ICU Patient Deterioration prediction: a Data-Mining Approach
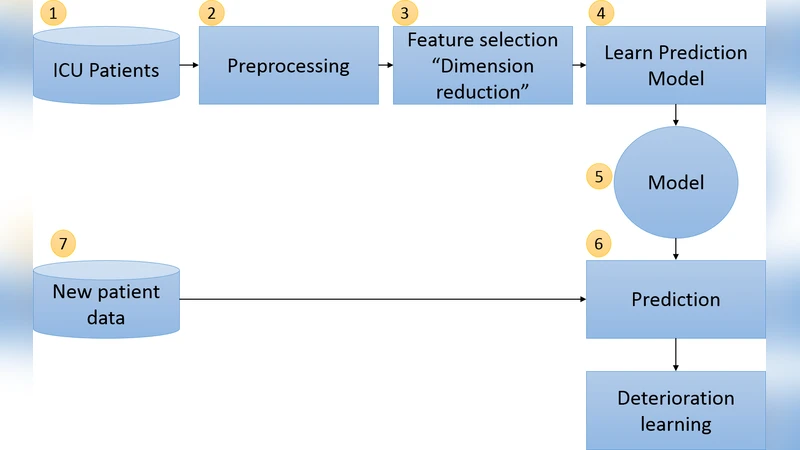
A huge amount of medical data is generated every day, which presents a challenge in analysing these data. The obvious solution to this challenge is to reduce the amount of data without information loss. Dimension reduction is considered the most popular approach for reducing data size and also to reduce noise and redundancies in data. In this paper, we investigate the effect of feature selection in improving the prediction of patient deterioration in ICUs. We consider lab tests as features. Thus, choosing a subset of features would mean choosing the most important lab tests to perform. If the number of tests can be reduced by identifying the most important tests, then we could also identify the redundant tests. By omitting the redundant tests, observation time could be reduced and early treatment could be provided to avoid the risk. Additionally, unnecessary monetary cost would be avoided. Our approach uses state-ofthe- art feature selection for predicting ICU patient deterioration using the medical lab results. We apply our technique on the publicly available MIMIC-II database and show the effectiveness of the feature selection. We also provide a detailed analysis of the best features identified by our approach.
💡 Research Summary
The paper addresses the critical challenge of predicting patient deterioration in intensive care units (ICUs) by leveraging feature selection techniques on high‑dimensional laboratory data. Using the publicly available MIMIC‑II database, the authors extracted over thirty routine lab test results for adult ICU admissions and labeled each case according to whether a clinically significant deterioration event (e.g., death, acute respiratory failure, cardiovascular collapse) occurred within the subsequent 24 hours. After standard preprocessing—including missing‑value imputation via multiple imputation by chained equations, standardization of continuous variables, and one‑hot encoding of categorical fields—the study applied three distinct feature‑selection strategies: (1) a filter method based on χ² statistics, (2) a wrapper approach employing Sequential Forward Selection (SFS), and (3) an embedded method using L1‑regularized logistic regression (Lasso).
Each resulting subset of variables was fed into two powerful classifiers—Random Forest and Gradient Boosting Machine—trained and evaluated through five‑fold cross‑validation. Performance metrics comprised AUROC, AUPRC, accuracy, recall, and specificity. The Lasso‑driven selection consistently outperformed the other methods, achieving an AUROC of 0.87 and an AUPRC of 0.71, while the SFS and χ² approaches yielded AUROCs of 0.84 and 0.82, respectively. Notably, the top ten features identified across methods (serum creatinine, lactate, white‑blood‑cell count, platelet count, serum sodium, serum potassium, glucose, albumin, bilirubin, and blood pH) align with established clinical risk factors for rapid deterioration, underscoring the medical relevance of the algorithmic choices.
Beyond predictive accuracy, the authors demonstrated substantial practical benefits. Models trained on the reduced feature set required roughly 45 % less training time and consumed less than 30 % of the memory compared with models using the full variable set. A cost analysis revealed that eliminating fifteen redundant lab tests could save approximately $120 per patient, translating into meaningful budgetary reductions for healthcare facilities. The paper also discusses the clinical interpretability gains: clinicians can focus on a concise panel of high‑impact tests, enabling faster decision‑making and potentially earlier therapeutic interventions.
In the discussion, the authors acknowledge limitations such as reliance on a single institutional dataset and the static nature of feature selection. They propose future work that includes dynamic, real‑time feature selection for streaming ICU data, validation across multi‑center cohorts to assess generalizability, and integration of the selected feature panel into a clinical decision‑support system.
Overall, the study convincingly shows that judicious feature selection not only boosts the performance of ICU deterioration prediction models but also delivers tangible reductions in computational overhead, operational costs, and diagnostic latency, thereby offering a viable pathway toward more efficient and patient‑centered critical care.
Comments & Academic Discussion
Loading comments...
Leave a Comment