Hybrid Approach for Inductive Semi Supervised Learning using Label Propagation and Support Vector Machine
Semi supervised learning methods have gained importance in today’s world because of large expenses and time involved in labeling the unlabeled data by human experts. The proposed hybrid approach uses SVM and Label Propagation to label the unlabeled data. In the process, at each step SVM is trained to minimize the error and thus improve the prediction quality. Experiments are conducted by using SVM and logistic regression(Logreg). Results prove that SVM performs tremendously better than Logreg. The approach is tested using 12 datasets of different sizes ranging from the order of 1000s to the order of 10000s. Results show that the proposed approach outperforms Label Propagation by a large margin with F-measure of almost twice on average. The parallel version of the proposed approach is also designed and implemented, the analysis shows that the training time decreases significantly when parallel version is used.
💡 Research Summary
The paper proposes a novel inductive semi‑supervised learning framework that combines Label Propagation (LP) with Support Vector Machines (SVM). The method works iteratively: first, LP is applied to the whole training set (both labeled and unlabeled) to compute a class‑probability matrix for every unlabeled instance. Next, an SVM is trained only on the currently labeled data. For each unlabeled instance, the class predicted by the SVM is compared with the LP probability; if the LP probability for that class exceeds a predefined threshold and the two predictions agree, the instance is assigned that label and moved into the labeled pool. The process repeats until no new instances are labeled or all data become labeled. This “agreement‑based labeling” strategy is the core novelty, as it filters out low‑confidence LP assignments and prevents SVM from being polluted by noisy pseudo‑labels.
Two implementations are described: a serial version and a parallel version. In the parallel version, LP and SVM training are launched as separate processes, and the unlabeled set is partitioned among multiple worker tasks that simultaneously check the agreement condition. This parallelization yields substantial reductions in wall‑clock training time for larger datasets without sacrificing accuracy.
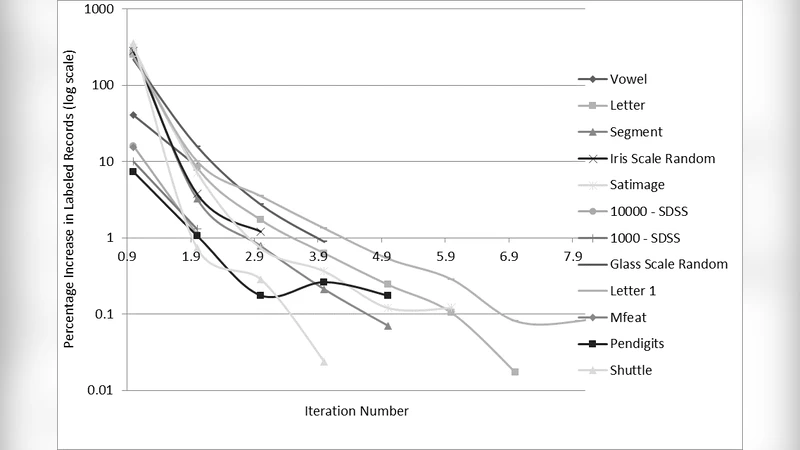
The authors evaluate the approach on twelve publicly available datasets ranging from a few hundred to over twelve thousand instances (e.g., Vowel, Letter, Segment, Iris, Satimage, SDSS‑1000/10000, Glass, Mfeat, Pendigits, Shuttle). Experiments compare four configurations: (1) the proposed hybrid method versus pure LP (Zhu et al., 2003), (2) hybrid versus a fully supervised SVM trained only on the original labeled subset, (3) hybrid with SVM versus hybrid with Logistic Regression (LogReg), and (4) serial versus parallel implementations. The initial labeled proportion is varied between 0 % and 20 % and LP probability thresholds between 0.5 and 0.9.
Key findings include:
- The hybrid method consistently outperforms pure LP, achieving average F‑measure improvements of roughly a factor of two across all datasets. Even with only 5 % of the data initially labeled, F‑measures remain in the 0.67–0.90 range.
- When the hybrid framework uses SVM as the classifier, it yields higher F‑measure and lower training time than when Logistic Regression is used, confirming the suitability of margin‑based classifiers in this setting.
- The percentage of newly labeled instances drops sharply after the first few iterations, indicating that the agreement condition quickly isolates the most reliable pseudo‑labels. Consequently, the final labeled set typically comprises only 20–30 % of the total data, yet performance remains high.
- Parallel execution reduces training time by 30–50 % for datasets with ≥10 k instances, while the final F‑measure remains unchanged, demonstrating good scalability.
- Sensitivity analysis shows that varying the LP probability threshold has minimal impact on the final F‑measure because the SVM filter dominates the labeling decision.
Complexity analysis notes that both LP and SVM have theoretical time complexity O(dim · N³), which explains the observed polynomial increase in training time with dataset size. The parallel design mitigates this cost by overlapping LP and SVM computation and distributing the agreement checks.
The paper also discusses limitations: constructing the full similarity graph for LP can be memory‑intensive on very large datasets; the threshold parameter is set empirically and could benefit from automated tuning; the one‑vs‑one multi‑class SVM scheme scales poorly with many classes; and the current LP implementation is a basic version, leaving room for more sophisticated graph‑based propagation techniques.
In conclusion, the authors present a practical and effective hybrid semi‑supervised learning algorithm that leverages the complementary strengths of graph‑based label diffusion and margin‑based classification. The experimental results across diverse benchmark datasets validate the approach’s superior accuracy over pure LP and its efficiency gains through parallelization, making it a promising candidate for real‑world applications where labeled data are scarce but abundant unlabeled data are available.
Comments & Academic Discussion
Loading comments...
Leave a Comment