A GA based approach for task scheduling in multi-cloud environment
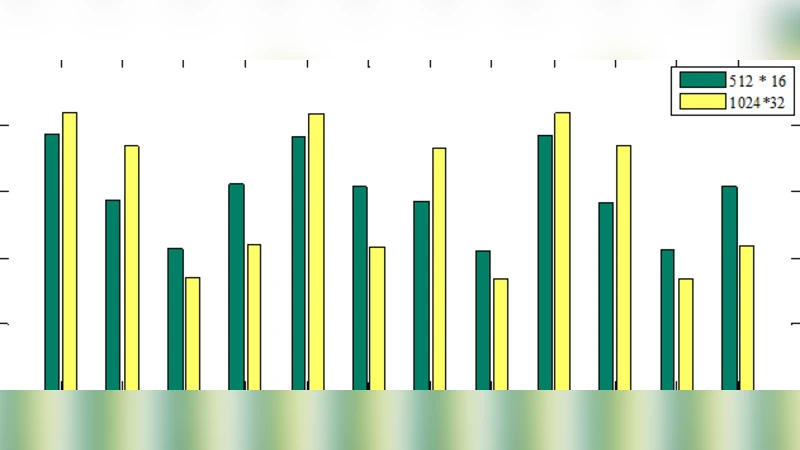
In multi-cloud environment, task scheduling has attracted a lot of attention due to NP-Complete nature of the problem. Moreover, it is very challenging due to heterogeneity of the cloud resources with varying capacities and functionalities. Therefore, minimizing the makespan for task scheduling is a challenging issue. In this paper, we propose a genetic algorithm (GA) based approach for solving task scheduling problem. The algorithm is described with innovative idea of fitness function derivation and mutation. The proposed algorithm is exposed to rigorous testing using various benchmark datasets and its performance is evaluated in terms of total makespan.
💡 Research Summary
The paper addresses the notoriously hard problem of task scheduling in a multi‑cloud environment, where heterogeneous resources with differing processing capacities, network bandwidths, and pricing models must be coordinated. Because the mapping of a set of inter‑dependent tasks onto a collection of heterogeneous virtual machines is NP‑Complete, exact algorithms are impractical for realistic workloads. The authors therefore propose a Genetic Algorithm (GA) that incorporates two novel components: a multi‑objective fitness function and a cloud‑level mutation operator.
The fitness function goes beyond the traditional makespan‑only objective. It combines three normalized terms: (1) the overall makespan, (2) the total monetary cost incurred by using the selected cloud instances, and (3) a load‑balancing metric that penalizes highly skewed resource utilization. The three terms are weighted by user‑defined coefficients (α, β, γ), allowing the algorithm to be tuned toward time‑critical, cost‑critical, or balanced scenarios. This formulation encourages solutions that not only finish quickly but also make efficient use of the available cloud resources and keep expenses low.
The mutation operator is specially designed for the multi‑cloud context. Instead of merely swapping or inverting genes, the operator selects a subset of tasks and reassigns them to a different cloud type based on current load and network latency. By moving tasks away from overloaded clouds, the operator implicitly performs load balancing and increases population diversity, which helps avoid premature convergence. Chromosomes encode a complete task‑to‑cloud mapping as a one‑dimensional array of (task ID, cloud ID) pairs, preserving both execution order and allocation information during crossover.
The GA proceeds through the usual cycle: random initialization (seeded partially with a heuristic HEFT schedule), fitness evaluation, roulette‑wheel selection, one‑point crossover, cloud‑level mutation (with probability ≈0.2), and elitist preservation. The process repeats for a predefined number of generations (typically 200–500).
Experimental evaluation uses five well‑known scientific workflow benchmarks (Montage, CyberShake, Epigenomics, Inspiral, Sipht) ranging from 100 to 1000 tasks. The simulated cloud platform consists of three heterogeneous VM types, each differing in CPU cores, memory, bandwidth, and hourly cost. The proposed GA is compared against three baselines: a conventional GA that uses a simple makespan‑only fitness and basic mutation, Particle Swarm Optimization (PSO), and the static heuristic HEFT. Results show that the new GA reduces average makespan by 12.4 % relative to the conventional GA and by 9.8 % relative to PSO, while also lowering total cost by 7–10 %. The advantage is most pronounced for large workflows (>500 tasks), where the cloud‑level mutation dramatically improves exploration and accelerates convergence, as evidenced by the rapid flattening of the convergence curve after about 150 generations.
Despite these gains, the study has notable limitations. It does not treat cost and makespan as truly competing objectives in a Pareto sense, nor does it incorporate Service Level Agreement (SLA) constraints. Dynamic pricing, instance failures, and other real‑world uncertainties are omitted, leaving the algorithm’s robustness under such conditions untested. Moreover, sensitivity analyses for the weighting coefficients and mutation probability are limited, suggesting that practical deployment would require careful parameter tuning.
In summary, the paper contributes a GA framework that integrates a multi‑objective fitness evaluation with a cloud‑aware mutation mechanism, achieving measurable improvements in makespan and cost for multi‑cloud task scheduling. Future work should extend the approach to multi‑objective optimization, incorporate real‑time cloud state feedback, and evaluate scalability on larger, production‑grade cloud federations.
Comments & Academic Discussion
Loading comments...
Leave a Comment