and in conjunction with the principle of classifier combination, is found to further enhance the p erformance. 1 In tro duction Automatic sp eaker identification/recognition (ASI/ASR), that is, the automated pro cess of inferring the identit y of a p erson from an utterance made by him/her, on the basis of sp eaker-specific informa- tion em b edded in the corresp onding sp eec h signal, has imp ortan t practical applications. F or example, it can be used to v erify identit y claims made by users seeking access to secure systems. It has great p oten tial in application areas like v oice dialing, secure banking ov er a telephone net work, telephone shopping, database access services, information and reserv ation services, voice mail, securit y con- trol for confidential information, and remote access to computers. Another important application of sp eak er recognition technology is in forensics. Sp eak er recognition, b eing essentially a pattern recognition problem, can b e sp ecified broadly in terms of the features used and the classification technique adopted. F rom exp erience gained ov er the past several y ears from research going on, it has b een p ossible to identify certain groups of features that can b e extracted from the complex speech signal, which carry a great deal of sp eaker-specific information. In conjunction with these features, researc hers hav e also identified classifiers which p erform admirably . Mel F requency Cepstral Coefficients (MFCCs) and Linear Prediction Cepstral Co efficien ts (LPCCs) are the p opularly used features, while Gaussian Mixture Mo dels (GMMs), Hidden Marko v Models (HMMs), V ector Quantization (V Q) and Neural Netw orks are some of the more successful sp eaker models/classification to ols. An y go o d review article on sp eak er recognition (for example, [6, 11, 15]), contains details and citations ab out more than a few of these features and mo dels. It is quite apparent that m uch of the researc h inv olv es juggling v arious features and sp eak er mo dels in different combinations to get new ASR metho dologies. Reynolds [22, 22] prop osed a sp eaker recognition system based on MFCCs as features and GMMs as sp eaker models and, b y implemen ting it on the b enchmark data sets TIMIT [9, 12] and NTIMIT [12], demonstrated that it w orks almost fla wlessly on clean sp eech (TIMIT) and quite w ell on noisy telephone speech (NTIMIT). This successful application of GMMs for mo deling sp eaker iden tity is motiv ated by the in terpretation that the Gaussian components represen t some general speaker-dependent sp ectral shap es, and also b y the capability of mixtures to mo del arbitrary densities. This approach is one of the most effectiv e approac hes av ailable in the literature, as far as accuracy on large speaker databases is concerned. In this pap er, a no v el approac h has b een prop osed for solving the sp eak er iden tification problem through the minimization, ov er all K sp eaker classes, of statistical divergences [2] b etw een the (h y- p othetical) probabilt y distribution ( g ) of feature vectors from the test utterance and the probability distribution f k of the feature v ector corresp onding to the k -th speaker class, k = 1 , 2 , . . . , K . The motiv ation for this approac h is pro vided by the observ ation that, for one suc h measure, namely , the Lik eliho o d Disparity , it (the prop osed approac h) b ecomes equiv alen t to the highly successful maxi- m um lik eliho o d classification rule based on Gaussiam Mixture Mo dels for speaker classes [22] with Mel F requency Cepstral Co efficients (MFCCs) as features. This approac h has b een made more robust to the p ossible presence of outlying observ ations through the use of robustified versions of asso ci- ated estimators. Three different div ergence measures ha ve b een considered in this work, and it has b een established empirically , with the help of a couple of sp eech corp ora, that the proposed metho d outp erforms the baseline metho d of Reynolds, when Mel F requency Cepstral Co efficien ts (MF CCs) are used as features, b oth in isolation and in com bination with delta MFCC features (Section 5.3). Moreo ver, its p erformance is found to b e enhanced significan tly in conjunction with the follo wing 2 t wo-pronged approach, which had b een shown earlier [18] to impro ve the classification accuracy of the basic MFCC-GMM sp eaker recognition system of Reynolds: • Inc orp or ation of the individual c orr elation structur es of the fe atur e sets into the mo del for e ach sp e aker : This is a significant aspect of the sp eaker models that Reynolds had ignored by assum- ing the MFCCs to b e independent. In fact, this has giv en rise to the misconception that MFCCs are uncorrelated. Our ob jectiv e is achiev ed by the simple device of the Principal Component T ransformation (PCT) [21]. This is a linear transformation derived from the cov ariance matrix of the feature vectors obtained from the training utterances of a giv en sp eaker, and is applied to the feature v ectors of the corresponding sp eak er to make the individual co efficients uncorre- lated. Due to differences in the correlation structures, these transformations are also differen t for different speakers. The GMMs are fitted on the feature vectors transformed b y the principal comp onen t transformations rather than the original featuress. F or testing, to determine the lik eliho o d v alues with respect to a giv en target sp eak er mo del, the feature v ectors computed from the test utterance are rotated b y the principal comp onen t transformation corresp onding to that sp eaker. • Combination of differ ent classifiers b ase d on the MFCC- GMM mo del: Differen t classifiers are built by v arying some of the parameters of the mo del. The p erformance of these classifiers in terms of classification accuracy also v aries to some extent. By com bining the decisions of these classifiers in a suitable wa y , an aggregate classifier is built whose p erformance is b etter than an y of the constituent classifiers. The application of Principal Comp onen t Analysis (PCA) is certainly not new in the domain of sp eak er recognition, though the primary aim has been to implement dimensionalit y reduction [7, 13, 23, 24, 16, 26] for impro ving p erformance. The nov elt y of the approach used here (prop osed by P al et al . [18] lies in the fact that the principle underlying PCA has b een used to make the features uncorrelated, without trying to reduce the size of the data set. T o emphasize this feature, we refer to our implemen tation as the Principal Comp onent T ransformation (PCT) and not PCA. Moreo v er, another unique feature of our approac h is as follows. W e compute the PCT for eac h sp eaker on the training utterances and store them. GMMs for a sp eak er are estimated based on the feature v ectors transformed by its PCT. F or testing, unlike what has b een rep orted in other w ork, in order to determine the likelihoo d v alues with resp ect to a giv en target sp eak er mo del, the MF CCs computed from the test utterance are rotated by the PCT for that target sp eaker, and not the PCT determined from the test signal itself. The motiv ation is that if the test signal comes from this target sp eak er, when transformed by the corresp onding PCT, it will matc h the mo del b etter. The principle of com bination or aggregation of classifiers for impro v emen t in accuracy has b een used successfully in the past for sp eaker recognition, for example, by Besacier and Bonastre [3], Altin¸ ca y and Demirekler [1], Hanil¸ ci and Erta¸ s [13], T rab elsi and Ben Ayed [25]. In the approach prop osed 3 in this w ork, different type of classifiers are not com bined. Rather, a few GMM-based classifiers are generated and their decisions are com bined. This is somewhat similar to the principle of Bagging [4] or R andom F or ests [5]. The proposed approach has b een implemen ted on the b enchmark sp eech corpus, NTIMIT, as well as a relatively new bilingual sp eech corpus NISIS [19], and noticeable impro v ement in recognition p erformance is observ ed in b oth cases, when Mel F requency Cepstral Coefficients (MF CCs) are used as features, b oth in isolation and in com bination with delta MF CC features. The paper is organized as follo ws. The minimum distance (or div ergence) approach is introduced in the follo wing section, together with a few div ergence measures. The prop osed approac h is presen ted in Section 3, which also outlines the motiv ation for it. Section 4 giv es a brief description of the sp eech corp ora used, namely , NISIS and NTIMIT, and contains results obtained b y applying the prop osed approac h on them, whic h clearly establish its effectiveness. Section 5 summarizes the contribution of this w ork and prop oses future directions for researc h in this area. 2 Div ergence Measures Let f and g b e t w o probabilit y densit y functions. Let the Pearson’s residual [17] for g , relativ e to f , at the v alue x b e defined as δ ( x ) = g ( x ) f ( x ) − 1 . The residual is equal to zero at suc h v alues where the densities g and f are identical. W e will consider div ergences b etw een g and f defined b y the general form ρ C ( g , f ) = Z x C ( δ ( x )) f ( x ) d x , (1) where C is a thrice differentiable, strictly con vex function on [ − 1 , ∞ ), satisfying C (0) = 0. Sp ecific forms of the function C generate differen t div ergence measures. In particular, the lik eliho o d disparit y (LD) is generated when C ( δ ) = ( δ + 1) log ( δ + 1) − δ . Thus, LD ( g , f ) = Z x [( δ ( x ) + 1) log( δ ( x ) + 1) − δ ( x )] f ( x ) d x whic h ultimately reduces up on simplification to LD ( g , f ) = Z x log( δ ( x ) + 1) dG = Z x log( g ( x )) dG − Z x log( f ( x )) dG, (2) where G is the distribution function corresp onding to g . F or the Hellinger distance (HD), since C ( δ ) = 2( √ δ + 1 − 1) 2 , w e ha ve H D ( g , f ) = 2 Z x s g ( x ) f ( x ) − 1 2 f ( x ) d x , 4 whic h can be expressed (upto an additiv e constan t independent of g and f ) as H D ( g , f ) = − 4 Z x 1 p δ ( x ) + 1 dG. (3) F or P earson’s c hi-square (PCS) divergence, C ( δ ) = δ 2 / 2, so P C S ( g , f ) = 1 2 Z x g ( x ) f ( x ) − 1 2 f ( x ) d x , whic h simplifies (upto an additiv e constant indep endent of g and f ) to P C S ( g , f ) = 1 2 Z x δ ( x ) + 1 dG. (4) The divergences within the general class describ ed in (1) hav e b een called disparities [2, 17]. The LD, HD and the PCS denote three prominen t mem b ers of this class. 2.1 Minim um Distance Estimation Let X 1 , X 2 , . . . , X n represen t a random sample from a distribution G ha ving a probabilit y densit y function g with resp ect to the Leb esgue measure. Let ˆ g n represen t a densit y estimator of g based on the random sample. Let the parametric mo del family F , which mo dels the true data-generating distribution G , be defined as F = { F θ : θ ∈ Θ ⊆ I R p } , where Θ is the parameter space. Let G denote the class of all distributions having densities with resp ect to the Leb esgue m easure, this class b eing assumed to b e conv ex. It is further assumed that b oth the data-generating distribution G and the mo del family F b elong to G . Let g and f θ denote the probability densit y functions corresp onding to G and F θ . Note that θ may represent a contin uous parameter as in usual parametric inference problems of statistics, or it ma y b e discrete-v alued, if it denotes the class lab el in a classification problem lik e speaker recognition. The minimum distance estimation approac h for estimating the parameter θ in v olv es the determination the element of the mo del family which pro vides the closest match to the data in terms of the distance (more generally , div ergence) under consideration. That is, the minimum distance estimator ˆ θ of θ based on the div ergence ρ C is defined by the relation ρ C ( ˆ g n , f ˆ θ ) = min θ ∈ Θ ρ C ( ˆ g n , f θ ) . When we use the likelihoo d disparity (LD) to assess the closeness b etw een the data and the mo del densities, we determine the elemen t f θ whic h is closest to g in terms of the likelihoo d disparity . In this case the procedure, as we hav e seen in Equation (12), b ecomes equiv alen t to the c hoice of the elemen t f θ whic h maximizes R x log( f θ ( x )) dG ( x ) . As g (and the corresp onding distribution function G ) is unkno wn, w e need to optimize a sample based version of the ob jective function. While in 5 general this will require the construction of a kernel density estimator ˆ g (or an alternative densit y estimator), in case of the likelihoo d disparit y this is pro vided b y simply replacing the differen tial dG with dG n , where G n is the empirical distribution function. The pro cedure based on the minimization of the ob jective function in Equation (2) then further simplifies to the maximization of 1 n n X i =1 log f θ ( X i ) whic h is equiv alent to the maximization of the log likelihoo d. The ab ov e demonstrates a simple fact, well-kno wn in the densit y-based minimum distance literature or in information theory , but not w ell-p erceiv ed b y most scientists including many statisticians: the maximization of the log-lik eliho o d is equiv alen tly a minimum distance pro cedure. This provides our basic motiv ation in this pap er. Although we base our numerical work on the three divergences considered in the previous section, our primary inten t is to study the general class of minim um distance pro cedures in the sp eech-recognition con text such that the maximum lik eliho o d pro cedure is a sp ecial case of our approach. Man y of the other divergences within the class generated b y Equation (1) also hav e equiv alent ob jective functions that are to b e maximized to obtain the solution and hav e simple in terpretations. Ho wev er, in one resp ect the lik eliho o d disparity is unique. It is the only div ergence in this class where the sample based version of the ob jective function may b e created b y the simple use of the empirical and no other nonparametric densit y estimation is required. Observ e that both in Equations (3) and (4), the integrand in vol v es δ ( x ), and therefore a densit y estimate for g is required ev en after replacing dG b y dG n . 2.2 Robustified Minim um Distance Estimators When the div ergence ρ C ( ˆ g n , f θ ) is differen tiable with resp ect to θ , the minim um distance estimator ˆ θ of θ based on the divergence ρ C is obtained by solving the estimating equation − ∇ ρ C ( ˆ g n , f θ ) = Z x A ( δ ( x )) ∇ f θ ( x ) dx = 0 , (5) where the function A ( δ ) is defined as A ( δ ) = C 0 ( δ )( δ + 1) − C ( δ ) . If the function A ( δ ) satisfies A (0) = 0 and A 0 (0) = 1 then it is termed the Residual Adjustmen t F unction (RAF) of the divergence. Here ∇ denotes the gradient op erator with resp ect to θ , and C 0 ( · ) and A 0 ( · ) represen t the respective deriv atives of the functions C and A with respect to their argumen ts. 6 Since the estimating equations of the differen t minim um distance estimators differ only in the form of the residual adjustment function A ( δ ), it follo ws that the prop erties of these estimators m ust b e determined b y the form of the corresp onding function A ( δ ). Since A 0 ( δ ) = ( δ + 1) C 00 ( δ ) and, as C ( · ) is a strictly conv ex function on [ − 1 , ∞ ), A 0 ( δ ) > 0 for δ > 1; hence A ( · ) is a strictly increasing function on [1 , ∞ ). Geometrically , the RAF is the most imp ortan t to ol to demonstrate the general b ehaviour or the heuristic robustness properties of the minim um distance estimators corresp onding to the class defined in (1). A damp ened resp onse to increasing p ositive δ will ensure that the RAF shrinks the effect of large outliers as δ increases, thus providing a strategy for making the corresp onding minimum distance estimator robust to outliers. F or the lik eliho o d disparity (LD), C ( δ ) is unbounded for large pos itiv e v alues of the residual δ . and the corresponding estimating equation is giv en b y , −∇ LD ( g , f θ ) = Z x δ ∇ f θ = 0 . So, the residual adjustment function (RAF) for LD, A LD ( δ ) = δ , increases linearly in δ . Thus, to damp en the effect of outliers, a mo dified A ( δ ) function could b e used, whic h is defined as A ( δ ) = 0 for δ ∈ [ − 1 , α ] ∪ [ α ∗ , ∞ ); δ for δ ∈ ( α, α ∗ ) . (6) This eliminates the effect of large δ residuals b eyond the range ( α, α ∗ ). This prop osal is in the spirit of the trimmed mean. The C ( δ ) function for the mo dified LD (MLD) reduces to C M LD ( δ ) = 0 for δ ∈ [ − 1 , α ] ∪ [ α ∗ , ∞ ); ( δ + 1) log( δ + 1) − δ for δ ∈ ( α, α ∗ ) . (7) Similarly , the RAF for the Hellinger distance is A H D = 2( √ δ + 1 − 1), which to o is un b ounded for large v alues of δ , in spite of its lo cal robustness prop erties. T o obtain a robustified estimator, the RAF is mo dified to A ( δ ) = 0 for δ ∈ [ − 1 , α ] ∪ [ α ∗ , ∞ ); 2( √ δ + 1 − 1) for δ ∈ ( α, α ∗ ) , (8) so that the C ( δ ) function for the modified HD (MHD) b ecomes C M H D ( δ ) = 0 for δ ∈ [ − 1 , α ] ∪ [ α ∗ , ∞ ); 2( √ δ + 1 − 1) 2 for δ ∈ ( α, α ∗ ) . (9) 7 F or Pearson’s c hi-square (PCS) divergence, A ( δ ) = δ + δ 2 2 is again un b ounded for large δ , so the RAF is modified to A ( δ ) = 0 for δ ∈ [ − 1 , α ] ∪ [ α ∗ , ∞ ); δ + δ 2 2 for δ ∈ ( α, α ∗ ) , (10) so that the C ( δ ) function for the modified PCS (MPCS) b ecomes C M P C S ( δ ) = 0 for δ ∈ [ − 1 , α ] ∪ [ α ∗ , ∞ ); δ 2 2 for δ ∈ ( α, α ∗ ) . (11) In Figure 1, we ha ve presented the RAFs of our three candidate div ergences, the LD, the HD and the PCS. Notice that they hav e three different forms. The RAF of the LD is linear, that of the HD is conca ve, while the PCS has a conv ex RAF. W e ha v e c hosen our three candidates as representativ es of these three t yp es, so that we hav e a wide description of the divergences of the different t yp es. Figure 1: The Residual Adjustmen t F unctions (RAFs) of the LD, HD and PCS divergences Remark 1 : In the abov e proposals, the approach to robustness is not through the in trinsic b eha viour of the div ergences, but through the trimming of highly discordant residuals. F or small-to-mo derate residuals, the RAFs of these div ergences are not widely different, as all of them relate to the treatment of residuals which do not exhibit extreme departures from the mo del. How ever, these small deviations 8 often pro vide substantial differences in the in the b ehavior of the corresp onding estimators. W e hop e to find out how the small departures exhibited in thes e divergences are reflected in their classification p erformance. Remark 2 : In this pap er, our minimization of the div ergence will b e ov er a discrete set corresp onding to the indices of the existing sp eakers in the database that the new utterance is matched against. Th us w e will not directly use the estimating equation in (5) to ascertain the minimizer. In fact if we restrict ourselves just to the three divergences considered here, there would be no reason to use the residual adjustment function. Ho wev er these divergences are only representativ es of a bigger class, and generally the prop erties of the minim um distance estimators are b est understoo d through residual adjustmen t function. Reconstructing the function C ( · ) from the residual adjustmen t function A ( · ) requires solving an appropriate differen tial equation. When this reconstruction does not lead to a closed form of the C ( · ), one has to directly use the form of the residual adjustmen t function for the minimizations considered in this paper. Remark 3 : An y divergence of the form describ ed in Equation (1) c an b e expressed in terms of sev eral distinct C ( δ ) functions. While they lead to the same divergence when integrated ov er the en tire space, when the range is truncated b y eliminating v ery large and very small residuals, the role of the C ( · ) function b ecomes important. In this section w e ha ve mo dified the lik eliho o d disparit y , the Hellinger distance and the P earson’s chi-square by truncating the C ( · ) functions ha ving the form C LD ( δ ) = ( δ + 1) log ( δ + 1) − δ , C H D = 2( √ δ + 1 − 1) 2 , C P C S = δ 2 2 . One could also mo dify the versions presented in Equations (2), (3) and (4) in a similar spirit and obtain truncated solutions of the minimization problem under study . 3 The Prop osed Approac h It is assumed that probability distribution g for the (unkno wn) sp eaker of the test utterance is un- kno wn. How ev er, it can b e estimated b y ˆ g computed from the test utterance using the feature v ectors x i ’s, corresponding to a n umber of o verlapping short-duration segments in to whic h the segmen t can b e divided. The prop osed approach aims to identify k ∗ , for which f k ∗ is most similar to g in the minimum distanc e sense, where f k , k = 1 , 2 , . . . , K , are the probabilit y mo dels for the K sp eaker classes. In other w ords, the prop osed approac h infers that sp eaker num b er k ∗ has uttered the test sp eec h if k ∗ = arg min k ρ C ( g , f k ) , where ρ C ( · , · ) is some statistical div ergence measure b et w een tw o probabilit y densit y functions, for a giv en c hoice of the function C . If the P earson’s residual for g relativ e to f k at the v alue x b e defined 9 b y δ k ( x ) = g ( x ) f k ( x ) − 1 , then the divergence b etw een g and f k is giv en b y ρ C ( g , f k ) = Z x C ( δ k ( x )) f k ( x ) d x . Let X 1 , X 2 , . . . , X M b e a random sample of size M from g and let us estimate the corresp onding distribution function G b y the empirical distribution function G n ( x ) = 1 M M X i =1 1 ( X i ≤ x ) based on the data x i , i = 1 , . . . , M , where 1 ( A ) is the indicator of the set A . 3.1 Mo dified Minim um Distance Estimation As noted earlier, sp ecific forms of the function C ( · ) generate different divergence measures. In the follo wing, we will describ e the identification of the sp eak er of the test utterance based on the three div ergencees considered in Section 2. 3.1.1 Estimation based on the Lik eliho o d Disparit y The lik eliho o d disparit y (LD) betw een g and f k is (upto an additiv e constan t) LD ( g , f k ) = Z x log( δ k ( x ) + 1) dG = Z x log( g ( x )) dG − Z x log( f k ( x )) dG, (12) Under the proposed approac h, the sp eaker of a test utterance is iden tified by minimizing the lik eliho o d disparit y b etw een g and the f k ’s, that is, as speaker num b er k ∗ if k ∗ = arg min k LD ( g , f k ) = arg max k Z x log( f k ( x )) dG where the second equalit y holds because the first term in the expression of LD ( g , f k ) given in Equation (12) does not in v olve f k . Since R x log( f k ( x )) dG n is an estimator of R x log( f k ( x )) dG , w e ha ve Z x log( f k ( x )) dG ≈ Z x log( f k ( x )) dG n = 1 M M X i =1 log( f k ( x i )) . (13) Therefore, w e will choose the index by maximizing the log-lik eliho o d, whic h giv es ˆ k ∗ = arg max k M X i =1 log( f k ( x i )) = arg max k M Y i =1 f k ( x i ) . (14) 10 3.1.2 Estimation based on the Hellinger Distance Using the form describ ed in Equation (3), the Hellinger distance (HD) betw een g and f k is the same (upto an additive constant) as H D ( g , f k ) = − 4 Z x 1 p δ k ( x ) + 1 dG. (15) By the same reasoning as b efore, the sp eak er of the test utterance is determined to be speaker n um b er k ∗ , b y minimizing the empirical v ersion of the Hellinger distance b etw een g and f k ’s, that is, ˆ k ∗ = arg max k M X i =1 1 p δ k ( x i ) + 1 . (16) W e hav e dropp ed the factor of 1 / M as it has no role in the maximization. Ho w e v er in this case w e ha ve to substitute a density estimate of g in the expression of δ k . Here w e will do this using a Gaussian mixture mo del. 3.1.3 Estimation based on the P earson Chi-square Distance Using the form described in Equation (4), the P earson’s c hi-square b etw een g and f k is the same as (up to an additiv e constan t) P C S ( g , f k ) = 1 2 Z x δ k ( x ) + 1 dG. (17) Th us, as before, sp eak er n umber k ∗ is iden tified as having pro duced the test utterance if ˆ k ∗ = arg min k M X i =1 δ k ( x i ) + 1 . (18) F or each of the three div ergences considered in Sections 3.1.1-3.1.3, we trim the empirical versions of the divergences in the spirit of Section 2.2. This will mean that our mo dified ob jective function for the three divergences (LD, HD and PCS)) are, respectively X i ∈ B log f k ( x i ) , X i ∈ B 1 p δ k ( x i ) + 1 , and X i ∈ B ( δ k ( x i ) + 1) , where the set B may be defined as B = { i | δ k ( x i ) ∈ ( α, α ∗ ) } ; the set B depends on k also, but w e keep the dep endence implicit. In our exp erimentation, we ha ve v aried b oth α and α ∗ in order to con trol the effect of both outliers and inliers and c hose the pair that led to maxim um sp eaker iden tification accuracy . 11 3.2 Minim um Rescaled Mo dified Distance Estimation In our implemen tation of the ab ov e prop osal, we c hose α and α ∗ not as absolutely fixed v alues, but as v alues whic h will pro vide a fixed level of trimming (lik e 10% or 20%). How ever, on account of the v ery high dimensionality of the data and the a v ailabilit y of a relativ ely small n um b er of data points for each test utterance, the estimated densities are often v ery spiky , leading to very high estimated densities at the observed data p oints. This, in turn, often leads to v ery high P earson residuals at suc h observ ations. Since the c hoice of the tuning parameters is related to the trimming of a fixed prop ortion of observ ations, many of the un trimmed observ ations may still b e associated with very high Pearson residuals, whic h mak es the estimation unreliable. As a result, δ b ecomes v ery large at a ma jorit y of the sample p oin ts of the test utterances, which impacts heavily on the divergence measures. F rom (12) we see that, δ k ( x i ) , i = 1 , . . . , M are in logarithmic scale in the expression of LD. In fact Equation (13) shows that the final ob jective function in case of the empirical version of the lik eliho o d disparit y do es not directly depend on the v alues of the P earson residuals at all. Th us, although δ k ( x i ) v alues are large, LD giv es quite sensible divergence v alues. But, in case of the HD as giv en in Eq. (15) and the PCS as given in Eq. (17), we find that the divergence v alues are greatly affected by the large δ k ( x i ) v alues for ma jority of i ’s. Th us, in order to reduce the impact of large δ v alues on the HD and PCS, w e propose a scaled version of the residual δ as follo ws: δ ∗ = sign( δ ) | δ | β (19) where sign( δ ) = 1 for δ ≥ 0 , − 1 for δ < 0 . and β is a p ositive scaling parameter whic h can be used to control the impact of δ . F or a v alue of β significan tly smaller than 1, δ ∗ is scaled do wn to a muc h smaller v alue in magnitude compared to δ . With this mo dification, then, our relev ant ob jective functions for the LD, HD and PCS are X i ∈ B log f k ( x i ) , X i ∈ B 1 p δ ∗ k ( x i ) + 1 , and X i ∈ B ( δ ∗ k ( x i ) + 1) . Notice that the ob jectiv e function for LD remains the same as describ ed in Section 3.1, but the ob jective functions for the HD and PCS are the same only when β = 1. W e will refer to the estimators obtained b y minimizing the rescaled, mo dified ob jective functions as the Minim um Rescaled Mo dified Distance Estimators (MRMDEs) of type I. Only in case of the lik eliho o d disparit y the rescaling part is absent. 12 3.3 Minim um Rescaled Mo dified Distance Estimators (MRMDEs) of T yp e I I In the previous subsection w e hav e described the construction of the MRMDEs of t yp e I. In Remark 3 we hav e mentioned that the same divergence ma y b e constructed by several distinct C ( · ) functions. While they provide iden tical results when integrated ov er the entire space, the mo dified v ersions corresp onding to the differen t C ( · ) functions are necessarily differen t, although the differences are often small. Note that Z C ( δ k ( x )) f k ( x ) d x = Z C ( δ k ( x ) ( δ k ( x ) + 1 dG ( x ) , and using the same principles as in Sections 3.1 and 3.2, we propose the minimization of the ob jectiv e function X i ∈ B C ( δ ∗ ( x i )) ( δ ∗ k ( x i ) + 1) for the ev aluation of the MRMDEs of T yp e I I. Here the relev ant C ( · ) functions corresp onding to the LD, HD and PCS are as defined in Equations (7), (9) and (11). Note that in this case the rescaling has to b e applied to all the three divergences, and not just to HD and PCS only . 4 The Principal Comp onen t T ransformation The idea of principal comp onent transformation (PCT) as prop osed in an earlier w ork [18] has also b een used here. Let the PCT matrix of k th sp eak er be P k , k = 1 , . . . , K and X k ( d × M k ) be the training feature matrix for k th sp eak er, where d = dimension of feature v ector and M k = n umber of feature v ectors. In the training phase, w e first get the transformed feature matrix X ∗ k as, X ∗ k = P k X k (20) and then use it to train f k . No w in the testing phase, we extract the feature matrix from a test utterance represented by X , compute the PCT matrix P and obtain the transformed feature matrix X ∗ as in (20). Then w e train the mo del g using X ∗ . Let us define f ∗ k as, f ∗ k ( x ) = f k ( P k x ) and g ∗ as, g ∗ ( x ) = g ( P x ) It is easy to c heck that f ∗ k , k = 1 , . . . , K and g ∗ are densities, as P k ’s and P are orthonormal matrices. No w, we can use f ∗ k ’s as our true speaker mo dels, g ∗ as the model obtained from the test utterance and 13 obtain the intended sp eaker follo wing the minimum distance based approach described previously . In particular for LD, w e get the new mo dified equation from (13) as, ˆ k ∗ = arg max k M X i =1 log( f ∗ k ( x i )) = arg max k M X i =1 log( f k ( P k x i )) (21) whic h is the same as the PCT-based approac h prop osed in our previous w ork [18]. Flo w charts of the different comp onents (training, testing and classifier com bination) of the prop osed approac h are giv en in Figure 2. 5 Implemen tation and Results The prop osed approach w as v alidated on tw o sp eec h corp ora, whose details are given in the following section. 5.1 ISIS and NISIS: New Sp eec h Corp ora ISIS (an acronym for Indian Statistical Institute Sp eech) and NISIS (Noisy ISIS) [19] are sp eech corp ora, which resp ectively con tain sim ultaneously-recorded microphone and telephone sp eech of 105 sp eak ers, ov er m ultiple sessions, sp ontaneous as well as read, in tw o languages (Bangla and English), recorded in a t ypical office environmen t with mo derate background noise. They were created in the Indian Statistical Institute, Kolk ata, as a part of a pro ject funded by the Departmen t of Information T ec hnology , Ministry of Communications and Information T echnology , Gov ernmen t of India, during 2004-07. The sp eakers had Bangla or another Indian language as their mother tongue, and so were non-nativ e English speakers. Particulars of b oth corpora are giv en b elo w: • Num b er of sp eakers : 105 (53 male + 52 female) • Recording en vironment: mo derately quiet computer ro om • Sessions per sp eak er: 4 (n um b ered I, I I, I I I and IV) • In terv al betw een sessions: 1 w eek to about 2 mon ths • T yp es of utterances in Bangla and English per session: – 10 isolated w ords (randomly dra wn from a sp ecific text corpus, and generally differen t for all speakers and sessions) – answ ers to 8 questions (these answers included dates, phone n um b ers, alphab etic sequences, and a few w ords sp ok en spontaneously) 14 T raining Utterance MF CC V ectors Computation of PCT PC-T ransformed MF CC V ectors Estimation of Sp eak er GMM( f k ) PCT, GMM database for speaker (a) T raining Mo dule PCT, GMM database for Sp eak er T est Utterance MF CC V ectors PCT-transformed MF CC V ectors Estimation of T est Utterance GMM Div ergence Measure PCT GMM GMM (b) T est Mo dule Classifier no. 1 Classifier no. 2 Classifier no. 3 Classifier no. 4 Div ergence from Sp eak er Mo del no. 1 Div ergence from Sp eak er Mo del no. 2 : Div ergence from Sp eak er Mo del no. N Minimizer Classification (c) Classifier Com bination (using 4 classifiers) Figure 2: Flow charts for the three comp onents of the proposed sp eak er iden tification method – 12 sentences (first t wo sen tences common to all sp eakers, the remaining randomly drawn from the text corpus, duration ranging from 3-10 seconds) 15 Th us, for eac h session, there are t w o sets of recordings per sp eak er, one each in Bangla and English, con taining 21 files each. 5.2 The Benc hmark T elephone Sp eec h Corpus NTIMIT NTIMIT [10, 14], like TIMIT [9, 12] is an acoustic-phonetic sp eec h corpus in English, b elonging to the Linguistic Data Consortium (LDC) of the Universit y of P ennsylv ania. TIMIT consists of clean microphone recordings of 10 different read sentences (2 sa , 3 si and 5 sx sentences, some of whic h ha ve ric h phonetic v ariabilit y), uttered by 630 speakers (438 males and 192 females) from eight ma jor dialect regions of the USA. It is c haracterized by 8- kHz bandwidth and lac k of intersession v ariability , acoustic noise, and microphone v ariability or distortion. These features make TIMIT a b enc hmark of c hoice for researchers in sev eral areas of sp eec h processing. NTIMIT, on the other hand, is the sp eech from the TIMIT database play ed through a carb on-button telephone handset and recorded ov er lo cal and long-distance telephone lo ops. This provides sp eech iden tical to TIMIT, except that it is degraded through carb on-button transduction and actual tele- phone line conditions. P erformance differences betw een iden tical exp eriments on TIMIT and NTIMIT are therefore, exp ected to arise primarily from the degrading effects of telephone transmission. Since the ordinary MF CC-GMM mo del achiev es near p erfect accuracy on TIMIT, further impro vemen t seems to b e unlik ely . Therefore we hav e experimented with the NTIMIT database exclusiv ely . 5.3 F eatures Used The features used in this work are the widely-used Mel-frequency cepstral co efficien ts (MF CCs) [8], whic h are co efficien ts that collectiv ely make up a Mel F requency Cepstrum (MFC). The latter is a represen tation of the short-time p ow er sp ectrum of a sound signal, based on a linear cosine transform of a log-energy sp ectrum on a nonlinear mel scale of frequency . It exploits auditory principles, as w ell as the decorrelating property of the cepstrum, and is amenable to comp ensation for con v olution distortion. As such, it has turned out to b e one of the most effective feature representations in sp eec h-related recognition tasks [20]. A given sp eec h signal is partitioned in to ov erlapping segmen ts or frames, and MF CCs are computed for eac h such frame. Based on a bank of K filters, a set of M MF CCs is computed from eac h frame [18]. In addition, the delta Mel-frequency cepstral co efficients [20], which are nothing but the first-order frame-to-frame differences of the MF CCs, ha ve also been used. 16 5.4 Results The ev aluation of the proposed method has been p erformed with the help of 10 recordings per speaker in both corp ora, with the help of tw o differen t data sets: • Dataset 6:4: consisting of the first 6 utterances for training and remaining 4 for testing • Dataset 8:2: consisting of thefirst 8 utterances for training and remaining 2 for testing In addition, ev aluation has b een done on tw o differen t sets of features: • FS-I: 20 MFCCs and 20 delta MFCCs • FS-I I: 39 MFCCs T o implement the ensem ble classification principle, on a n um b er of competing MF CC-GMM classifiers w ere generated b y v arying certain tuning parameters of the generic MFCC-GMM classifier; the v alues of the parameters tuned ( window size , minimum fr e quency and maximum fr e quency ) are men tioned in the tables. The accuracy of the aggregated GMM-MF CC classifier is obtained by combining the lik eliho o d scores of the individual classifier comp onen ts. The b est p erformance observ ed on NTIMIT in our earlier work —citepal2014 has b een summarized in T able I without the PCT (W OPCT) as well as with PCT (WPCT). These will b e used as the baseline for assessing the efficacy of the prop osed approach based on the Minim um Rescaled Mo dified Distance Estimators (MRMDEs), emplo ying all three divergence measures describ ed in Section 3. 5.5 Results with NTIMIT T able II gives the identification accuracy on NTIMIT with the prop osed approach, using all three div ergence measures describ ed in . F rom the latter it is eviden t that significan t impro vemen t has b een ac hieved with MRMDEs based on all three divergence measures. Moreov er, in eac h case, FS-I, which con tains 20 MFCCs and 20 delta MFCCs, gives uniformly b etter p erformance than FS-I I, consisting of 39 MF CCs only . Overall, the best p erformance of 56.19% with the 6:4 dataset an d 67.86% with the 8:2 dataset has been obtained with the LD div ergence, using FS-I. These represent an improv ement of o ver 10% o ver the baseline performance. 5.6 Results with NISIS The b est p erformance observed on NISIS using English recordings from Session I only (referred to as ES-I) in our earlier w ork (Bose et al. , 2014) has b een summarized in T able I without the PCT 17 T able I: Performance of the Baseline MFCC-GMM Sp eaker Identification system Corpus Data set Individual Aggregate W OPCT WPCT W OPCT WPCT NTIMIT 6:4 34.96 42.26 40.36 45.99 8:2 42.41 52.30 49.05 55.63 NISIS (ES-I) 6:4 68.50 85.50 71.50 86.50 8:2 76.00 89.00 77.00 91.50 (W OPCT) as w ell as with PCT (WPCT), while T able I I I gives the identification accuracy on it with the proposed approac h, using all three divergence measures described in Section 3. As in the case of NTIMIT, it is seen that significant impro vemen t has b een ac hieved with MRMDEs in each divergence measure. Moreo ver, as observed earlier with NTIMIT, FS-I giv es uniformly better p erformance than FS-I I, in eac h instance. Again, as b efore 5.5 he best o v erall performance of 92% with the 6:4 dataset and 94.5% with the 8:2 dataset has b een obtained with the LD divergence. These represent an impro vemen t of about 6% o v er the baseline p erformance. It is worth noting that the improv emen t on NISIS is not as dramatic as that with NTIMIT. The explanation is that, the baseline p erformance with NISIS b eing quite high to b egin with, there is not to o m uc h scop e for improving that further. This ma y p ossibly b e another p ositiv e feature of the prop osed approach, namely , its abilit y to provide a relativ ely stronger b o ost to weak er baseline metho ds. 6 Conclusions In the usual approac h of Sp eak er identification, the probabilit y distribution of the MFCC features for each sp eaker is mo deled using Gaussian Mixture Models. F or a test utterance, its MFCC feature v ectors are matc hed with the sp eaker mo dels using the likelihoo d scores deriv ed from eac h mo del. The test utterance is assigned to the model with highest lik eliho o d score. In this work, a no vel solution to the sp eaker identification problem is prop osed through minimization of statistical div ergences b et ween the probabilit y distribution ( g ) of feature v ectors deriv ed from the test utterance and the probabilit y distributions of the feature vectors corresp onding to the sp eaker classes. This approach is made more robust to the presence of outliers, through the use of suitably mo dified versions of the standard div e rgence measures. Three suc h measures were considered – the lik eliho o d disparit y , the Hellinger distance and the P earson c hi-square distance. It turns out that the proposed approach with the likelihoo d disparity , when the empirical distribution 18 function is used to estimate g , becomes equiv alen t to maximum likelihoo d classification with Gaussian Mixture Mo dels (GMMs) for speaker classes, the usual approac h discussed abov e. The usual approac h w as used for example, by Reynolds (1995) yielding excellent results. Significan t improv ement in clas- sification accuracy is observed under the curren t approach on the b enc hmark s p eec h corpus NTIMIT and a new bilingual sp eech corpus NISIS, with MF CC features, both in isolation and in com bination with delta MFCC features. F urther, the ubiquitous principal component transformation, by itself and in conjunction with the principle of classifier com bination, impro v ed the p erformance ev en further. 7 Ac kno wledgemen t The authors gratefully ackno wledge the con tribution of Ms Disha Chakrabarti and Ms Enakshi Saha to this work. References [1] H. Altin¸ cay and M. Demirekler. Sp eaker iden tification by combining multiple classifiers using Dempster-Shafer theory of evidence. Sp e e ch Communic ation , 41:531–547, 2003. [2] Ay anendranath Basu, Hiro yuki Shioy a, and Chanseok P ark. Statistic al Infer enc e: The Minimum Distanc e Appr o ach . CRC Press, Boca Raton, FL, 2011. [3] L. Besacier and J.-F. Bonastre. Subband architecture for automatic sp eker recognition. Signal Pr o c essing , 80:1245–1259, 2000. [4] L. Breiman. Bagging predictors. Machine L e arning , 24:123–140, 1996. [5] L. Breiman. Random forests. Machine L e arning , 45(1):5–32, 2001. [6] J. P . Campb ell (Jr.). Sp eaker recognition: a tutorial. Pr o c e e dings of the IEEE , 85:1437–1462, 1997. [7] J-T Chien and C-W Ting. Speaker identificaton using probabilistic PCA mo del selection. In In INTERSPEECH-2004–ICSLP,8th International Confer enc e on Sp oken L anguage Pr o c essing , pages 1785–1788, Jeju Island, Korea, Octob er 4-8 2004. [8] S. B. Davis and P . Mermelstein. Comparison of parametric representations for monosyllabic w ord recognition in contin uously sp oken sen tences. IEEE T r ansactions on A c oustics, Sp e e ch, and Signal Pr o c essing , 28(4):357–366, 1980. [9] W.M. Fisher, G.R. Do ddington, and K.M. Goudie-Marshall. The D ARP A sp eech recognition researc h database:sp ecifications and status. DARP A Workshop Sp e e ch R e c o gnition , pages 93–99, 1986. 19 [10] W.M. Fisher, G.R. Do ddington, K.M. Goudie-Marshall, C. Janko wski, A. Kaly answ amy , S. Bas- son, and J. Spitz. NTIMIT. Linguistic Data Consortium, Philadelphia, 1993. [11] S. F urui. Recent adv ances in sp eaker recognition. Pattern R e c o gnition L etters , 18:859–872, 1997. [12] J.S. Garofolo, L.F. Lamel, W.M. Fisher, J.G. Fiscus, D.S. Pallett, N.L. Dahlgren, and V. Zue. TIMIT acoustic-phonetic con tinuous speech corpus. Linguistic Data Consortium, Philadelphia, 1993. [13] C. Hanil¸ ci and F. Erta ¸ s. Principal comp onent based classification for text-indep endent speaker iden tification. In Fifth International Confer enc e on Soft Computing, Computing with Wor ds and Per c eptions in System Analysis,De cision and Contr ol , pages 1–4, 2009. [14] C. Janko wski, A. Kalyansw am y , S. Basson, and J. Spitz. NTIMIT: a phonetically balanced, con- tin uous sp eech, telephone bandwidth sp eech database. In International Confer enc e on A c oustics, Sp e e ch, and Signal Pr o c essing (ICASSP-90) , 1990. [15] T. Kinn unen and H. Li. An ov erview of text-independent speaker recognition: from features to sup erv ectors. Sp e e ch Communic ation , 52:12–40, 2010. [16] D. Vijendra Kumar, K. Jyoti, V. Saila ja, and N.M. Ramalingesw ara Rao. T ext indep endent sp eak er identification with principal comp onen t analysis. International Journal of Innovative R ese ar ch in Scienc e, Engine ering and T e chnolo gy , 2:4433–4440, 2013. [17] B. G. Lindsa y . Efficiency v ersus robustness: The case for minimum Hellinger distance and related metho ds. Ann. Statist. , 22:1081–1114, 1994. [18] A. Pal, S. Bose, G. K. Basak, and A. Mukhopadhy ay . Speaker identication b y aggregating Gaussian mixture mo dels (GMMs) based on uncorrelated MF CC-derived features. International Journal of Pattern R e c o gnition and Articial Intel ligenc e , 28(4), 2014. [19] A. P al, S. Bose, M. Mitra, and S. Ro y . ISIS and NISIS: New bilingual dual-c hannel speech cor- p ora for robust sp eaker recognition. In the 2012 International Confer enc e on Image Pr o c essing, Computer Vision and Pattern R e c o gnition (IPCV 2012) , pages 936–939, Las V egas, USA, 2012. [20] T.F. Quatieri. Discr ete-Time Sp e e ch Signal Pr o c essing: Principles and Pr actic e . P earson Edu- cation, Inc., 2008. [21] C.R. Rao. Line ar Statistic al Infer enc e and Its Applic ations . John Wiley & Sons, New Y ork, 2nd (reprin t) edition, 2001. [22] D.A. Reynolds. Large p opulation sp eaker identification using clean and telephone sp eech. IEEE Signal Pr o c essing L etters , 2:46–48, 1995. [23] C. Seo, K.Y. Lee, and J. Lee. GMM based on lo cal PCA for sp eak er identification. Ele ctr onics L etters , 37:1486–1488, 2001. 20 [24] K. Suri Babu, Y. Anitha, and K.K.V.S. Anjana. Dimensionalit y reduction in feature v ector using principal comp onent analysis (PCA) for effective sp eaker recognition. International Journal of Applie d Information Systems , 5:15–17, 2013. [25] I. T rab elsi and D. Ben Ayed. A multi lev el data fusion approach for sp eaker iden tification on telephone sp eech. International Journal of Signal Pr o c essing, Image Pr o c essing and Pattern R e c o gnition , 6:33–41, 2013. [26] W. Zhang, Y. Y ang, and Z. W u. Exploiting PCA classifiers to speaker recognition. In Pr o c e e dings of Int. Joint Confer enc e on Neur al Networks , pages 820–823, 2003. 21 T able II: Iden tification accuracy on NTIMIT under the prop osed approac h Dataset Experi- ment Window Size (ms) Based on C M LD ( δ ) Based on C M H D ( δ ) Based on C M P C S ( δ ) WOPCT WPCT WOPCT WPCT WOPCT WPCT FS-I FS-II FS-I FS-I I FS-I FS-I I FS-I FS-I I FS-I FS-I I FS-I FS-I I 6:4 1 0.020 43.293 40.952 46.547 45.595 41.507 38.095 45.357 43.373 39.246 36.269 43.452 41.031 2 0.030 42.936 39.127 47.142 45.714 41.269 36.389 45.158 43.214 39.603 35.317 43.650 42.222 Combined 52.540 56.190 49.563 53.730 51.667 53.889 8:2 1 0.020 56.031 52.381 59.523 57.539 53.571 49.603 57.539 54.761 51.587 46.587 55.159 50.555 2 0.030 56.270 49.365 60.079 57.539 54.444 46.666 57.301 55.317 52.142 44.365 56.349 53.253 Combined 64.524 67.857 61.429 64.206 63.571 66.111 T able II I: Iden tfication accuracy on NISIS (ES-I) under the prop osed approac h Dataset Experi- ment Min F req (Hz) Max F req (Hz) Window Size (ms) Based on C M LD ( δ ) Based on C M H D ( δ ) Based on C M P C S ( δ ) FS-I FS-II FS-I FS-I I FS-I FS-I I WOPCT WPCT W OPCT WPCT W OPCT WPCT W OPCT WPCT W OPCT WPCT W OPCT WPCT 6:4 1 200 4000 0.020 83.25 88 81.75 85.5 82.25 86.5 78.75 83.5 79 85 78.5 81.75 2 200 4000 0.030 83.75 86.75 79.5 85.5 82.25 84.25 76.25 83.25 80 84.25 75.5 82.25 3 0 5500 0.020 86.5 89.75 82.75 85.75 84.5 89.5 81.75 84 83 88.75 82.5 84.5 4 0 5500 0.030 87.75 89 83 87.75 86 87.75 82 86 82.75 87 81 84.75 1-4 Combined 87.5 92 84.5 88.5 86 89.5 83 86.5 85.5 88.75 83.75 86.5 8:2 1 200 4000 0.020 88.5 93 85 91.5 86.5 90.5 85 88.85 86 91 83.5 86.5 2 200 4000 0.030 89.5 93 85.5 91.5 87 90.5 82.5 89 88 91 82 88 3 0 5500 0.020 90 94.5 89 91.5 86 92 87.5 90 87.5 91.5 86.5 89 4 0 5500 0.030 90.5 92.5 89.5 93 89 90.5 88 90.5 88 90.5 86 91 1-4 Combined 90 94.5 92.5 93.5 88 92.5 88 92.5 89.5 91.5 90 91.5 22
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment