Recurrent Reinforcement Learning: A Hybrid Approach
Successful applications of reinforcement learning in real-world problems often require dealing with partially observable states. It is in general very challenging to construct and infer hidden states as they often depend on the agent’s entire interaction history and may require substantial domain knowledge. In this work, we investigate a deep-learning approach to learning the representation of states in partially observable tasks, with minimal prior knowledge of the domain. In particular, we propose a new family of hybrid models that combines the strength of both supervised learning (SL) and reinforcement learning (RL), trained in a joint fashion: The SL component can be a recurrent neural networks (RNN) or its long short-term memory (LSTM) version, which is equipped with the desired property of being able to capture long-term dependency on history, thus providing an effective way of learning the representation of hidden states. The RL component is a deep Q-network (DQN) that learns to optimize the control for maximizing long-term rewards. Extensive experiments in a direct mailing campaign problem demonstrate the effectiveness and advantages of the proposed approach, which performs the best among a set of previous state-of-the-art methods.
💡 Research Summary
The paper addresses the challenge of applying reinforcement learning (RL) to real‑world problems where the agent’s state is only partially observable, using customer relationship management (CRM) as a concrete example. Traditional solutions based on partially observable Markov decision processes (POMDPs) require explicit definition of hidden states and observation models, which often demand substantial domain expertise and are impractical for complex domains. To overcome this limitation, the authors propose a hybrid architecture that jointly leverages supervised learning (SL) and RL.
The SL component is a recurrent neural network (RNN) or its long short‑term memory (LSTM) variant. It is trained to predict the next observation and the immediate reward given the current observation, action, and reward history. By minimizing a supervised loss (e.g., mean‑squared error), the recurrent network learns a compact hidden representation ĥₜ that aggregates the entire interaction history up to time t. This hidden state is intended to capture the underlying (unobserved) user state without manual feature engineering.
The RL component is a Deep Q‑Network (DQN). Instead of feeding raw observations, the DQN receives the hidden representation ĥₜ as its input and outputs Q‑values for all possible actions. The DQN is trained with the standard Q‑learning temporal‑difference (TD) error:
δₜ = rₜ + γ maxₐ′ Q(ĥₜ₊₁, a′; θ) – Q(ĥₜ, aₜ; θ).
Crucially, the TD error is back‑propagated not only through the DQN parameters θ but also through the recurrent network that generated ĥₜ. Consequently, the hidden representation is shaped simultaneously by the supervised prediction objective and the RL objective of maximizing long‑term cumulative reward. Training proceeds in an interleaved fashion: each stochastic gradient descent (SGD) iteration first updates the RNN/LSTM on the supervised loss, then updates the DQN on the TD loss, using the freshly computed hidden states. This joint optimization ensures that the learned representation is useful for the downstream policy.
The authors evaluate the approach on the 1998 KDD Cup direct‑mailing dataset, a benchmark widely used in CRM‑related RL research. The data consist of 95,412 donors observed over 23 monthly periods, yielding more than two million transition tuples. Each observation is a five‑dimensional vector (recency, frequency, monetary value, recent mail count, total mail count). The action space contains 12 discrete actions (11 mail types plus a “no‑mail” option). Immediate reward is the donation amount (0–1000 USD).
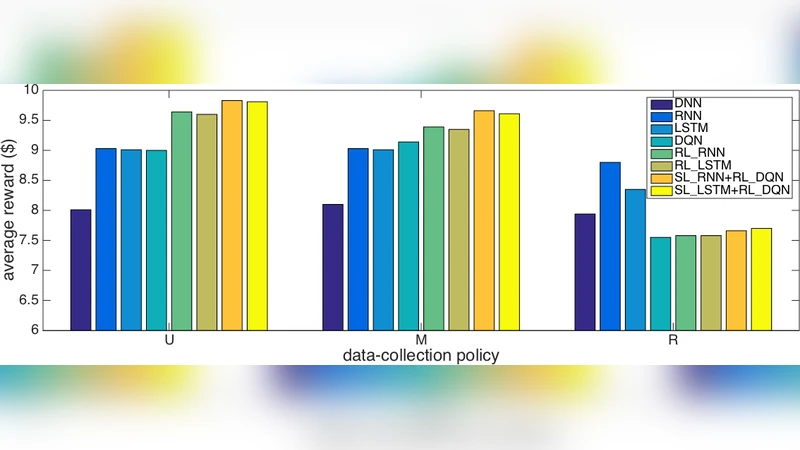
A major contribution of the paper is its critique of the evaluation protocol used in prior work (Tkachenko 2015), which partitions test data into “SAME” (model’s action matches the logged action) and “DEVIATED” sets and compares average rewards only on the SAME set. The authors argue that this method is biased toward policies that merely mimic the data‑collection policy and can be gamed by cherry‑picking high‑value customers. Instead, they construct a factored simulator from the dataset: given an action and reward, each component of the observation vector evolves independently according to learned conditional distributions. This simulator enables offline policy evaluation by generating synthetic interaction sequences for any candidate policy.
Four baselines are compared: (1) linear batch Q‑learning (Pednault 2002, Silver 2013), (2) a vanilla DQN that consumes raw observations, (3) RL‑RNN and RL‑LSTM where the recurrent network directly parameterizes the Q‑function, and (4) the proposed hybrid models SL‑RNN + RL‑DQN and SL‑LSTM + RL‑DQN. Results show that the hybrid models achieve the highest cumulative donation (reward) and lifetime value (LTV) across multiple simulation runs. The performance gap is especially pronounced when the underlying dynamics are highly non‑Markovian, confirming that the supervised prediction of next observations helps the recurrent network learn a more informative hidden state. Moreover, the hybrid approach exhibits greater training stability: the recurrent network regularizes the hidden representation, while the DQN’s target‑network mechanism prevents the Q‑values from diverging.
In summary, the paper makes three key contributions:
-
Methodological Innovation – a joint SL/RL training scheme that uses supervised prediction to learn hidden states and RL to optimize long‑term reward, bridging the gap between representation learning and policy learning in partially observable settings.
-
Empirical Validation – extensive experiments on a realistic CRM dataset demonstrate that the hybrid models outperform both linear and deep baselines, confirming the advantage of decoupling state inference (supervised) from control (RL) while still training them jointly.
-
Evaluation Rigor – a critique of flawed offline evaluation practices and the introduction of a simulator‑based protocol that more faithfully measures long‑term performance of policies in the absence of a true environment.
Future directions suggested include extending the framework to continuous action spaces, exploring transformer‑based sequence models for richer state representations, and developing online learning mechanisms that can update the policy and the state encoder in real time while balancing exploration and exploitation. The proposed hybrid architecture thus opens a promising pathway for applying deep RL to a wide range of real‑world problems where hidden states are abundant and domain knowledge is scarce.
Comments & Academic Discussion
Loading comments...
Leave a Comment