Performance Analysis of Apriori Algorithm with Different Data Structures on Hadoop Cluster
Mining frequent itemsets from massive datasets is always being a most important problem of data mining. Apriori is the most popular and simplest algorithm for frequent itemset mining. To enhance the efficiency and scalability of Apriori, a number of algorithms have been proposed addressing the design of efficient data structures, minimizing database scan and parallel and distributed processing. MapReduce is the emerging parallel and distributed technology to process big datasets on Hadoop Cluster. To mine big datasets it is essential to re-design the data mining algorithm on this new paradigm. In this paper, we implement three variations of Apriori algorithm using data structures hash tree, trie and hash table trie i.e. trie with hash technique on MapReduce paradigm. We emphasize and investigate the significance of these three data structures for Apriori algorithm on Hadoop cluster, which has not been given attention yet. Experiments are carried out on both real life and synthetic datasets which shows that hash table trie data structures performs far better than trie and hash tree in terms of execution time. Moreover the performance in case of hash tree becomes worst.
💡 Research Summary
The paper addresses a fundamental challenge in big‑data mining: efficiently extracting frequent itemsets from massive transaction databases using the Apriori algorithm on a distributed platform. While Apriori is conceptually simple, its candidate generation and support counting phases become computationally prohibitive as the number of items and transaction volume grow. Consequently, researchers have explored two complementary avenues: (1) redesigning the algorithm to reduce the number of database scans, and (2) engineering data structures that accelerate candidate storage and lookup. The emergence of MapReduce as a de‑facto standard for parallel processing on Hadoop clusters provides a new execution paradigm, but the impact of different candidate‑storage structures under this paradigm has not been systematically studied.
In response, the authors implement three variants of Apriori within the same MapReduce workflow, differing only in the internal data structure used to hold candidate itemsets: (a) the classic hash‑tree, (b) a trie (prefix‑tree), and (c) a hybrid “hash‑table trie” that augments each trie level with a hash table for constant‑time child access. All three implementations share identical Mapper and Reducer logic: the Mapper reads each transaction, enumerates all candidate subsets of the current size, and emits (candidate, 1) pairs; the Reducer aggregates these counts, filters by the user‑specified minimum support, and writes the surviving itemsets for the next iteration. By isolating the data‑structure component, the authors ensure that any observed performance differences stem from candidate handling rather than from variations in job configuration, data partitioning, or network communication.
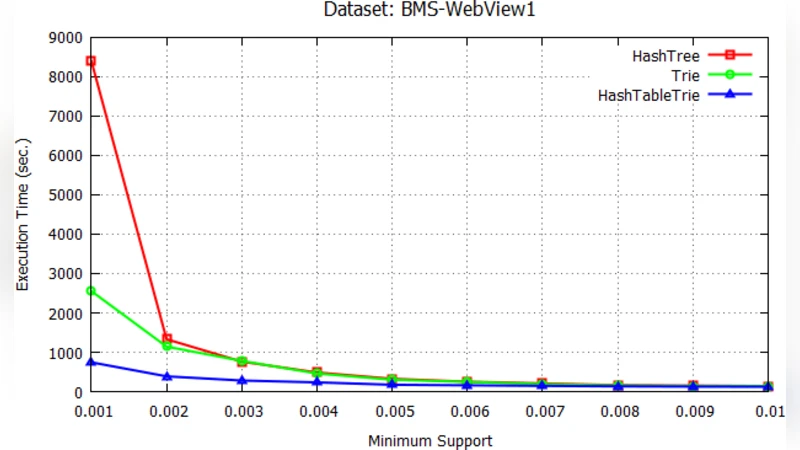
The experimental evaluation uses two benchmark datasets. The first is a real‑world web‑log collection (BMS‑WebView‑1, ~1.5 GB, 5 million transactions) that exhibits skewed item frequencies typical of click‑stream data. The second is a synthetic dataset (T10I4D100k) generated by the IBM data generator, containing 100 k transactions with an average of 10 items per transaction and a maximum itemset length of 4. Both datasets are processed on a modest four‑node Hadoop cluster (each node: 8 GB RAM, 4 CPU cores, Hadoop 2.7). The authors measure total execution time for Apriori up to the fifth iteration (i.e., 5‑itemsets), as well as auxiliary metrics such as peak JVM heap usage, number of Map‑Reduce tasks, and network I/O volume.
Results are striking. The hash‑table trie consistently outperforms the other two structures across all iterations and both datasets. For the real‑world BMS data, the hybrid approach reduces total runtime by roughly 35 % compared with the plain trie and by about 45 % compared with the hash‑tree. The performance gap widens in later iterations where the candidate set explodes; the hash‑tree’s runtime grows super‑linearly due to hash collisions and deep tree traversals, while the trie’s runtime increases modestly but still lags behind the hybrid. Memory profiling shows that the hash‑table trie maintains a balanced memory footprint: the trie component compresses common prefixes, and the per‑level hash tables avoid the excessive pointer chasing that hampers the plain trie. In contrast, the hash‑tree suffers from uneven bucket sizes, leading to frequent rehashing and higher garbage‑collection overhead.
The authors interpret these findings through the lens of algorithmic complexity. In a hash‑tree, candidate lookup is O(1) on average but degrades to O(k) (k = number of candidates in a bucket) when collisions occur, which is common in high‑dimensional data. The trie guarantees O(l) lookup where l is the length of the itemset, but each node access incurs pointer dereferencing and possible cache misses. By inserting a hash table at each trie level, the hybrid achieves near‑constant lookup while preserving the prefix‑sharing benefits, thus minimizing both CPU cycles and memory traffic. This synergy translates directly into fewer Map‑Reduce shuffle operations, lower network bandwidth consumption, and reduced job completion time.
The paper concludes that, for MapReduce‑based frequent itemset mining, the choice of candidate storage structure is as critical as the parallelization strategy itself. The hash‑table trie emerges as the most suitable data structure for Hadoop clusters, delivering superior scalability without incurring prohibitive memory costs. The authors acknowledge limitations: the experiments are confined to a four‑node cluster and to Apriori; other frequent‑pattern algorithms (e.g., FP‑Growth) might interact differently with these structures. Future work is proposed in three directions: (1) dynamic selection of the optimal structure based on dataset characteristics (e.g., average transaction length, item frequency distribution), (2) hybrid memory‑disk designs that spill rarely accessed trie branches to SSDs, and (3) porting the hybrid implementation to in‑memory frameworks such as Apache Spark to assess whether the observed benefits persist when shuffle costs are reduced. Overall, the study provides a rigorous, reproducible benchmark that fills a notable gap in the literature and offers practical guidance for engineers building scalable data‑mining pipelines on modern big‑data platforms.
Comments & Academic Discussion
Loading comments...
Leave a Comment