Grid: A next generation data parallel C++ QCD library
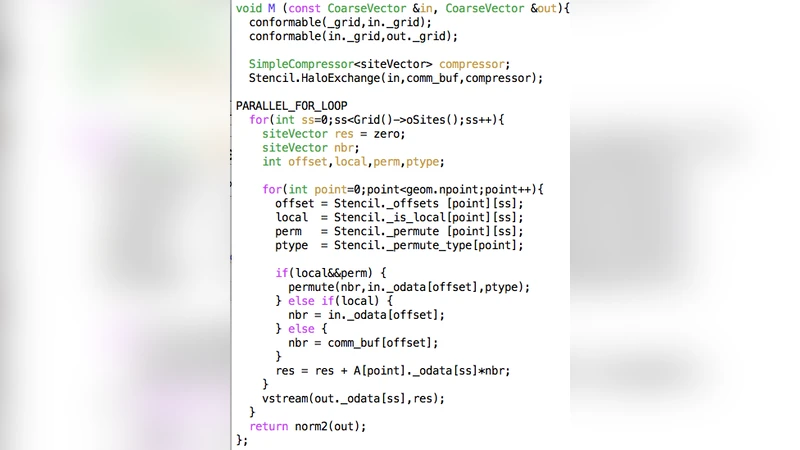
In this proceedings we discuss the motivation, implementation details, and performance of a new physics code base called Grid. It is intended to be more performant, more general, but similar in spirit to QDP++\cite{QDP}. Our approach is to engineer the basic type system to be consistently fast, rather than bolt on a few optimised routines, and we are attempt to write all our optimised routines directly in the Grid framework. It is hoped this will deliver best known practice performance across the next generation of supercomputers, which will provide programming challenges to traditional scalar codes. We illustrate the programming patterns used to implement our goals, and advances in productivity that have been enabled by using new features in C++11.
💡 Research Summary
The paper presents Grid, a next‑generation C++11 data‑parallel library designed to meet the challenges of modern supercomputers that combine deep multi‑core hierarchies, wide SIMD vector units, and distributed‑memory MPI communication. Grid’s philosophy differs from that of its predecessor QDP++ in that it seeks to make the type system itself inherently fast rather than bolting on a few hand‑tuned kernels. To achieve this, the authors introduce a set of SIMD‑aware vector classes (vRealF, vRealD, vComplexF, vComplexD, vInteger) that wrap architecture‑specific intrinsics behind overloaded operators. A static member function Nsimd() reports the vector width at compile time, allowing template instantiation to automatically generate code that is fully unrolled and inlined for the target width. Consequently, user code can be written with ordinary arithmetic expressions while the compiler emits optimal assembler sequences for SSE, AVX, AVX‑2, AVX‑512, IMCI, etc., with only a few hundred lines of architecture‑specific glue code.
A second, equally important innovation is the concept of over‑decomposition of the Cartesian lattice into “virtual nodes” that match the SIMD lane count. By interleaving data from multiple virtual sub‑domains into adjacent SIMD lanes, Grid can perform Nsimd() independent matrix‑vector products simultaneously. This eliminates the need for horizontal reductions that would otherwise dominate the latency of small‑matrix (3×3 colour) operations on wide vectors. The authors illustrate how a generic template‑based matmul routine, when instantiated with a SIMD vector type, automatically executes four, eight, or sixteen QCD matrix‑vector products in parallel without any extra code. The approach yields near‑100 % SIMD utilisation even for the notoriously unfavourable 3‑component colour space.
Grid also integrates MPI and OpenMP in a seamless fashion. A Grid object encapsulates the dimensionality of the problem, the MPI domain decomposition, the number of OpenMP threads per rank, and the SIMD lane count. Lattice containers hide the underlying layout, so high‑level expressions such as A = B * C or dC_dy = 0.5*(Cshift(C,1,+1)-Cshift(C,1,-1)) automatically trigger the appropriate halo exchanges, thread parallel loops, and vectorised kernels. The circular shift (cshift) operation is implemented with minimal permutation overhead because the virtual‑node layout ensures that neighbours of a given virtual node align with neighbours of other virtual nodes, keeping the surface‑to‑volume ratio low and the SIMD lanes coherent.
Performance measurements on recent Intel architectures (Skylake, Xeon Phi KNL) show that Grid attains 60‑65 % of the theoretical peak for cache‑resident data, corresponding to roughly a four‑fold speed‑up over traditional scalar implementations. The library’s design is deliberately portable: adding support for a new SIMD ISA typically requires only ~300 lines of code, and the authors anticipate straightforward extensions to ARM Neon or GPU vector units.
In summary, Grid delivers a high‑level, architecture‑agnostic programming model for Lattice QCD while embedding sophisticated low‑level optimisations—SIMD abstraction, virtual‑node over‑decomposition, template‑driven loop unrolling, and efficient stencil handling—directly into the library. This enables existing QCD codes to achieve state‑of‑the‑art performance on current and future exascale machines without extensive code rewrites, thereby addressing the growing programming burden imposed by ever‑wider parallelism.
Comments & Academic Discussion
Loading comments...
Leave a Comment