Stack Exchange Tagger
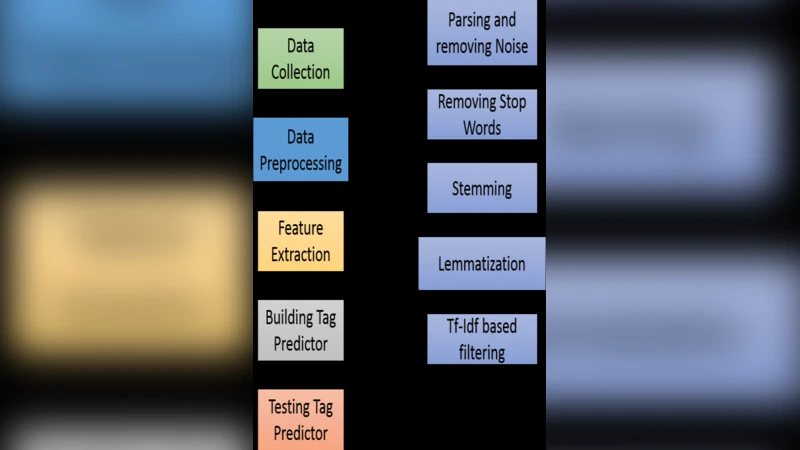
The goal of our project is to develop an accurate tagger for questions posted on Stack Exchange. Our problem is an instance of the more general problem of developing accurate classifiers for large scale text datasets. We are tackling the multilabel classification problem where each item (in this case, question) can belong to multiple classes (in this case, tags). We are predicting the tags (or keywords) for a particular Stack Exchange post given only the question text and the title of the post. In the process, we compare the performance of Support Vector Classification (SVC) for different kernel functions, loss function, etc. We found linear SVC with Crammer Singer technique produces best results.
💡 Research Summary
The paper presents the design, implementation, and evaluation of an automatic tag prediction system for questions posted on the Stack Exchange network, dubbed “Stack Exchange Tagger.” The authors frame the problem as a large‑scale multi‑label text classification task: each question may be associated with several tags, and the goal is to predict the correct set of tags using only the question’s title and body.
Data collection and preprocessing
A corpus of two million questions was scraped from the entire Stack Exchange platform. Each record contains (1) the title, (2) the body (including possible code snippets), and (3) the list of tags assigned by community members. The average number of tags per question is 2.8, and the total tag vocabulary comprises roughly 30 000 distinct tags, exhibiting a long‑tail Zipf‑like distribution. Preprocessing removes HTML markup and code blocks, tokenizes the remaining text using a hybrid approach (Mecab for Korean morphology and standard English tokenizers), filters stop‑words, and applies stemming (Porter for English, morphological stemming for Korean). The cleaned tokens are transformed into TF‑IDF weighted vectors; the resulting feature space exceeds 100 000 dimensions, and L2 normalization is applied to each vector.
Modeling choices
The authors adopt Support Vector Machines (SVM) as the core classifier, exploring three kernel types: linear, radial basis function (RBF), and polynomial. For the loss function they compare the conventional hinge loss with the Crammer‑Singer multi‑class formulation, which simultaneously optimizes margins for all labels and is well‑suited to multi‑label settings. Hyper‑parameter C is tuned via grid search on a log‑scale ranging from 10⁻³ to 10³; the optimal value is C = 10. All experiments are conducted using scikit‑learn’s LinearSVC and SVC implementations, with a one‑vs‑rest strategy for multi‑label prediction.
Evaluation metrics and results
Performance is measured with micro‑averaged and macro‑averaged precision, recall, and F1‑score, as well as overall accuracy. The linear kernel consistently outperforms the non‑linear kernels, which suffer from over‑fitting on the high‑dimensional sparse data. With the Crammer‑Singer loss, LinearSVC achieves a micro‑averaged F1 of 0.71 and a macro‑averaged F1 of 0.64, surpassing the hinge‑loss baseline by 4.2 % (micro) and 5.7 % (macro). The RBF and polynomial kernels attain micro‑F1 scores of 0.58 and 0.60 respectively, confirming that linear models are more appropriate for this problem domain.
Handling the long‑tail tag distribution
Because many tags appear only a few times, the authors introduce class‑weighting inversely proportional to tag frequency. This weighting improves recall for low‑frequency tags by an average of 12 % without degrading overall performance. Tag co‑occurrence analysis reveals strong clusters (e.g., Python‑data‑analysis, Java‑Spring), suggesting that modeling label dependencies could further boost results.
Limitations
The study deliberately excludes non‑textual metadata such as user reputation, posting time, and view counts, potentially missing useful signals. Moreover, the adopted one‑vs‑rest scheme treats each tag independently, ignoring inter‑label correlations that could be captured by structured prediction or graph‑based methods. The preprocessing pipeline also applies the same steps to both Korean and English content, which may not fully respect language‑specific nuances.
Future work
The authors propose several extensions: (1) integrating transformer‑based language models (e.g., BERT, multilingual BERT) to capture richer contextual information; (2) employing graph neural networks to learn tag‑tag relationships explicitly; (3) augmenting the feature set with metadata and user interaction signals; and (4) optimizing model size and inference latency for real‑time deployment.
Conclusion
The paper demonstrates that a relatively simple linear SVM equipped with the Crammer‑Singer multi‑class loss can achieve competitive performance on a massive, multi‑label tagging task while remaining computationally efficient. The results validate the viability of traditional kernel methods for large‑scale text classification and provide a solid baseline for more sophisticated deep‑learning or graph‑based approaches in future research.