Distributed Balanced Partitioning via Linear Embedding
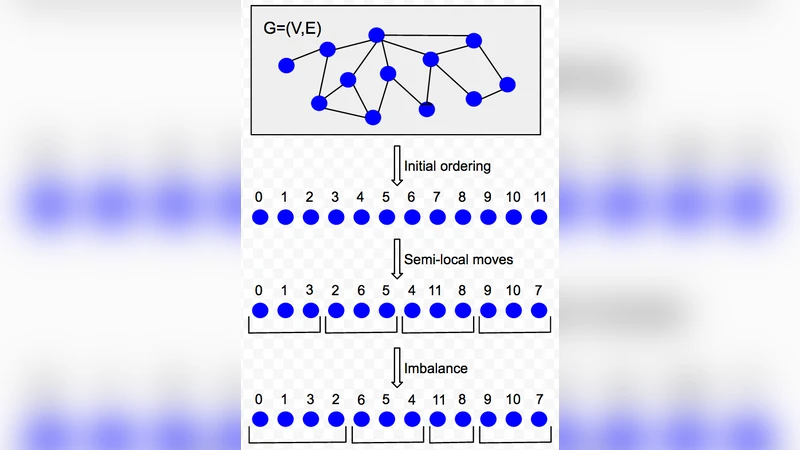
Balanced partitioning is often a crucial first step in solving large-scale graph optimization problems, e.g., in some cases, a big graph can be chopped into pieces that fit on one machine to be processed independently before stitching the results together. In other cases, links between different parts may show up in the running time and/or network communications cost. We study a distributed balanced partitioning problem where the goal is to partition the vertices of a given graph into k pieces so as to minimize the total cut size. Our algorithm is composed of a few steps that are easily implementable in distributed computation frameworks. The algorithm first embeds nodes of the graph onto a line, and then processes nodes in a distributed manner guided by the linear embedding order. We examine various ways to find the first embedding, e.g., via a hierarchical clustering or Hilbert curves. Then we apply four different techniques including local swaps, minimum cuts on the boundaries of partitions, as well as contraction and dynamic programming. As our empirical study, we compare the above techniques with each other, and also to previous work in distributed graph algorithms, e.g., a label propagation method, FENNEL and Spinner. We report our results both on a private map graph and several public social networks, and show that our results beat previous distributed algorithms: e.g., compared to the label propagation algorithm, we report an improvement of 15-25% in the cut value. We also observe that our algorithms allow for scalable distributed implementation for any number of partitions. Finally, we apply our techniques for the Google Maps Driving Directions to minimize the number of multi-shard queries with the goal of saving in CPU usage. During live experiments, we observe an ~40% drop in the number of multi-shard queries when comparing our method with a standard geography-based method.
💡 Research Summary
The paper tackles the classic problem of balanced graph partitioning in a distributed setting: given a large graph G = (V,E) and a target number k of parts, produce an α‑balanced partition that minimizes the total cut size. Because the problem is NP‑hard even for k = 2, the authors design a heuristic framework that can be implemented on standard distributed data‑processing platforms such as MapReduce, Pregel, or Giraph.
The framework consists of two logical stages. In the first stage each vertex is embedded onto a one‑dimensional line. Four embedding strategies are explored: (i) a naïve random permutation, (ii) a Hilbert‑curve ordering that respects geographic coordinates (useful for map graphs), (iii) a hierarchical clustering based on the number of common neighbours (applicable to any graph), and (iv) a hierarchical clustering based on the inverse of geographic distance (also for map graphs). Empirically, the common‑neighbour clustering consistently yields the lowest initial cut, even outperforming the geographic Hilbert ordering on map data.
Once an ordering is obtained, the second stage refines the partition by processing vertices in the order induced by the line. Four post‑processing techniques are proposed:
- Local Swaps – Randomly exchange adjacent vertices in the ordering if the swap reduces the cut. This simple operation is highly effective on dense social‑network graphs such as Twitter.
- Boundary Min‑Cut – For each current partition boundary, compute a minimum cut that separates the two sides and reassign boundary vertices accordingly. This technique shines on geographic graphs where natural borders exist.
- Contraction + Dynamic Programming – Collapse the clusters obtained from the boundary min‑cut into super‑nodes, then use dynamic programming to find optimal cut positions along the line. This yields near‑optimal boundaries for large k and scales well.
- Metric Ordering Optimization – Reorder the line to better respect a distance metric derived from edge weights, further reducing cross‑partition edges.
The authors combine these methods into a single iterative algorithm called Combination. Starting from the best embedding (usually the common‑neighbour hierarchical clustering), the algorithm repeatedly applies the four refinements until the cut no longer improves. In practice, convergence is reached after only a few passes, even on graphs with hundreds of millions of vertices and billions of edges. Memory usage remains linear in the size of the graph, and the runtime grows roughly linearly with the number of edges; the number of partitions k has only a modest impact on performance.
The experimental evaluation compares the proposed approach against several state‑of‑the‑art distributed partitioners: the label‑propagation method of Ugander & Backstrom (UB13), FENNEL, Spinner, and the classic METIS. Experiments are conducted on a private map graph (Google Maps road network) and on public social‑network datasets (LiveJournal, Twitter). Key findings include:
- On LiveJournal, for k = 20 the cut is reduced from 37 % of total edge weight (label‑propagation) to 27.5 % – a 25 % improvement. For k = 100 the reduction is 15 % (49 % → 41.5 %).
- On Twitter, for k > 2 the Combination algorithm outperforms both METIS and FENNEL; for k = 2 it beats METIS but is slightly worse than FENNEL.
- Spinner is consistently outperformed by a wide margin across all datasets.
- The algorithm scales gracefully: increasing k from 2 to tens of thousands does not significantly affect runtime.
- Among initialization strategies, the common‑neighbour hierarchical clustering dominates, even on geographic graphs where Hilbert‑curve ordering was expected to be superior.
- The four refinement techniques complement each other: random swaps excel on social graphs, while boundary min‑cut and contraction + DP are most effective on map graphs. Their combination yields the best overall results.
A practical deployment is demonstrated in Google Maps Driving Directions. The road network is first partitioned using a Hilbert‑curve baseline, then refined with the proposed cut‑optimization pipeline. Live traffic experiments show a 40 % reduction in multi‑shard queries compared with the baseline, translating into noticeable CPU savings. Allowing a modest imbalance (α = 0.1) further reduces cross‑shard traffic by 21 %.
The paper’s contributions are threefold: (1) a clear, modular distributed framework that separates embedding from order‑guided refinement, (2) a suite of scalable post‑processing techniques that together achieve state‑of‑the‑art cut quality, and (3) a real‑world validation showing tangible system‑level benefits. Limitations include the focus on cut size alone (ignoring intra‑partition cohesion), lack of publicly disclosed absolute runtimes due to corporate policy, and the relatively high cost of computing the similarity matrix for hierarchical clustering on extremely large graphs.
Future work suggested by the authors includes exploring spectral or graph‑neural‑network embeddings that can be computed in a distributed fashion, extending the objective to multi‑criteria (e.g., latency, modularity), and adapting the framework to streaming or online graph settings.
In summary, the paper presents a practical, distributed solution for balanced graph partitioning that leverages a simple linear embedding followed by sophisticated, order‑driven refinements. It achieves substantial improvements over existing distributed heuristics, scales to massive real‑world graphs, and demonstrates concrete operational gains in a production service.
Comments & Academic Discussion
Loading comments...
Leave a Comment