Bigger Buffer k-d Trees on Multi-Many-Core Systems
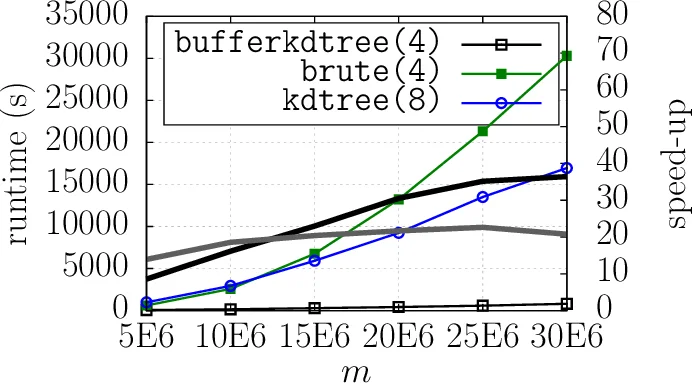
A buffer k-d tree is a k-d tree variant for massively-parallel nearest neighbor search. While providing valuable speed-ups on modern many-core devices in case both a large number of reference and query points are given, buffer k-d trees are limited by the amount of points that can fit on a single device. In this work, we show how to modify the original data structure and the associated workflow to make the overall approach capable of dealing with massive data sets. We further provide a simple yet efficient way of using multiple devices given in a single workstation. The applicability of the modified framework is demonstrated in the context of astronomy, a field that is faced with huge amounts of data.
💡 Research Summary
The paper addresses a critical scalability limitation of the previously introduced buffer k‑d tree, a data structure designed to accelerate nearest‑neighbor (NN) search on massively parallel many‑core devices such as GPUs. The original buffer k‑d tree attaches a fixed‑size buffer to each leaf of a conventional k‑d tree and postpones query processing until enough queries have accumulated in a leaf. At that point all queries stored in the leaf buffers are processed together in a brute‑force fashion on the GPU, which yields highly regular memory access patterns and avoids the severe branch divergence that would occur if each query traversed the tree independently. While this approach delivers impressive speed‑ups for moderate‑size data sets, it requires that both the top part of the tree (splitting values) and the entire leaf structure containing the reference points reside in GPU memory. Modern GPUs, however, provide only a few gigabytes of fast memory, far less than the tens or hundreds of gigabytes needed for modern scientific data sets (e.g., astronomical catalogs with billions of high‑dimensional points).
The authors propose two complementary modifications that remove this memory bottleneck and enable the use of multiple GPUs within a single workstation.
-
Separation of Top Tree and Leaf Structure
The top tree, which stores only the median split values, is tiny (a few megabytes even for trees deep enough to handle billions of points). Consequently it can be built on the host and copied in full to each GPU without any significant memory impact. The leaf structure, which holds the reordered reference points, is kept entirely in host RAM. This eliminates the need to duplicate the massive point array on the GPU. -
Chunk‑Based Overlap of Data Transfer and Computation
Two fixed‑size “chunk buffers” are allocated on each GPU (e.g., 128 KB each) together with two pinned‑memory buffers on the host. During the query phase, the leaf structure is logically divided into N chunks. In each iteration of the algorithm, theProcessAllBuffersroutine fetches the indices of queries whose leaf ranges intersect the current chunk, copies that chunk from host to one of the GPU buffers, and launches a kernel that computes distances between those queries and all points in the chunk. While the kernel runs on chunk j, the next chunk j + 1 is transferred asynchronously into the second buffer. This double‑buffering scheme hides PCI‑e transfer latency and ensures that the GPU is never idle.
The overall workflow remains identical to the original LazySearch algorithm: queries are streamed into leaf buffers, buffers are emptied when half full, and the re‑insert queue feeds queries that still need further processing after a chunk has been examined. The only change is that the leaf data are no longer resident on the device; they are streamed chunk‑by‑chunk.
Multi‑GPU Extension
Each GPU receives a copy of the top tree and its own pair of chunk buffers. The host distributes chunks to GPUs in a round‑robin fashion, effectively load‑balancing the work. Because the top tree is small, replicating it incurs negligible overhead. The double‑buffering mechanism works independently on each device, so the pipeline scales almost linearly with the number of GPUs, limited only by the aggregate PCI‑e bandwidth.
Experimental Validation
The authors evaluate the approach on a realistic astronomy use case: a catalog of billions of 15‑dimensional points. Compared with the original single‑GPU buffer k‑d tree, the new system achieves up to a 3× speed‑up while keeping GPU memory usage under a few gigabytes. Adding a second GPU yields near‑linear scaling, confirming that the design successfully overlaps communication and computation.
Implications and Future Directions
By moving the bulky leaf structure to host memory and streaming it in manageable chunks, the buffer k‑d tree becomes applicable to any dataset that fits in main memory, regardless of GPU capacity. The same principle can be extended to distributed environments where each node hosts a GPU and the leaf chunks are transferred over a network, opening the door to truly petabyte‑scale NN search. Moreover, the technique is agnostic to the distance metric and can be combined with approximate NN schemes, further broadening its applicability to machine‑learning pipelines, high‑energy physics, genomics, and other data‑intensive fields.
In summary, this work removes the principal memory limitation of buffer k‑d trees, introduces an efficient host‑GPU chunking pipeline, and demonstrates practical multi‑GPU scalability, thereby delivering a robust solution for massive nearest‑neighbor queries on modern many‑core hardware.
Comments & Academic Discussion
Loading comments...
Leave a Comment