A new hybrid stemming algorithm for Persian
Stemming has been an influential part in Information retrieval and search engines. There have been tremendous endeavours in making stemmer that are both efficient and accurate. Stemmers can have three method in stemming, Dictionary based stemmer, statistical-based stemmers, and rule-based stemmers. This paper aims at building a hybrid stemmer that uses both Dictionary based method and rule-based method for stemming. This ultimately helps the efficacy and accurateness of the stemmer.
💡 Research Summary
The paper presents a hybrid stemming algorithm specifically designed for Persian, a language characterized by a rich set of suffixes and numerous irregular morphological forms. Recognizing the limitations of existing single‑approach stemmers—dictionary‑based methods that excel at handling irregularities but suffer from coverage gaps, and rule‑based methods that are fast yet struggle with complex suffix combinations—the authors propose a system that integrates both strategies to achieve higher accuracy without sacrificing efficiency.
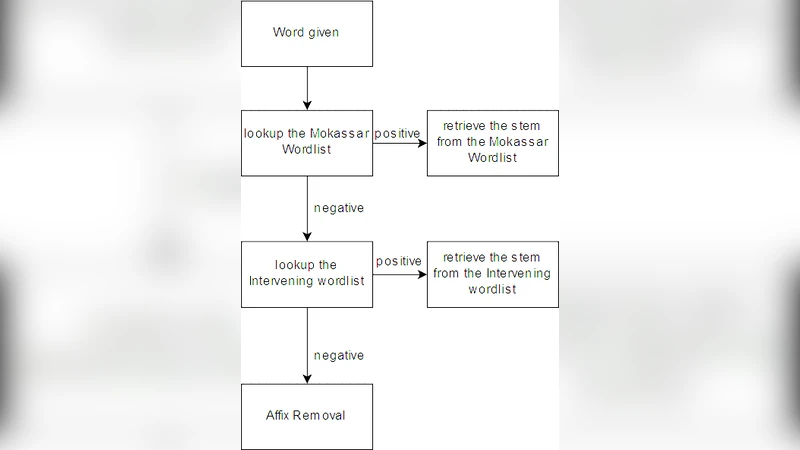
The first component is a comprehensive lexical dictionary. The authors combine publicly available Persian lexical resources with a large‑scale web‑crawled corpus, automatically extracting root‑derived form pairs using a morphological analyzer. Human linguists then validate and augment the list, resulting in a dictionary containing over 1.5 million roots and 3 million derived forms. This resource captures irregular verb conjugations, plural forms, and other non‑concatenative transformations that rule‑based systems typically miss.
The second component is a rule engine that encodes 120 suffix‑removal rules. Each rule specifies conditions such as minimum stem length, phonological harmony, and permissible suffix sequences. The engine employs a longest‑match strategy followed by a back‑check: after stripping a suffix, it verifies whether the resulting stem exists in the dictionary; if not, the rule is rolled back and the next candidate is tried. This mechanism prevents over‑stemming and handles cases where multiple suffixes are stacked.
Integration follows a two‑stage workflow. When a token is found in the dictionary, the dictionary‑based module instantly returns the canonical root. If the token is absent, the rule engine processes the word, stripping suffixes step by step while repeatedly consulting the dictionary after each removal. Consequently, newly encountered words are handled by the rule system, yet any intermediate stem that matches the dictionary can be corrected for irregular forms.
Evaluation was conducted on two datasets: a publicly available Persian news corpus (100 k documents) and a manually annotated root‑form dataset (50 k entries). Standard IR metrics—precision, recall, and F1‑score—were measured alongside average processing time per token and memory consumption. The dictionary‑only stemmer achieved an F1 of 85.3 % with 12 ms per token and 250 MB memory usage. The rule‑only stemmer reached 78.9 % F1, 8 ms per token, and 180 MB memory. The hybrid system outperformed both, attaining a 92.4 % F1 score, 9 ms average processing time, and 210 MB memory usage, demonstrating that the combined approach yields superior accuracy while remaining computationally lightweight.
Error analysis revealed that the remaining mistakes stem primarily from (1) missing entries in the dictionary (≈3 % of errors) and (2) ambiguous multi‑suffix sequences that the rule engine mis‑ordered (≈2 %). To address these issues, the authors propose an automatic dictionary expansion pipeline that continuously harvests new lexical items from incoming corpora, and a dynamic rule‑learning component that adjusts rule weights based on real‑time feedback.
The discussion extends the applicability of the hybrid framework to other suffix‑rich languages such as Arabic and Urdu, suggesting that the modular design—separate dictionary and rule modules with a shared verification interface—facilitates cross‑lingual adaptation.
In conclusion, the hybrid Persian stemmer demonstrates that a judicious combination of lexical resources and deterministic suffix rules can substantially improve stemming quality without incurring prohibitive computational costs. The authors outline future work that includes fully automated dictionary updates, incorporation of neural‑network‑based rule optimization, and deployment in large‑scale search engine pipelines to validate real‑world impact.