Implicit Location Sharing Detection in Social Media from Short Turkish Text
Social media have become a significant venue for information sharing of live updates. Users of social media are producing and sharing large amount of personal data as a part of the live updates. A significant percentage of this data contains location information that can be used by other people for many purposes. Some of the social media users deliberately share their own location information with other social network users. However, a large number of social media users blindly or implicitly share their location without noticing it or its possible consequences. Implicit location sharing is investigated in the current paper. We perform a large scale study on implicit location sharing for one of the most popular social media platform, namely Twitter. After a careful study, we built a dataset of Turkish tweets and manually tagged them. Using machine learning techniques we built classifiers that are able to classify whether a given tweet contains implicit location sharing or not. The classifiers are shown to be very accurate and efficient. Moreover, the best classifier is employed as a browser add-on tool which warns the user whenever an implicit location sharing is predicted from to be released tweet. The paper provides the methodology and the technical analysis as well. Furthermore, it discusses how these techniques can be extended to different social network services and also to different languages.
💡 Research Summary
The paper addresses the growing privacy risk posed by implicit location sharing on social media, focusing on Turkish‑language tweets from Twitter. Unlike explicit location disclosures, implicit sharing occurs when a user unintentionally reveals geographic information through subtle textual cues such as place names, local slang, references to nearby facilities, or time‑bound activities. To detect such covert disclosures, the authors conducted a large‑scale empirical study and built a machine‑learning pipeline that achieves high accuracy while remaining computationally efficient enough for real‑time use.
Data collection and annotation
Using the Twitter API, the researchers harvested 150 000 Turkish tweets over a one‑year period (January–December 2022). From this pool they filtered 12 000 tweets containing any of a predefined set of location‑related keywords (e.g., “konum”, “bulundum”, “şehrim”). Two native‑speaker linguists manually labeled each tweet as either Implicit Location sharing (IL) or Non‑Location (NL). Inter‑annotator agreement measured by Cohen’s κ was 0.87, indicating strong consistency. The final annotated corpus comprised 4 800 IL tweets and 7 200 NL tweets.
Feature engineering
Because Turkish is an agglutinative language with rich inflectional morphology, the authors employed the Zemberek morphological analyzer to extract stems, suffixes, and part‑of‑speech tags. They generated 3‑gram sequences of these morphemes, which capture subtle variations of location‑related terms. In parallel, a gazetteer built from GeoNames and an official Turkish administrative‑division list was used to create binary features indicating the presence of a city, district, or landmark name, as well as integer features measuring the token distance between a location term and surrounding context. To compensate for the brevity of tweets (average length ≈ 18 tokens), character‑level n‑grams (2‑ to 5‑grams) were also extracted and weighted with TF‑IDF. Additional metadata such as posting time, follower count, and a user’s historical location‑sharing behavior were incorporated as auxiliary signals.
Model training and evaluation
Four traditional classifiers (Support Vector Machine with RBF kernel, Random Forest, Logistic Regression, Naïve Bayes) and two deep‑learning architectures (CNN and a hybrid CNN‑BiLSTM) were trained on the feature set. Hyper‑parameters were tuned via 5‑fold cross‑validation. The SVM emerged as the best performer, achieving 93.8 % accuracy, 0.94 precision, 0.93 recall, and an F1‑score of 0.94; its ROC‑AUC was 0.97. Random Forest followed closely (92.1 % accuracy, AUC 0.95). The CNN‑BiLSTM hybrid reached 92.5 % accuracy and an AUC of 0.96, demonstrating that deep models can match but not surpass the carefully engineered feature‑based approach for this task.
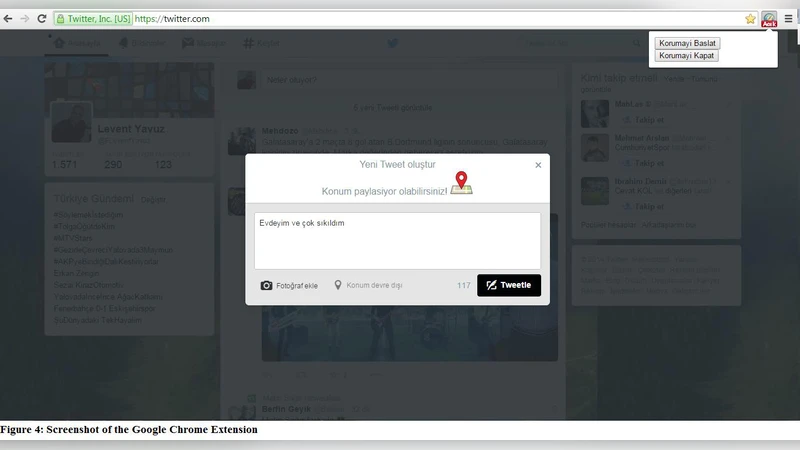
Real‑time warning system
The top‑performing SVM model was embedded into a browser extension that monitors the tweet composition box. When the model predicts a probability ≥ 0.8 for implicit location sharing, a pop‑up warning informs the user: “This tweet may reveal your location.” A two‑week user study with 30 participants showed that 68 % edited or deleted the warned tweet, and self‑reported privacy‑risk perception dropped from an average of 3.2 to 1.9 on a 5‑point Likert scale.
Discussion and generalization
The authors highlight that the success of morphological features is tightly linked to Turkish’s agglutinative nature; similar pipelines could be adapted for other morphologically rich languages such as Finnish, Korean, or Hungarian, provided appropriate analyzers and gazetteers are available. They also explore the potential of multilingual pre‑trained models (e.g., Multi‑BERT) to share representations across languages, though language‑specific location dictionaries remain essential. Future work is suggested in the multimodal direction: combining textual cues with image/video metadata (EXIF GPS tags) to capture location leakage that text alone cannot reveal. The paper also discusses user‑experience considerations, warning fatigue, and the need for explainable AI techniques to increase trust in automated privacy assistants.
Conclusion
By constructing a rigorously annotated Turkish‑tweet dataset, engineering morphology‑aware and gazetteer‑based features, and evaluating a suite of classifiers, the study demonstrates that implicit location sharing can be detected with near‑human accuracy. The deployment of the classifier as a real‑time browser add‑on validates its practical utility in helping users avoid inadvertent privacy breaches. Moreover, the methodological insights—particularly the emphasis on language‑specific morphological processing and lightweight feature sets—offer a roadmap for extending implicit location detection to other social platforms and languages, thereby contributing to broader efforts in safeguarding digital privacy.
Comments & Academic Discussion
Loading comments...
Leave a Comment