Get More With Less: Near Real-Time Image Clustering on Mobile Phones
Machine learning algorithms, in conjunction with user data, hold the promise of revolutionizing the way we interact with our phones, and indeed their widespread adoption in the design of apps bear testimony to this promise. However, currently, the computationally expensive segments of the learning pipeline, such as feature extraction and model training, are offloaded to the cloud, resulting in an over-reliance on the network and under-utilization of computing resources available on mobile platforms. In this paper, we show that by combining the computing power distributed over a number of phones, judicious optimization choices, and contextual information it is possible to execute the end-to-end pipeline entirely on the phones at the edge of the network, efficiently. We also show that by harnessing the power of this combination, it is possible to execute a computationally expensive pipeline at near real-time. To demonstrate our approach, we implement an end-to-end image-processing pipeline – that includes feature extraction, vocabulary learning, vectorization, and image clustering – on a set of mobile phones. Our results show a 75% improvement over the standard, full pipeline implementation running on the phones without modification – reducing the time to one minute under certain conditions. We believe that this result is a promising indication that fully distributed, infrastructure-less computing is possible on networks of mobile phones; enabling a new class of mobile applications that are less reliant on the cloud.
💡 Research Summary
The paper “Get More With Less: Near Real‑Time Image Clustering on Mobile Phones” investigates whether a full image‑clustering pipeline—feature extraction, vocabulary learning, vectorization, and final clustering—can be executed entirely on a set of smartphones without relying on cloud resources. The authors argue that modern phones possess enough compute power to handle traditionally heavyweight tasks, and that a cooperative, distributed approach can mitigate network latency, privacy concerns, and bandwidth constraints that plague cloud‑centric designs.
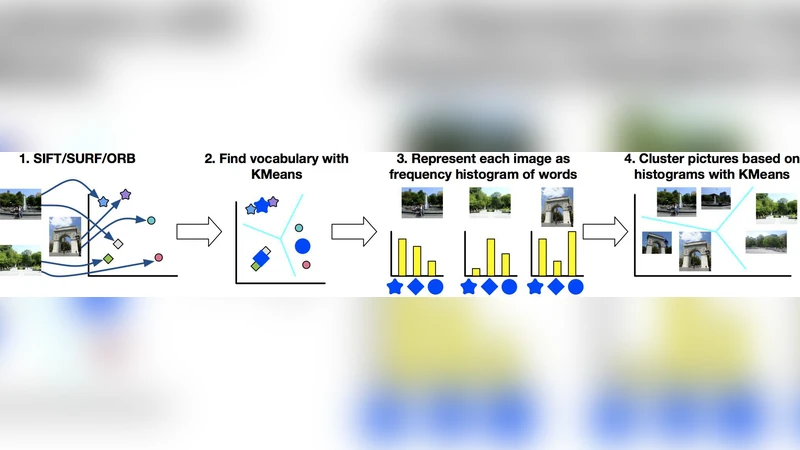
The pipeline consists of four stages. First, each image is processed with SIFT to extract local descriptors. Second, all descriptors from all phones are pooled and clustered with K‑Means to create a visual vocabulary (the “words”). Third, each image is represented as a Bag‑of‑Words (BoW) histogram over that vocabulary. Fourth, the BoW vectors themselves are clustered with a second K‑Means run, and the image closest to each final centroid is selected for upload. The authors implement this pipeline on three devices (Google Nexus 5, Nexus 6, Samsung Galaxy S4) and evaluate it with 37 images per phone (111 images total).
A naïve implementation using the Android SDK (Java) required over two hours to finish. By moving the computationally intensive parts to native C/C++ code via the Android NDK, the total runtime dropped to 679 seconds (≈11 minutes). Profiling revealed that the second stage—K‑Means for vocabulary construction—dominated the execution time. To accelerate this stage, the authors applied two complementary optimizations.
-
Approximate K‑Means: Inspired by prior work on “active points,” they identified points that change cluster assignment after the first iteration. In their dataset, about 70 % of points were active, and 90 % of those had a relative distance ratio (r) below 0.1, indicating they are near cluster boundaries. By discarding inactive points in subsequent iterations, the vocabulary K‑Means time fell by 41 %, reducing the overall pipeline to 395 seconds.
-
Context‑Based Seeding: They leveraged image metadata (GPS coordinates and EXIF orientation) to generate better initial centroids. Experiments showed that using both GPS and EXIF together reduced the number of reassignment steps needed for convergence, yielding an additional ≈10 % speed‑up.
Combining NDK acceleration, approximate K‑Means, and context‑based seeding resulted in a 75 % reduction in total execution time compared with the unmodified pipeline, bringing the processing time down to roughly one minute under favorable conditions. Cluster quality, measured by visual similarity to the baseline, remained above 75 % of the original, indicating that the speed gains did not come at a prohibitive loss of accuracy.
The authors also present a simple analytical model that predicts when to switch between a “compute‑bound” regime (favoring local processing) and a “network‑bound” regime (favoring data upload) based on measured bandwidth and CPU load. This model suggests that dynamic pipeline shifting can further improve performance as network conditions fluctuate.
Limitations discussed include the heavy computational cost of SIFT (even with NDK optimization), the focus on high‑end phones (leaving low‑end devices untested), and the reliance on subjective visual assessment for clustering quality rather than standard quantitative metrics such as NMI or ARI. Future work is suggested to explore lighter feature extractors (e.g., ORB, deep‑learning embeddings), scale the system to larger, heterogeneous phone clusters, and incorporate rigorous quality metrics.
In summary, the paper demonstrates that a fully distributed, infrastructure‑less image‑clustering workflow is feasible on contemporary mobile hardware. By carefully selecting algorithms, exploiting native code, and using contextual cues, the authors achieve near‑real‑time performance while dramatically reducing dependence on cloud services. This work opens the door to privacy‑preserving, bandwidth‑efficient mobile AI applications and suggests a new design paradigm for edge‑centric machine‑learning pipelines.
Comments & Academic Discussion
Loading comments...
Leave a Comment