The Human Kernel
Bayesian nonparametric models, such as Gaussian processes, provide a compelling framework for automatic statistical modelling: these models have a high degree of flexibility, and automatically calibrated complexity. However, automating human expertis…
Authors: Andrew Gordon Wilson, Christoph Dann, Christopher G. Lucas
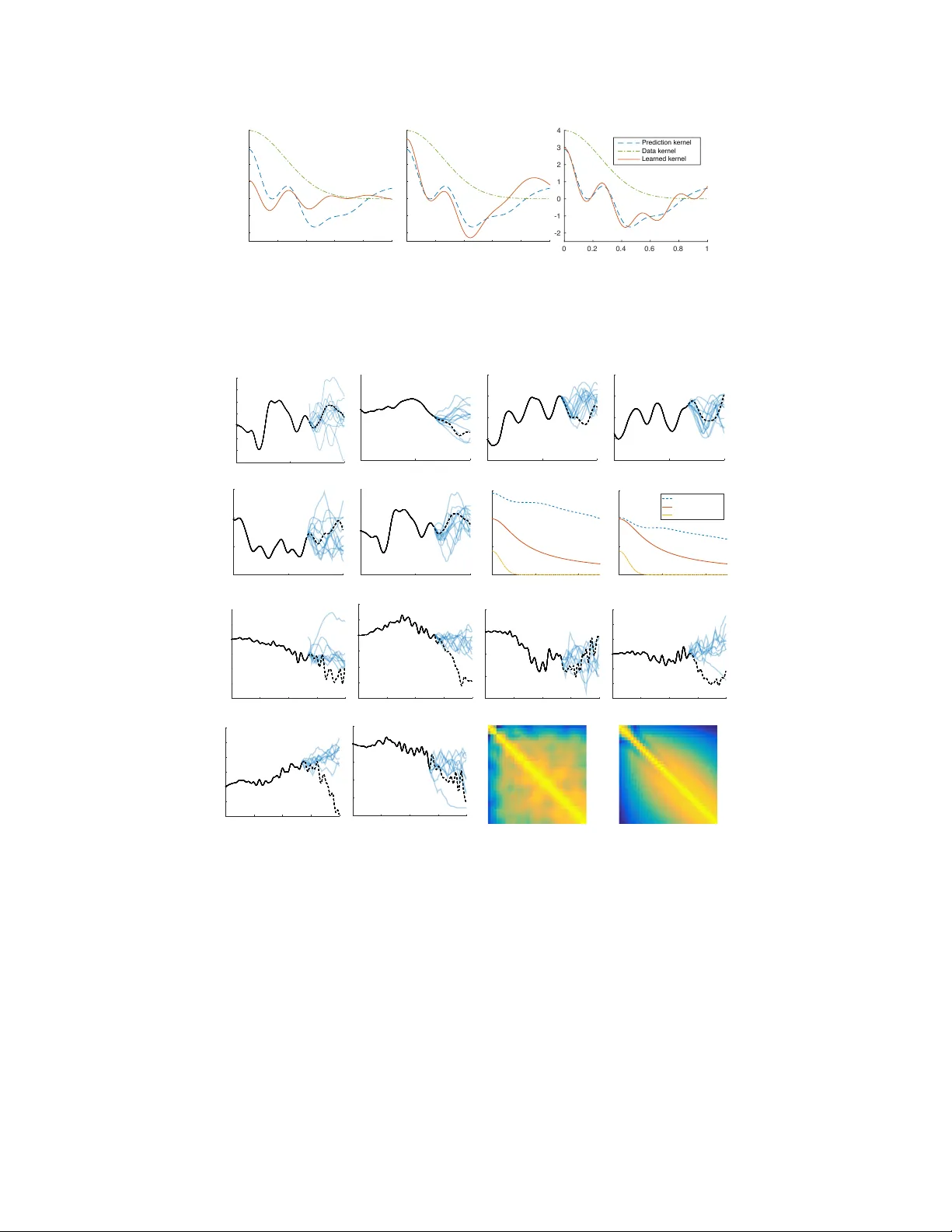
The Human K er nel Andrew Gordon Wilson CMU Christoph Dann CMU Christopher G. Lucas Univ ersity of Edinbur gh Eric P . Xing CMU Abstract Bayesian nonparametric models, such as Gaussian processes, provide a com- pelling framew ork for automatic statistical modelling: these models hav e a high degree of flexibility , and automatically calibrated complexity . Howe ver , automat- ing human expertise remains elusi ve; for example, Gaussian processes with stan- dard k ernels struggle on function e xtrapolation problems that are tri vial for human learners. In this paper , we create function extrapolation problems and acquire hu- man responses, and then design a kernel learning framew ork to re verse engineer the inducti ve biases of human learners across a set of behavioral e xperiments. W e use the learned k ernels t o g ain psychological insights and to extrapolate in human- like w ays that go be yond traditional stationary and polynomial kernels. Finally , we in vestigate Occam’ s razor in human and Gaussian process based function learning. 1 Introduction T ruly intelligent systems can learn and make decisions without human interv ention. Therefore it is not surprising that early machine learning efforts, such as the perceptron, ha ve been neurally inspired [ 1 ]. In recent years, probabilistic modelling has become a cornerstone of machine learning approaches [ 2 , 3 , 4 ], with applications in neural processing [ 5 , 6 , 3 , 7 ] and human learning [ 8 , 9 ]. From a probabilistic perspective, the ability for a model to automatically discover patterns and per- form e xtrapolation is determined by its support (which solutions are a priori possible), and inducti ve biases (which solutions are a priori likely). Ideally , we want a model to be able to represent many possible solutions to a giv en problem, with inductive biases which can extract intricate structure from limited data. For example, if we are performing character recognition, we would want our sup- port to contain a large collection of potential characters, accounting e ven for rare writing styles, and our inductiv e biases to reasonably reflect the probability of encountering each character [ 10 , 11 ]. The support and inducti ve biases of a wide range of probabilistic models, and thus the ability for these models to learn and generalise, is implicitly controlled by a covariance kernel , which deter - mines the similarities between pairs of datapoints. F or example, Bayesian basis function regression (including, e.g., all polynomial models), splines, and infinite neural networks, can all e xactly be rep- resented as a Gaussian process with a particular kernel function [ 12 , 11 , 10 ]. Moreov er , the Fisher kernel provides a mechanism to reformulate probabilistic generati ve models as kernel methods [ 13 ]. In this paper, we wish to rev erse engineer human-like support and inductiv e biases for function learning, using a Gaussian process based kernel learning formalism. In particular: • W e create new human function learning datasets, including nov el function extrapolation problems and multiple-choice questions that e xplore human intuitions about simplicity and explanatory po wer . T o participate in these experiments, and vie w demonstrations, see http://functionlearning.com/ • W e develop a statistical framework for kernel learning from the predictions of a model, conditioned on the (training) information that model is given. The ability to sample multiple sets of posterior predictions from a model, at any input locations of our choice, giv en any dataset of our choice, pro vides unprecedented statistical strength for k ernel learning. By 1 contrast, standard kernel learning in v olves fitting a kernel to a fixed dataset that can only be viewed as a single realisation from a stochastic process. Our frame work lev erages spectral mixtur e kernels [ 14 ] and non-parametric estimates. • W e exploit this frame work to directly learn k ernels from human responses, which contrasts with all prior work on human function learning, where one compares a fixed model to human responses. Moreov er, we consider indi vidual rather than av eraged human extrapo- lations. • W e interpret the learned kernels to gain scientific insights into human inductive biases, including the ability to adapt to new information for function learning. W e also use the learned “human kernels” to inspire new types of covariance functions which can enable extrapolation on problems which are dif ficult for con ventional Gaussian process models. • W e study Occam’ s razor in human function learning, and compare to Gaussian process marginal lik elihood based model selection, which we sho w is biased to wards under-fitting. • W e provide an expressi ve quantitati ve means to compare existing machine learning algo- rithms with human learning, and a mechanism to directly infer human prior representations. Our work is intended as a preliminary step towards building probabilistic kernel machines that en- capsulate human-like support and inductiv e biases. Since state of the art machine learning methods perform conspicuously poorly on a number of extrapolation problems which would be easy for humans [ 10 ], such ef forts ha ve the potential to help automate machine learning and impro ve perfor - mance on a wide range of tasks – including settings which are difficult for humans to process (e.g., big data and high dimensional problems). Finally , the presented framew ork can be considered in a more general context, where one wishes to efficiently rev erse engineer interpretable properties of any model (e.g., a deep neural network) from its predictions. W e further describe related work in section 2 . In section 3 we introduce a framew ork for learning kernels from human responses, and employ this framework in section 4 . In the supplement, we provide background on Gaussian processes [ 12 ], which we recommend as a re view . 2 Related W ork Historically , efforts to understand human function learning hav e focused on rule-based relationships (e.g., polynomial or power-la w functions) [ 15 , 16 ], or interpolation based on similarity learning [ 17 , 18 ]. Grif fiths et al. [ 19 ] were the first to note that a Gaussian process framework can be used to unify these two perspectiv es. They introduced a GP model with a mixture of RBF and polynomial kernels to reflect the human ability to learn arbitrary smooth functions while still identifying sim- ple parametric functions. They applied this model to a standard set of ev aluation tasks, comparing predictions on simple functions to averaged human judgments, and interpolation performance to hu- man error rates. Lucas et al. [ 20 ] extended this model to accommodate a wider range of phenomena, using an infinite mixture of Gaussian process experts [ 21 ], and Lucas et al. [ 22 ] used this model to shed new light on human predictions gi ven sparse data. Our work complements these pioneering Gaussian process models and prior work on human func- tion learning, but has many features that distinguish it from previous contributions: (1) rather than iterativ ely building models and comparing them to human predictions, based on fix ed assumptions about the regularities humans can recognize, we are directly learning the properties of the human model through advanced kernel learning techniques; (2) essentially all models of function learn- ing, including past GP models, are e valuated on a veraged human responses, setting aside indi vidual differences and erasing critical statistical structure in the data 1 . By contrast, our approach uses indi- vidual responses; (3) many recent model ev aluations rely on relativ ely small and heterogeneous sets of experimental data. The ev aluation corpora using recent re vie ws [ 23 , 19 ] are limited to a small set of parametric forms, i.e., polynomial, power-la w , logistic, logarithmic, exponential, and sinu- soidal, and the more detailed analyses tend to in volve only linear, quadratic, and logistic functions. Other projects hav e collected richer and more detailed data sets [ 24 , 25 ], but we are only aware of 1 For example, av eraging prior dra ws from a Gaussian process would remove the structure necessary for kernel learning, lea ving us simply with an approximation of the prior mean function. 2 coarse-grained, qualitative analyses using these data. Moreover , experiments that depart from sim- ple parametric functions tend to use very noisy data. Thus it is unsurprising that participants tend to rev ert to the prior mode that arises in almost all function learning experiments: linear functions, especially with slope-1 and intercept-0 [ 24 , 25 ] (but see [ 26 ]). In a departure from prior work, we create original function learning problems with no simple parametric description and no noise – where it is obvious that human learners cannot resort to simple rules – and acquire the human data ourselves. W e hope these novel datasets will inspire more detailed findings on function learning; (4) we learn kernels from human responses, which (i) provide insights into the biases that driv e human function learning and the human ability to progressively adapt to ne w information, and (ii) enable human-like extrapolations on problems that are difficult for con v entional Gaussian process models; and (5) we inv estigate Occam’ s razor in human function learning and nonparametric model selection. 3 The Human K ernel The rule-based and associative theories for human function learning can be unified as part of a Gaus- sian process framework. Indeed, Gaussian processes contain a large array of probabilistic models, and have the non-parametric flexibility to produce infinitely man y consistent (zero training error) fits to any dataset. Moreov er , the support and inductive biases of a Gaussian process are encaspulated by a covariance kernel. Our goal is to learn Gaussian process cov ariance kernels from predictions made by humans on function learning experiments, to gain a better understanding of human learning, and to inspire ne w machine learning models, with improved extrapolation performance, and minimal human intervention. 3.1 Problem Setup A (human) learner is giv en access to data y at training inputs X , and makes predictions y ∗ at testing inputs X ∗ . W e assume the predictions y ∗ are samples from the learner’ s posterior distribution ov er possible functions, following results sho wing that human inferences and judgments resemble posterior samples across a wide range of perceptual and decision-making tasks [ 27 , 28 , 29 ]. W e assume we can obtain multiple draws of y ∗ for a giv en X and y . 3.2 Ker nel Learning In standard Gaussian process applications, one has access to a single realisation of data y , and performs kernel learning by optimizing the marginal likelihood of the data with respect to co variance function hyperparameters θ , as described in the supplementary material. Howe ver , with only a single realisation of data we are highly constrained in our ability to learn an expressi ve kernel function – requiring us to make strong assumptions, such as RBF covariances, to extract any useful information from the data. One can see this by simulating N datapoints from a GP with a known kernel, and then visualising the empirical estimate y y > of the known cov ariance matrix K . The empirical estimate, in most cases, will look nothing like K . Ho wev er , perhaps surprisingly , if we ha ve even a small number of multiple draws from a GP , we can recover a wide array of co variance matrices K using the empirical estimator Y Y > / M − ¯ y ¯ y > , where Y is an N × M data matrix, for M draws, and ¯ y is a vector of empirical means. The typical goal in choosing (learning) a kernel is to minimize some loss function ev aluated on training data, ultimately to minimize generalisation error . But here we want to reverse engineer the (prediction) kernel of a (human) model, based on both training data and predictions of that model giv en that training data. If we have a single sample extrapolation, y ∗ , at test inputs X ∗ , based on training points y , and Gaussian noise, the probability p ( y ∗ | y , k θ ) is giv en by the posterior predictive distribution of a Gaussian process, with f ∗ ≡ y ∗ . One can use this probability as a utility function for kernel learning, much lik e the mar ginal likelihood. See the supplementary material for details of these distributions. Our problem setup affords unprecedented opportunities for flexible kernel learning. If we have multiple sample extrapolations from a giv en set of training data, y (1) ∗ , y (2) ∗ , . . . , y ( W ) ∗ , then the pre- dictiv e conditional marginal likelihood becomes Q W j =1 p ( y ( j ) ∗ | y , k θ ) . One could apply this new 3 objectiv e, for instance, if we were to vie w different human extrapolations as multiple dra ws from a common generati ve model. Clearly this assumption is not entirely correct, since different people will have different biases, but it naturally suits our purposes: we are not as interested in the differ - ences between people as their shar ed inductive biases, and assuming multiple draws from a common generativ e model provides extraordinary statistical strength for learning these shared biases. Ulti- mately , we will consider modelling the human responses both separately and collectively , studying the differences and similarities between the responses. One option for learning a pr ediction kernel is to specify a flexible parametric form for k and then learn θ by optimizing our chosen objectiv e functions. For this approach, we choose the recent spec- tral mixture kernels of W ilson and Adams [ 14 ], which can model a wide range of stationary covari- ances, and are intended to help automate kernel selection. Howe ver , we note that our objective func- tion can readily be applied to other parametric forms. W e also consider empirical non-parametric kernel estimation, since non-parametric kernel estimators can ha ve the flexibility to con ver ge to any positiv e definite kernel, and thus become appealing when we ha ve the signal strength provided by multiple draws from a stochastic process. 4 Human Experiments W e wish to disco ver kernels that capture human inductiv e biases for learning functions and e xtrap- olating from complex or ambiguous training data. W e start by testing the consistency of our kernel learning procedure in section 4.1 . In section 4.2 , we study progressi ve function learning. Indeed, humans participants will have a dif ferent representation (e.g., learned kernel) for different observed data, and examining ho w these representations progressi vely adapt with ne w information can shed light on our prior biases. In section 4.3 , we learn human kernels to extrapolate on tasks which are difficult for Gaussian processes with standard kernels. In section 4.4 , we study model selection in human function learning. All human participants were recruited using Amazon’ s mechanical turk and saw experimental materials that are described in the supplement, with demonstrations provided at http://functionlearning.com/ . When we are considering stationary ground truth k er- nels, we use a spectral mixture for kernel learning; otherwise, we use a non-parametric empirical estimate. 4.1 Reconstructing Ground T ruth Ker nels W e use simulations with a known ground truth to test the consistency of our kernel learning proce- dure, and the effects of multiple posterior draws, in con ver ging to a kernel which has been used to make predictions. W e sample 20 datapoints y from a GP with RBF kernel (the supplement describes GPs), k RBF ( x , x 0 ) = exp( − 0 . 5 || x − x 0 || /` 2 ) , at random input locations. Conditioned on these data, we then sample multiple posterior dra ws, y (1) ∗ , . . . , y ( W ) ∗ , each containing 20 datapoints, from a GP with a spectral mixture kernel [ 14 ] with two components (the prediction kernel). The prediction kernel has deliberately not been trained to fit the data kernel. T o reconstruct the prediction kernel, we learn the parameters θ of a randomly initialized spectral mixture kernel with five components, by optimizing the predictiv e conditional marginal likelihood Q W j =1 p ( y ( j ) ∗ | y , k θ ) wrt θ . Figure 1 compares the learned kernels for different numbers of posterior draws W against the data kernel (RBF) and the prediction kernel (spectral mixture). For a single posterior draw , the learned kernel captures the high-frequency component of the prediction k ernel b ut fails at reconstructing the low-frequenc y component. Only with multiple draws does the learned kernel capture the longer- range dependencies. The fact that the learned kernel conv erges to the pr ediction kernel , which is different from the data kernel , sho ws the consistenc y of our procedure, which could be used to infer aspects of human inductiv e biases. 4.2 Progr essive Function Learning W e asked humans to extrapolate beyond training data in two sets of 5 functions, each drawn from GPs with kno wn kernels. The learners extrapolated on these problems in sequence, and thus had an opportunity to progressiv ely learn more about the underlying kernel in each set. T o further test 4 0 0.2 0.4 0.6 0.8 1 -2 -1 0 1 2 3 4 (a) 1 Posterior Draw 0 0.2 0.4 0.6 0.8 1 -2 -1 0 1 2 3 4 (b) 10 Posterior Draws 0 0.2 0.4 0.6 0.8 1 -2 -1 0 1 2 3 4 Pred ictio n kernel Data kernel Learned kernel (c) 20 Posterior Draws Figure 1: Reconstructing a kernel used for predictions: T raining data were generated with an RBF kernel (green, ·− ), and multiple independent posterior predictions were dra wn from a GP with a spectral-mixture prediction kernel (blue, - -). As the number of posterior draws increases, the learned spectral-mixture kernel (red, —) con ver ges to the prediction kernel. 0 5 10 -2.5 -2 -1.5 -1 -0.5 0 0.5 1 (a) 0 5 10 -4 -2 0 2 4 (b) 0 5 10 -2 -1 0 1 2 (c) 0 5 10 -2 -1 0 1 2 (d) 0 5 10 -2 -1 0 1 (e) 0 5 10 -3 -2 -1 0 1 (f) 0 2 4 0 0.5 1 1.5 (g) 0 2 4 0 0.5 1 1.5 Human kernel Data kernel RBF kernel (h) 0 0.5 1 1.5 2 -8 -6 -4 -2 0 2 4 (i) 0 0.5 1 1.5 2 -8 -6 -4 -2 0 2 4 (j) 0 0.5 1 1.5 2 -6 -4 -2 0 2 (k) 0 0.5 1 1.5 2 -6 -4 -2 0 2 4 6 (l) 0 0.5 1 1.5 2 -4 -2 0 2 4 6 8 (m) 0 0.5 1 1.5 2 -8 -6 -4 -2 0 2 (n) (o) (p) Figure 2: Progressiv e Function Learning. Humans are sho wn functions in sequence and asked to make e xtrapolations. Observed data are in black, human predictions in blue, and true e xtrapolations in dashed black. (a)-(f): observ ed data are drawn from a rational quadratic kernel, with identical data in (a) and (f). (g): Learned human and RBF k ernels on (a) alone, and (h): on (f), after seeing the data in (a)-(e). The true data generating rational quadratic kernel is shown in red. (i)-(n): observed data are drawn from a product of spectral mixture and linear kernels with identical data in (i) and (n). (o): the empirical estimate of the human posterior covariance matrix from all responses in (i)-(n). (p): the true posterior cov ariance matrix for (i)-(n). progressiv e function learning, we repeated the first function at the end of the experiment, for six functions in each set. W e asked for extr apolation judgments because they pro vide more information about inducti ve biases than interpolation, and pose dif ficulties for con ventional Gaussian process kernels [ 14 , 10 , 30 ]. The observed functions are shown in black in Figure 2 , the human responses in blue, and the true extrapolation in dashed black. In the first two rows, the black functions are drawn from a GP 5 with a rational quadratic (RQ) kernel [ 12 ] (for hea vy tailed correlations), and there are 20 human participants. W e sho w the learned human kernel, the data generating kernel, the human kernel learned from a spectral mixture, and an RBF kernel trained only on the data, in Figures 2(g) and 2(h) , respectiv ely corresponding to Figures 2(a) and 2(f) . Initially , both the human learners and RQ kernel show heavy tailed behaviour , and a bias for decreasing correlations with distance in the input space, but the human learners ha ve a high degree of variance. By the time they have seen Figure 2(h) , the y are more confident in their predictions, and more accurately able to estimate the true signal variance of the function. V isually , the extrapolations look more confident and reasonable. Indeed, the human learners adapt their representations (e.g., learned kernels) to more data. Ho we ver , we can see in Figure 2(f) that the human learners are still ov er-estimating the tails of the kernel, perhaps suggesting a strong prior bias for heavy-tailed correlations. The learned RBF kernel, by contrast, cannot capture the hea vy tailed nature of the training data (long range correlations), due to its Gaussian parametrization. Moreover , the learned RBF kernel under- estimates the signal v ariance of the data, because it ov erestimates the noise v ariance (not sho wn), to explain a way the heavy tailed properties of the data (its model misspecification). In the second tw o rows, we consider a problem with highly complex structure, and only 10 par - ticipants. Here, the functions are drawn from a product of spectral mixture and linear kernels. As the participants see more functions, they appear to e xpect linear trends, and become more similar in their predictions. In Figures 2(o) and 2(p) , we show the learned and true predicti ve correlation matrices using empirical estimators which indicate similar correlation structure. 4.3 Discovering Uncon ventional Ker nels The e xperiments reported in this section follo w the same general procedure described in section 4.2 . In this case, 40 human participants were asked to e xtrapolate from two single training sets, in coun- terbalanced order: a sawtooth function (Figure 3(a) ), and a step function (Figure 3(b) ), with training data shown as dashed black lines. These types of functions are notoriously difficult for standard Gaussian process kernels [ 12 ], due to sharp discontinuities and non-stationary behaviour . In Figures 3(a) , 3(b) , 3(c) , we used agglomer- ativ e clustering to process the human responses into three cate gories, shown in purple, green, and blue. The empirical cov ariance matrix of the first cluster (Figure 3(d) ) shows the dependencies of the sawtooth form that characterize this cluster . In Figures 3(e) , 3(f) , 3(g) , we sample from the learned human kernels, following the same colour scheme. The samples appear to replicate the hu- man beha viour , and the purple samples provide reasonable extrapolations. By contrast, posterior samples from a GP with a spectral mixture kernel trained on the black data in this case quickly rev ert to a prior mean, as sho wn in Fig 3(h) . The data are sufficiently sparse, non-differentiable, and non-stationary , that the spectral mixture kernel is less inclined to produce a long range e xtrapolation than human learners, who attempt to generalise from a very small amount of information. For the step function, we clustered the human extrapolations based on response time and total vari- ation of the predicted function. Responses that took between 50 and 200 seconds and did not vary by more than 3 units, shown in Figure 3(i) , appeared reasonable. The other responses are shown in Figure 3(j) . The empirical cov ariance matrices of both sets of predictions in Figures 3(k) and 3(l) show the characteristics of the responses. While the first matrix exhibits a block structure indicating step-functions, the second matrix shows fast changes between positi ve and negati ve dependencies characteristic of the high frequency responses. Posterior sample extrapolations using the empirical human kernels are shown in Figures 3(m) and 3(n) . In Figures 3(o) and 3(p) we sho w posterior samples from GPs with spectral mixture and RBF kernels, trained on the black data (e.g., giv en the same information as the human learners). The spectral mixture kernel is able to extract some struc- ture (some horizontal and vertical movement), but is o verconfident, and unconvincing compared to the human kernel extrapolations. The RBF kernel is unable to learn much structure in the data. 4.4 Human Occam’s Razor If you were asked to predict the next number in the sequence 9 , 15 , 21 , . . . , you are likely more inclined to guess 27 than 149 . 5 . Howe ver , we can produce either answer using different h ypotheses 6 0 0.5 1 -1 0 1 2 (a) 0 0.5 1 -1 0 1 2 (b) 0 0.5 1 -1 0 1 2 (c) (d) 0 0.5 1 -1 0 1 2 (e) 0 0.5 1 -1 0 1 2 (f) 0 0.5 1 -1 0 1 2 (g) 0 0.5 1 -1 -0.5 0 0.5 1 1.5 2 (h) 0 0.5 1 -1 -0.5 0 0.5 1 (i) 0 0.5 1 -1 -0.5 0 0.5 1 (j) (k) (l) 0 0.5 1 -1 -0.5 0 0.5 1 (m) 0 0.5 1 -1 -0.5 0 0.5 1 (n) 0 0.5 1 -1 -0.5 0 0.5 1 (o) 0 0.5 1 -1 -0.5 0 0.5 1 (p) Figure 3: Learning Unconv entional Kernels. (a)-(c): sawtooth function (dashed black), and three clusters of human extrapolations. (d) empirically estimated human covariance matrix for (a). (e)-(g): corresponding posterior draws for (a)-(c) from empirically estimated human cov ariance matrices. (h): posterior predicti ve draws from a GP with a spectral mixture kernel learned from the dashed black data. (i)-(j): step function (dashed black), and two clusters of human extrapolations. (k) and (l) are the empirically estimated human covariance matrices for (i) and (j), and (m) and (n) are posterior samples using these matrices. (o) and (p) are respecti vely spectral mixture and RBF k ernel extrapolations from the data in black. that are entirely consistent with the data. Occam’ s r azor describes our natural tendency to fa vour the simplest hypothesis that fits the data, and is of foundational importance in statistical model selection. For example, MacKay [ 31 ] argues that Occam’ s razor is automatically embodied by the marginal likelihood in performing Bayesian inference: indeed, in our number sequence example, marginal likelihood computations sho w that 27 is millions of times more probable than 149 . 5 , ev en if the prior odds are equal. Occam’ s razor is vitally important in nonparametric models such as Gaussian processes, which have the fle xibility to represent infinitely many consistent solutions to an y giv en problem, b ut a void o ver - fitting through Bayesian inference. For example, the marginal likelihood of a Gaussian process (supplement) separates into automatically calibrated model fit and model complexity terms, some- times referred to as automatic Occam’ s razor [ 32 ]. The marginal likelihood p ( y |M ) is the probability that if we were to randomly sample parame- ters from M that we would create dataset y [e.g., 32 , 10 ]. Simple models can only generate a small number of datasets, but because the marginal lik elihood must normalise, it will generate these datasets with high probability . Comple x models can generate a wide range of datasets, but each with typically low probability . For a gi ven dataset, the marginal likelihood will fav our a model of more appropriate complexity . This argument is illustrated in Fig 4(a) . Fig 4(b) illustrates this principle with GPs. Here we examine Occam’ s razor in human learning, and compare the Gaussian process marginal likelihood ranking of functions, all consistent with the data, to human preferences. W e generated a 7 All Possible Datasets p(y|M) Complex Simple Appropriate (a) −2 0 2 4 6 8 −2 −1 0 1 2 Output, f(x) Input, x (b) Figure 4: Bayesian Occam’ s Razor . a) The marginal likelihood (evidence) vs. all possible datasets. The vertical black line corresponds to an example dataset ˜ y . b) Posterior mean functions of a GP with RBF k ernel and too short, too large, and maximum mar ginal likelihood length-scales. Data are denoted by crosses. dataset sampled from a GP with an RBF kernel, and presented users with a subsample of 5 points, as well as sev en possible GP function fits, internally labelled as follows: (1) the predictiv e mean of a GP after maximum mar ginal lik elihood hyperparameter estimation; (2) the generating function; (3-7) the predicti ve means of GPs with larger to smaller length-scales (simpler to more complex fits). W e repeated this procedure four times, to create four datasets in total, and acquired 50 human rankings on each, for 200 total rankings. Each participant was sho wn the same unlabelled functions but with different random orderings. The datasets, along with participant instructions, are in the supplement, and av ailable at http://functionlearning.com/ . 1 2 3 4 5 6 7 0 20 40 60 80 Function Label First Place Votes (a) 1 2 3 4 5 6 7 1 2 3 4 5 6 7 First Choice Ranking Average Human Ranking (b) 1 2 3 4 5 6 7 2 3 4 5 6 7 GP Marginal Likelihood Ranking Average Human Ranking T rut h ML -1.0 -1.5 -2.5 +0.5 +1.0 (c) Figure 5: Human Occam’ s Razor . (a) Number of first place (highest ranking) votes for each function. (b) A v erage human ranking (with standard de viations) of functions compared to first place ranking defined by (a). (c) A verage human ranking vs. av erage GP marginal lik elihood ranking of functions. ‘ML ’ = marginal likelihood optimum, ‘T ruth’ = true extrapolation. Blue numbers are offsets to the log length-scale from the marginal likelihood optimum. Positiv e offsets correspond to simpler solutions. Figure 5(a) shows the number of times each function was voted as the best fit to the data. The proportion of first place votes for each function follo ws the internal (latent) ordering defined above. The maximum marginal likelihood solution receives the most ( 37 %) first place votes. Functions 2 , 3 , and 4 receiv ed similar numbers (between 15% and 18%) of first place votes; these choices were all strongly fav oured, and in total hav e more votes than the maximum mar ginal lik elihood solution. The solutions which have a smaller length-scale (greater complexity) than the marginal likelihood best fit – represented by functions 5 , 6 , and 7 – received a relati vely small number of first place votes. These findings suggest that on a verage humans prefer overly simple to ov erly complex e xplanations of the data. Moreover , participants generally agree with the GP mar ginal lik elihood’ s first choice preference, even over the true generating function. Howe ver , these data also suggest that participants hav e a wide array of prior biases, leading to different people often choosing very different looking functions as their first choice fit. Furthermore, 86 % ( 43 / 50 ) of participants responded that their first ranked choice was “likely to ha ve generated the data” and looks “v ery similar” to what they would hav e imagined. It’ s possible for highly probable solutions to be underrepresented in Figure 5(a) : we might imagine, for example, that a particular solution is nev er ranked first, but always second. In Figure 5(b) , we show the average rankings, with standard deviations (the standard errors are stdev / √ 200 ), compared 8 to the first choice rankings, for each function. There is a general correspondence between rankings, suggesting that although human distributions over functions hav e different modes, these distributions hav e a similar allocation of probability mass. The standard deviations suggest that there is relativ ely more agreement that the complex small length-scale functions (labels 5, 6, 7) are improbable, than about specific preferences for functions 1, 2, 3, and 4. Finally , in Figure 5(c) , we compare the av erage human rankings with the a verage GP marginal like- lihood rankings. There are clear trends: (1) humans agree with the GP marginal likelihood about the best fit, and that empirically decreasing the length-scale below the best fit v alue monotonically decreases a solution’ s probability; (2) humans penalize simple solutions less than the marginal like- lihood, with function 4 receiving a last (7th) place ranking from the marginal lik elihood. Despite the observed human tendenc y to f av our simplicity more than the GP mar ginal likelihood, Gaussian process marginal likelihood optimisation is surprisingly biased towards under -fitting in function space. If we generate data from a GP with a known length-scale, the mode of the marginal likelihood, on av erage, will over -estimate the true length-scale (Figures 1 and 2 in the supplement). If we are unconstrained in estimating the GP co variance matrix, we will conv erge to the maximum likelihood estimator , ˆ K = ( y − ¯ y )( y − ¯ y ) > , which is degenerate and therefore biased. Parametrizing a cov ariance matrix by a length-scale (for example, by using an RBF kernel), restricts this matrix to a low-dimensional manifold on the full space of co variance matrices. A biased estimator will remain biased when constrained to a lower dimensional manifold, as long as the manifold allo ws mo vement in the direction of the bias. Increasing a length-scale mov es a covariance matrix to wards the de- generacy of the unconstrained maximum likelihood estimator . W ith more data, the lo w-dimensional manifold becomes more constrained, and less influenced by this under-fitting bias. 5 Discussion W e have shown that (1) human learners hav e systematic expectations about smooth functions that deviate from the inducti ve biases inherent in the RBF kernels that have been used in past models of function learning; (2) it is possible to extract kernels that reproduce qualitati ve features of human inductiv e biases, including the variable sawtooth and step patterns; (3) that human learners fav our smoother or simpler functions, e ven in comparison to GP models that tend to over -penalize com- plexity; and (4) that is it possible to b uild models that extrapolate in human-lik e ways which go beyond traditional stationary and polynomial kernels. W e hav e focused on human extrapolation from noise-free nonparametric relationships. This ap- proach complements past work emphasizing simple parametric functions and the role of noise [e.g., 25 ], but kernel learning might also be applied in these other settings. In particular , iterated learning (IL) experiments [ 24 ] provide a way to draw samples that reflect human learners’ a priori expecta- tions. Like most function learning experiments, past IL e xperiments have presented learners with sequential data. Our approach, follo wing Little and Shif frin [ 25 ], instead presents learners with plots of functions. This method is useful in reducing the effects of memory limitations and other sources of noise (e.g., in perception). It is possible that people sho w different inductive biases across these two presentation modes. Future work, using multiple presentation formats with the same underlying relationships, will help resolve these questions. Finally , the ideas discussed in this paper could be applied more generally , to discov er interpretable properties of unknown models from their predictions. Here one encounters fascinating questions at the intersection of activ e learning, experimental design, and information theory . Acknowledgments W e thank T om Minka for helpful discussions. References [1] W .S. McCulloch and W . Pitts. A logical calculus of the ideas immanent in nerv ous activity . Bulletin of mathematical biology , 5(4):115–133, 1943. [2] Christopher M. Bishop. P attern Reco gnition and Machine Learning . Springer , 2006. 9 [3] K. Doya, S. Ishii, A. Pouget, and R.P .N. Rao. Bayesian br ain: pr obabilistic appr oac hes to neural coding . MIT Press, 2007. [4] Zoubin Ghahramani. Probabilistic machine learning and artificial intelligence. Nature , 521 (7553):452–459, 2015. [5] Daniel M W olpert, Zoubin Ghahramani, and Michael I Jordan. An internal model for sensori- motor integration. Science , 269(5232):1880–1882, 1995. [6] David C Knill and Whitman Richards. P er ception as Bayesian inference . Cambridge Univ er- sity Press, 1996. [7] Sophie Deneve. Bayesian spiking neurons i: inference. Neural computation , 20(1):91–117, 2008. [8] Thomas L Griffiths and Joshua B T enenbaum. Optimal predictions in ev eryday cognition. Psychological Science , 17(9):767–773, 2006. [9] J.B. T enenbaum, C. Kemp, T .L. Griffiths, and N.D. Goodman. How to gro w a mind: Statistics, structure, and abstraction. Science , 331(6022):1279–1285, 2011. [10] Andrew Gordon W ilson. Covariance kernels for fast automatic pattern discovery and extrap- olation with Gaussian pr ocesses . PhD thesis, Univ ersity of Cambridge, 2014. http://www.cs.cmu.edu/ ˜ andrewgw/andrewgwthesis.pdf . [11] R.M. Neal. Bayesian Learning for Neural Networks . Springer V erlag, 1996. ISBN 0387947248. [12] C. E. Rasmussen and C. K. I. W illiams. Gaussian pr ocesses for Mac hine Learning . MIT Press, 2006. [13] T ommi Jaakkola, David Haussler , et al. Exploiting generativ e models in discriminative classi- fiers. Advances in neural information pr ocessing systems , pages 487–493, 1998. [14] Andrew Gordon W ilson and Ryan Prescott Adams. Gaussian process kernels for pattern dis- cov ery and extrapolation. International Confer ence on Machine Learning (ICML) , 2013. [15] J Douglas Carroll. Functional learning: The learning of continuous functional mappings relat- ing stimulus and response continua. ETS Resear ch Bulletin Series , 1963(2), 1963. [16] Kyunghee K oh and David E Meyer . Function learning: Induction of continuous stimulus- response relations. Journal of Experimental Psychology: Learning, Memory , and Cognition , 17(5):811, 1991. [17] Edward L DeLosh, Jerome R Busemeyer , and Mark A McDaniel. Extrapolation: The sine qua non for abstraction in function learning. Journal of Experimental Psycholo gy: Learning, Memory , and Cognition , 23(4):968, 1997. [18] Jerome R Busemeyer , Eunhee Byun, Edward L Delosh, and Mark A McDaniel. Learning functional relations based on experience with input-output pairs by humans and artificial neural networks. Concepts and Cate gories , 1997. [19] Thomas L Griffiths, Chris Lucas, Joseph W illiams, and Michael L Kalish. Modeling human function learning with gaussian processes. In Advances in Neural Information Pr ocessing Systems , pages 553–560, 2009. [20] Christopher G Lucas, Thomas L Griffiths, Joseph J Williams, and Michael L Kalish. A rational model of function learning. Psychonomic b ulletin & re view , pages 1–23, 2015. [21] C.E. Rasmussen and Z. Ghahramani. Infinite mixtures of Gaussian process e xperts. In Ad- vances in neural information pr ocessing systems 14: proceedings of the 2002 confer ence , v ol- ume 2, page 881. MIT Press, 2002. [22] Christopher G Lucas, Douglas Sterling, and Charles Kemp. Superspace extrapolation rev eals inductiv e biases in function learning. In Cognitive Science Society , 2012. [23] Mark A Mcdaniel and Jerome R Busemeyer . The conceptual basis of function learning and extrapolation: Comparison of rule-based and associative-based models. Psychonomic bulletin & r eview , 12(1):24–42, 2005. [24] Michael L Kalish, Thomas L Griffiths, and Stephan Lewando wsky . Iterated learning: Intergen- erational knowledge transmission rev eals inducti ve biases. Psychonomic Bulletin & Review , 14(2):288–294, 2007. 10 [25] Daniel R Little and Richard M Shif frin. Simplicity bias in the estimation of causal functions. In Proceedings of the 31st Annual Confer ence of the Cognitive Science Society , pages 1157– 1162, 2009. [26] Samuel GB Johnson, Andy Jin, and Frank C K eil. Simplicity and goodness-of-fit in e xplana- tion: The case of intuitive curve-fitting. In Pr oceedings of the 36th Annual Conference of the Cognitive Science Society , pages 701–706, 2014. [27] Samuel J Gershman, Edward V ul, and Joshua B T enenbaum. Multistability and perceptual inference. Neural computation , 24(1):1–24, 2012. [28] Thomas L Griffiths, Edward V ul, and Adam N Sanborn. Bridging lev els of analysis for prob- abilistic models of cognition. Curr ent Dir ections in Psycholo gical Science , 21(4):263–268, 2012. [29] Edward V ul, Noah Goodman, Thomas L Griffiths, and Joshua B T enenbaum. One and done? optimal decisions from very fe w samples. Cognitive science , 38(4):599–637, 2014. [30] Andrew Gordon W ilson, Elad Gilboa, Arye Nehorai, and John P . Cunningham. Fast kernel learning for multidimensional pattern extrapolation. In Advances in Neural Information Pr o- cessing Systems , 2014. [31] David JC MacKay . Information theory , infer ence, and learning algorithms . Cambridge Uni- versity Press, 2003. [32] Carl Edward Rasmussen and Zoubin Ghahramani. Occam’ s razor . In Neural Information Pr ocessing Systems (NIPS) , 2001. [33] Christopher KI Williams. Computation with infinite neural netw orks. Neural Computation , 10 (5):1203–1216, 1998. [34] Andrew Gordon W ilson. A process over all stationary k ernels. T echnical report, Uni versity of Cambridge, 2012. Supplementary Material In the supplementary material, av ailable at http://www.cs.cmu.edu/ ˜ andrewgw/ humansupp.pdf , we provide a brief revie w of Gaussian processes, and additional experiments re- garding the under-fitting property of GP maximum marginal lik elihood estimation of kernel length- scales. W e also provide the instructions and some of the questions asked in the human experiments. T o participate in the exact experiments, see http://www.functionlearning.com . 11
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment