Adaptive algebraic multigrid on SIMD architectures
We present details of our implementation of the Wuppertal adaptive algebraic multigrid code DD-$\alpha$AMG on SIMD architectures, with particular emphasis on the Intel Xeon Phi processor (KNC) used in QPACE 2. As a smoother, the algorithm uses a domain-decomposition-based solver code previously developed for the KNC in Regensburg. We optimized the remaining parts of the multigrid code and conclude that it is a very good target for SIMD architectures. Some of the remaining bottlenecks can be eliminated by vectorizing over multiple test vectors in the setup, which is discussed in the contribution of Daniel Richtmann.
💡 Research Summary
The paper presents a detailed implementation and optimization of the Wuppertal adaptive algebraic multigrid (DD‑α AMG) solver for SIMD architectures, with a focus on the Intel Xeon Phi “Knights Corner” (KNC) used in the QPACE 2 machine. The authors build upon an existing domain‑decomposition (DD) smoother that had already been tuned for the KNC, and concentrate on vectorizing and accelerating the remaining multigrid components: restriction, prolongation, coarse‑grid operator construction, and the Gram‑Schmidt orthonormalization of test vectors.
The multigrid preconditioner is employed inside an outer FGMRES iteration. Each V‑cycle consists of (1) restricting the current residual from the fine grid to a coarse grid using a restriction operator R that preserves low‑mode structure, (2) solving the coarse‑grid system to low precision with an even/odd preconditioned FGMRES, (3) prolongating the coarse solution back to the fine grid using P = R†, and (4) applying the DD smoother to eliminate high‑frequency components. The smoother itself is a SAP‑type block solver that had been previously optimized for KNC.
Key to the SIMD optimisation is the choice of the number of test vectors N_tv. By setting N_tv equal to the SIMD width N_SIMD (16 in single precision on KNC) or to a small multiple thereof (16–32), the authors can pack the same component of all test vectors into a single SIMD register. This enables the restriction operation (Algorithm 6) to be expressed as a series of complex fused‑multiply‑adds where the row index of R runs across the SIMD lanes. Prolongation is analogous but requires a final horizontal sum across the SIMD lanes because the matrix is transposed.
Construction of the coarse‑grid operator D_c follows equation (2.2). The authors first compute D_hh^0 · P for each block, which is essentially a sparse matrix–multiple‑vector product. Algorithm 7 shows how the μ‑direction gauge links and clover term are incorporated via complex FMADs. The result is then restricted with R, again using the multi‑vector SIMD approach. To avoid costly transposes, D_c is stored explicitly (including the Hermitian transpose) and kept in half‑precision, which reduces memory traffic without harming convergence.
For the orthonormalization of the test vectors, classical Gram‑Schmidt is chosen over modified Gram‑Schmidt because it maps more naturally onto SIMD and requires fewer global reductions. A block Gram‑Schmidt variant is employed to improve cache reuse, though the authors note that axpy and dot‑product operations waste roughly half of each SIMD register.
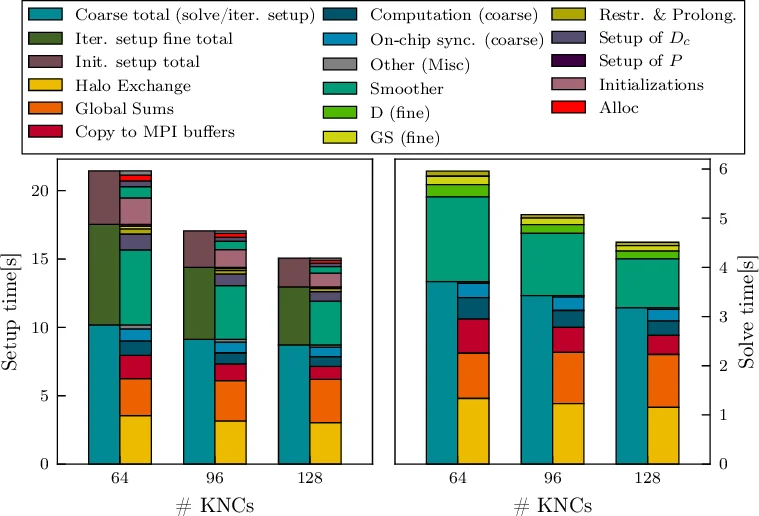
Performance measurements on a single KNC core show speed‑ups of 14.1× for restriction, 8.6× for prolongation, and about 20× for the D_c setup relative to the original Wuppertal code. Table 1 reports these gains, and Figure 1 illustrates the strong‑scaling behavior on up to 128 KNCs for a 48³ × 96 lattice. After optimisation, the multigrid components no longer dominate the runtime; the DD smoother now accounts for roughly one third of the total time, while communication (halo exchange and global sums) in the coarse‑grid solve becomes the primary bottleneck. The authors conclude that DD‑α AMG is an excellent match for SIMD‑based machines, and that further improvements will focus on reducing coarse‑grid communication overhead. The code will be released publicly in the near future.
Comments & Academic Discussion
Loading comments...
Leave a Comment