Predicting the top and bottom ranks of billboard songs using Machine Learning
The music industry is a $130 billion industry. Predicting whether a song catches the pulse of the audience impacts the industry. In this paper we analyze language inside the lyrics of the songs using several computational linguistic algorithms and predict whether a song would make to the top or bottom of the billboard rankings based on the language features. We trained and tested an SVM classifier with a radial kernel function on the linguistic features. Results indicate that we can classify whether a song belongs to top and bottom of the billboard charts with a precision of 0.76.
💡 Research Summary
**
The paper investigates whether the textual content of song lyrics alone can be used to predict a song’s commercial success on the Billboard charts. Using weekly Billboard “Hot‑100” data from 2001 to 2010, the authors first collapse multiple weekly appearances of the same track into a single record and assign each song its peak chart position. They then define a binary classification problem: songs whose best rank falls within the top 30 versus those whose best rank falls within the bottom 30 of the chart. After filtering, 1,622 songs remain (991 in the top‑30 class and 631 in the bottom‑30 class).
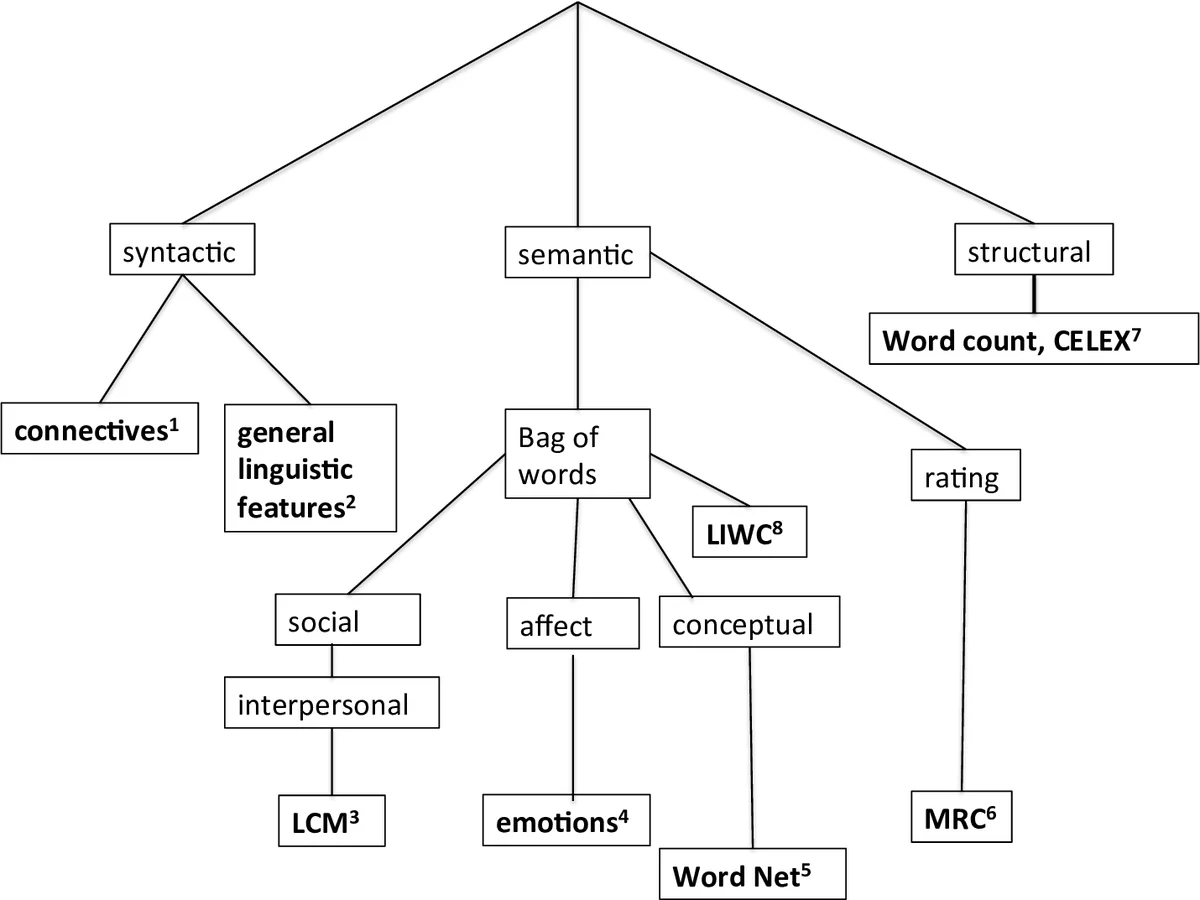
To capture linguistic information, the study extracts 261 features from each lyric using eight computational‑linguistic tools. These include Biber’s 67 syntactic‑grammatical markers, WordNet semantic categories (44 high‑level classes), Google 1‑gram frequency bins, the Linguistic Category Model (LCM) for interpersonal verbs and adjectives, emotion‑word counts based on the LIWC/Tausczik‑Pennebaker lexicon (basic and complex emotions), connective‑type counts (positive/negative additive, temporal, causal), CELEX word‑frequency statistics, and MRC psycholinguistic ratings (familiarity, concreteness, meaningfulness). The feature set therefore spans structural, syntactic, semantic, affective, and discourse dimensions of the lyrics.
Because the number of features far exceeds the number of observations, the authors apply Principal Component Analysis (PCA) and retain components that together explain 60 % of the variance, reducing the dimensionality from 261 to 39. While PCA mitigates noise and multicollinearity, it also obscures the interpretability of individual linguistic cues.
The dataset is imbalanced (approximately 1.5 : 1 in favor of the top‑30 class). To address this, Synthetic Minority Over‑sampling Technique (SMOTE) is employed to generate synthetic examples of the minority (bottom‑30) class. Classification is performed with Support Vector Machines (SVM) using three kernel functions: radial basis function (RBF), polynomial, and linear. A 10‑fold cross‑validation scheme evaluates performance. The RBF kernel achieves the highest scores: precision = 0.76, recall = 0.76, and Cohen’s κ = 0.51, indicating moderate agreement beyond chance. Alternative classifiers (Naïve Bayes, standard Bayes, decision trees) are reported to perform substantially worse.
The authors discuss their findings in the context of prior work that has linked lyrical language to emotion detection and genre classification. They argue that, even without audio features, linguistic cues provide a statistically significant signal for distinguishing chart‑topping hits from low‑performing songs. They acknowledge several limitations: (1) exclusion of melodic, rhythmic, and production elements that are known to influence popularity; (2) reliance on a single market (U.S. Billboard) and a decade‑long historical window, which may embed cultural and temporal biases; (3) loss of feature interpretability after PCA, preventing clear identification of which linguistic patterns drive the predictions; and (4) modest κ value, suggesting room for improvement before deployment in industry settings.
Future work is outlined to address these gaps: integrating audio descriptors for a multimodal model, employing time‑aware validation to capture evolving musical trends, applying feature‑selection methods that retain semantic meaning (e.g., LASSO, SHAP), testing on external datasets (other countries, newer years), and linking predictions to concrete business metrics such as sales, streaming counts, or licensing revenue.
In summary, the study demonstrates that a machine‑learning pipeline based solely on lyric‑derived linguistic features can achieve a respectable 0.76 precision in separating top‑30 from bottom‑30 Billboard songs. While the approach is not yet sufficient for high‑stakes commercial decision‑making, it establishes a proof‑of‑concept that textual analysis can contribute valuable insight to music‑industry forecasting, especially when combined with richer multimodal data in future research.
Comments & Academic Discussion
Loading comments...
Leave a Comment