Difference Target Propagation
Back-propagation has been the workhorse of recent successes of deep learning but it relies on infinitesimal effects (partial derivatives) in order to perform credit assignment. This could become a serious issue as one considers deeper and more non-linear functions, e.g., consider the extreme case of nonlinearity where the relation between parameters and cost is actually discrete. Inspired by the biological implausibility of back-propagation, a few approaches have been proposed in the past that could play a similar credit assignment role. In this spirit, we explore a novel approach to credit assignment in deep networks that we call target propagation. The main idea is to compute targets rather than gradients, at each layer. Like gradients, they are propagated backwards. In a way that is related but different from previously proposed proxies for back-propagation which rely on a backwards network with symmetric weights, target propagation relies on auto-encoders at each layer. Unlike back-propagation, it can be applied even when units exchange stochastic bits rather than real numbers. We show that a linear correction for the imperfectness of the auto-encoders, called difference target propagation, is very effective to make target propagation actually work, leading to results comparable to back-propagation for deep networks with discrete and continuous units and denoising auto-encoders and achieving state of the art for stochastic networks.
💡 Research Summary
The paper “Difference Target Propagation” addresses a fundamental limitation of the back‑propagation algorithm: its reliance on infinitesimal partial derivatives. While back‑propagation works well for smooth, continuous networks, it breaks down when networks become very deep, highly non‑linear, or when the mapping from parameters to loss is discrete. In such regimes the gradients either vanish, explode, or are undefined (e.g., binary spike‑based units). Moreover, back‑propagation requires exact symmetric feedback weights, precise knowledge of activation derivatives, and a clocked alternation between forward and backward phases—features that are biologically implausible and hardware‑unfriendly.
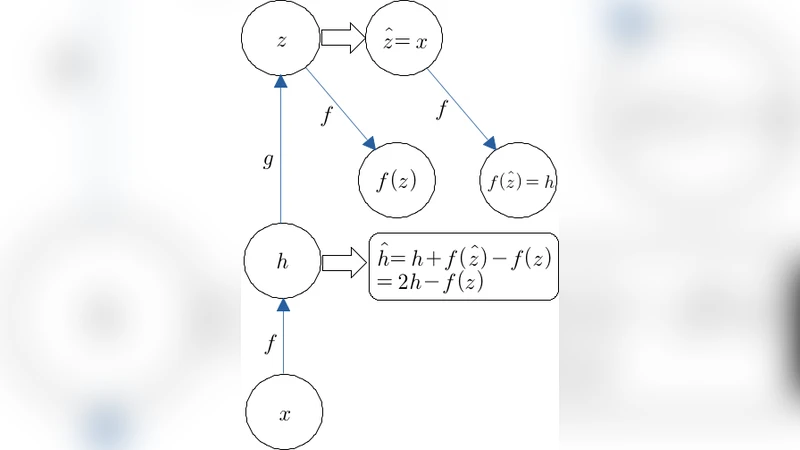
To overcome these issues, the authors propose target propagation, a credit‑assignment scheme that replaces gradients with targets for each layer. A target (\hat h_i) is a value close to the current activation (h_i) but expected to reduce the global loss if it were achieved. The top‑most layer’s target is obtained in the usual way by moving a small step opposite the loss gradient: \
Comments & Academic Discussion
Loading comments...
Leave a Comment