Dimension of Marginals of Kronecker Product Models
A Kronecker product model is the set of visible marginal probability distributions of an exponential family whose sufficient statistics matrix factorizes as a Kronecker product of two matrices, one for the visible variables and one for the hidden var…
Authors: Guido Montufar, Jason Morton
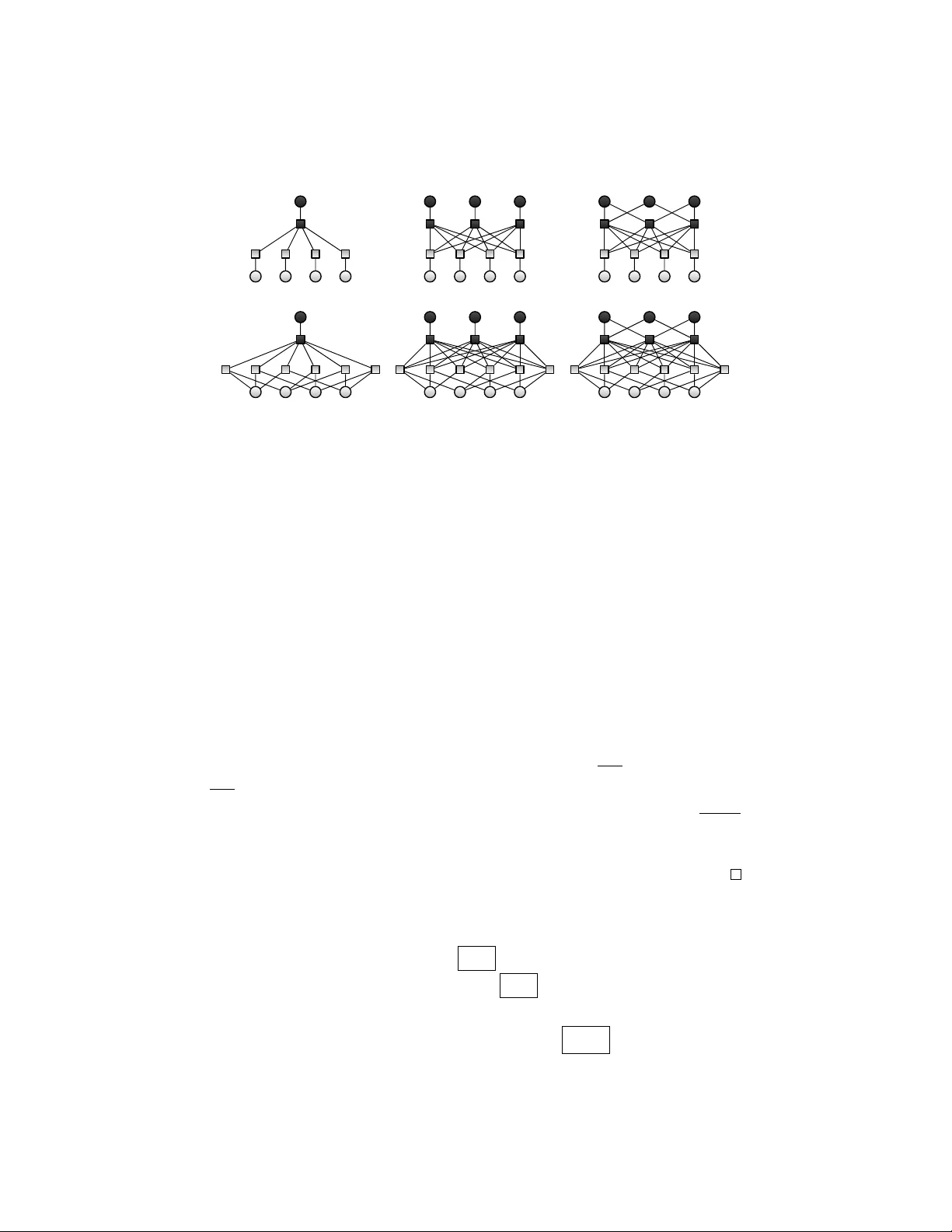
Dimension of Marginals of Kr onecker Pr oduct Models Geometry of hidden-visible products of exponential families Guido Mont ´ ufar ∗ 1 and Jason Morton † 2 1 Max Planck Institute for Mathematics in the Sciences, Inselstraße 22, 04103 Leipzig, German y 2 Department of Mathematics, Pennsylvania State Uni versity , P A 16802, Uni versity Park, USA Nov ember 12, 2015 Abstract A Kronecker product model is the set of visible marginal probability distrib utions of an exponential family whose suf ficient statistics matrix factorizes as a Kro- necker product of two matrices, one for the visible variables and one for the hid- den variables. W e estimate the dimension of these models by the maximum rank of the Jacobian in the limit of lar ge parameters. The limit is described by the trop- ical morphism; a piecewise linear map with pieces corresponding to slicings of the visible matrix by the normal fan of the hidden matrix. W e obtain combina- torial conditions under which the model has the expected dimension, equal to the minimum of the number of natural parameters and the dimension of the ambient probability simplex. Additionally , we prove that the binary restricted Boltzmann machine always has the e xpected dimension. K eywor ds : expected dimension, tropical geometry , secant v ariety , restricted Boltz- mann machine, inference function, Kronecker product, Hadamard product, Khatri- Rao product, exponential family harmonium MSC2010 : 14T05, 52B05 1 Intr oduction Simple probability distributions are often composed in order to obtain more interesting or complex probability distributions. Natural compositions include tensor products, con ve x combinations, and renormalized entrywise products. Stochastic neural net- works, for example, define compositions of elementary probability distrib utions on the states of individual neurons, which result in interesting joint probability distributions on the states of subsets of neurons of the entire network. W e study probability mod- els defined by building the Kronecker product of the sufficient statistics matrices of ∗ montufar@mis.mpg.de † morton@math.psu.edu 1 two exponential families and marginalizing ov er one of the two. W e call these prob- ability models hidden-visible Kronecker products of exponential families, or simply Kronecker product models. Examples include mixtures of e xponential families, re- stricted Boltzmann machines [ 10 ], and, more generally , hierarchical models on Carte- sian products of simplicial complexes of hidden and visible variables. A related class of probability models is kno wn in machine learning under the name exponential f amily harmonium [ 27 ]. W e are interested in the dimension of these compositions, depending on the proper- ties of the visible and hidden factors. Marginalization is in general a non-injecti ve map which may collapse the dimension of the probability model that is being mar ginalized. W ell known examples of this behavior are mixture models, which may have a dimen- sion that is strictly smaller than the dimension of the corresponding non-marginalized models and the ambient probability simplex. Many interesting mixture models corre- spond to secant varieties and as such their dimension has been subject of numerous works in algebraic geometry . Examples include the secants of Segre products [ 2 , 5 , 21 ] and V eronese varieties [ 1 , 21 ]. Reference texts are [ 28 , 16 ]. Computing the dimension of secant v arieties is a notoriously difficult problem, even in cases where the basis va- riety is of striking simplicity , such as the Se gre products of one-dimensional projectiv e spaces (corresponding to binary independence models in statistics or to the decom- posable 2 × · · · × 2 tensors in signal processing). In turn, computing the dimension of marginals of general exponential families seems near to hopeless. In certain cases, howe ver , the dimension of secant varieties can be estimated by solving linear programs. The main idea has been illuminated in the tropical approach to secant dimensions by Draisma [ 8 ]. Depending on the basis v ariety , the dimension estimates resulting from this approach giv e in fact the exact dimension. For Segre varieties, a sufficient condi- tion is the existence of error correcting codes of a certain cardinality . F ollowing these ideas, the dimension of binary and discrete restricted Boltzmann machines (Hadamard products of secant varieties of Segre products) hav e been studied in [ 6 ] and [ 19 ], re- spectiv ely . The goal of the present paper is to elucidate the approach from the per- spectiv e of exponential families, especially hierarchical models, and to pro vide explicit results for Kronecker product models (Definition 7 ) generalizing some of the abo ve mentioned work on secants and restricted Boltzmann machine dimensions. Consider two finite integers N , M ∈ N and a probability model { p θ : θ ∈ R M } ⊆ ∆ N − 1 , parametrized by a function φ : R M → ∆ N − 1 ; θ 7→ p θ from M -dimensional Euclidean space R M to the ( N − 1) -dimensional probability simplex ∆ N − 1 := { p ∈ R N : p ( x ) ≥ 0 for all x and P N x =1 p ( x ) = 1 } . The dimension of φ ( R M ) is gi ven by the maximum rank of the Jacobian J φ of the map φ over the points of R M where φ is smooth. Hence the problem reduces to computing the maximum of the rank function ov er a parametric set of matrices. In general, computing the rank of these matrices is difficult. A possible approach is to maximize the rank only ov er a subset of parameters where the Jacobian is simpler . When the result matches the maximum possible value, equal to the dimension M of the parameter domain R M or to the dimension N − 1 of the codomain ∆ N − 1 , we can be sure that we hav e attained the global maximum. The rank becomes tractable when there is an obvious way to transform the Jaco- bian into a suitable block matrix by elementary matrix operations. Consider the case 2 where φ parametrizes an exponential family , i.e., φ ( θ ) = exp( h θ, F i − ψ ( θ )) for some matrix F ∈ R M × N of sufficient statistics, where ψ is the normalizing (log-partition) function. Note that φ ( αθ ) ∝ φ α ( θ ) for each α ∈ R . Hence, in the limit of large pa- rameters ( α → ∞ ), the resulting probability vector is proportional to the indicator of argmax h θ , F i . The optimizing set is piecewise constant on θ and usually has a small cardinality . Accordingly , if φ parametrizes marginals of an e xponential family , then, in the limit of large α , the matrix J φ ( αθ ) has a block structure and its rank may be easy to determine. The mathematical formalism describing this limit of large parameters is known as tropical geometry . The tropicalization of φ produces a piecewise linear version of φ that captures its combinatoric properties. In this approach, the dimension of the models under consideration can be related to polyhedral optimization problems. This leads to combinatorial problems about optimal slicings of point configurations by polyhedral fans of point configurations. Characterizing the sets of maximizers of vectors in the row span of F and the combinatorics of the conv ex support of the ex- ponential family (the conv ex hull of the columns of F ) is not an easy task in general. Howe ver , we do not need to fully solve that problem in order to estimate the maximum rank. As mentioned above, we will place emphasis on Kronecker product models with factors giv en by hierarchical models. Hierarchical models are ubiquitous in statistics applications [ 26 ]. An algebraic perspective on hierarchical graphical models was giv en in [ 11 ]. Some works have discussed the conv ex support polytopes of hierarchical mod- els, showing relations to linear codes and oriented matroids [ 14 , 22 ] and describing properties such as neighborliness and simpliciality [ 13 , 18 ]. This paper is organized as follows. Section 2 provides basic definitions of marginals of discrete exponential families and discusses the Jacobian of their natural parametriza- tion. It also introduces the associated inference functions and tropical models. Sec- tion 3 defines the Kronecker product model and discusses its general properties. The sections that follow are de voted to specific types of Kronecker product models. Sec- tion 4 gives a brief introduction to hierarchical models and defines related types of error correcting codes. Section 5 studies the tropical dimension of mixtures of hierarchical models. Section 6 studies the tropical dimension of Hadamard products of mixtures of hierarchical models. Section 7 studies the general case of Kronecker product hierar- chical models. Theorem 24 from Section 7 includes the Theorems 16 and Theorem 22 from Sections 5 and 6 as special cases. Section 8 proves that binary restricted Boltz- mann machines alw ays ha ve the expected dimension, thereby solving the dimension question for cases that were left open in [ 6 ]. Section 9 discusses the results. 2 Marginals of Exponential F amilies In this section we present basic definitions of exponential families and their mar ginals. W e discuss the Jacobian of the natural parametrization and relate its behavior in the limit of large parameters with the inference functions of the model. This leads us to the definition of the tropical morphism and a simplified rank estimation problem. Consider two finite sets X and Y . A probability distribution on X × Y is a real- valued v ector p ∈ R X ×Y with entries p ( x, y ) ≥ 0 , ( x, y ) ∈ X × Y , satisfying 3 P x,y p ( x, y ) = 1 . Consider a function F : X × Y → R d . Definition 1. The exponential family E F with sufficient statistics F consists of all probability distributions on X × Y of the form p θ ( x, y ) = 1 Z ( θ ) exp( h θ , F ( x, y ) i ) , ( x, y ) ∈ X × Y , θ ∈ R d , where h· , ·i denotes the standard inner product and Z : θ 7→ P x 0 ,y 0 exp( h θ , F ( x 0 , y 0 ) i ) is a normalization function. Note that each distribution in the exponential family has strictly positive entries. W e will regard F as a matrix with columns F ( x, y ) ∈ R d , ( x, y ) ∈ X × Y . W e note that the exponential family E F is fully characterized by the row space h R d , F i ⊆ R X ×Y of the sufficient statistics matrix F . More precisely , two matrices F and G produce the same exponential family if and only if ( F ; 1 ) and ( G ; 1 ) hav e the same ro w span, where 1 is a row of ones. From no w on we will always assume, without loss of generality , that F includes 1 in its row span. The dimension of the exponential family is then dim( E F ) = rank( F ) − 1 . This is the same as the dimension of the con ve x support polytope conv { F ( x, y ) : ( x, y ) ∈ X × Y } . Definition 2. The marginal model M F on X of the exponential family E F is the set of all probability distributions of the form p θ ( x ) = X y ∈Y 1 Z ( θ ) exp( h θ , F ( x, y ) i ) , x ∈ X , θ ∈ R d . The marginal model M F is the image of E F by the marginalization map, which is the linear map represented by the matrix with rows equal to the indicators 1 x ∈ R X ×Y of { x } × Y , for each x ∈ X . W e are interested in the dimension of M F . When dim( M F ) = min { dim( E F ) , |X | − 1 } , we say that M F has the expected dimen- sion, meaning that marginalization do e s not collapse the dimension of E F , or that the marginal M F is full dimensional, having the same dimension as the simplex ∆ |X |− 1 of all probability distributions on X . The dimension of M F is equal to the maximum rank of the Jacobian matrix of the parametrization θ 7→ ( p θ ( x )) x . The Jacobian is given by J M F ( θ ) = X y p θ ( x, y ) F ( x, y ) − X y p θ ( x, y ) X x 0 ,y 0 p θ ( x 0 , y 0 ) F ( x 0 , y 0 ) x . (1) The second term corresponds to the normalization function Z . For the rank we hav e rank ( J M F ( θ )) = rank X y p θ ( x, y ) F ( x, y ) ! x − 1 = rank X y p θ ( y | x ) F ( x, y ) ! x − 1 . (2) 4 The first equality follows from the assumption that F has a constant row . The second one is because p θ ( x ) = P y 0 p θ ( x, y 0 ) > 0 for all x . Here p θ ( y | x ) := p θ ( x, y ) / P y 0 p θ ( x, y 0 ) denotes the conditional probability of y given x . A geometric interpretation is that rank( J M F ( θ )) is the dimension of the polytope defined as the con ve x hull of X y p θ ( y | x ) F ( x, y ) , x ∈ X . Evaluating Equation 2 is dif ficult, in general. The problem is easier in the limit of large parameters, where the sum ov er y almost alw ays reduces to a single term. T o see that this is the case, note that multiplicativ e f actors of the parameter θ cor- respond to exponential factors of the probability distribution, such that p αθ ( ·| x ) ∝ p θ ( ·| x ) α . Therefore, for any θ ∈ R d , the limit lim α →∞ p αθ ( y | x ) is non-zero only for y ∈ argmax y p θ ( y | x ) = argmax y h θ , F ( x, y ) i . Following this line of thought, it is con venient to define the function that outputs the most likely v alue of y to any gi ven x : Definition 3. The inference function of M F with parameter θ ∈ R d is giv en by h θ : X → 2 Y ; x 7→ h θ ( x ) = argmax y h θ , F ( x, y ) i . Here 2 Y denotes the power set of Y . Geometrically , h θ ( x ) is the set of y ∈ Y for which F ( x, y ) lies in the supporting hyperplane of F ( x, y ) , y ∈ Y , with normal θ . The situation is illustrated in Figure 1 . W e hav e the following dimension bounds: Proposition 4. The dimension of the mar ginal model M F satisfies rank( F ) − 1 = dim( E F ) ≥ dim( M F ) ≥ max θ rank ¯ F ( x, h θ ( x )) x − 1 , wher e ¯ F ( x, h θ ( x )) := 1 | h θ ( x ) | P y ∈ h θ ( x ) F ( x, y ) . Pr oof. W e have max θ ∈ R d rank ( J M F ( θ )) = max θ ∈ R d rank X y p θ ( y | x ) F ( x, y ) ! x − 1 ≥ max θ ∈ R d rank lim α →∞ X y p αθ ( y | x ) F ( x, y ) ! x − 1 = max θ ∈ R d rank X y ∈ h θ ( x ) 1 | h θ ( x ) | F ( x, y ) x − 1 . The first line is Equation 2 . The second line follows from the continuity of the parametriza- tion of the exponential family (see Definition 2 ) and the lower semicontinuity of the rank function. The third line is because lim α →∞ p αθ ( y | x ) is positiv e and constant on h θ ( x ) = argmax y p θ ( y | x ) and zero on Y \ h θ ( x ) . 5 0 1 , 4 2 3 5 x = 0 0 1 2 3 5 4 θ x = 1 Figure 1: Illustration of an inference function for a model with X = { 0 , 1 } , Y = { 0 , . . . , 5 } . Each dot is a vector F ( x, y ) . Small dots correspond to x = 0 and large ones to x = 1 . The value of y is indicated next to each dot. F or the illustrated choice of θ the inference function is h θ ( x = 0) = { 2 } , h θ ( x = 1) = { 1 , 2 , 3 } and the tropical morphism is gi ven by A θ = ( F (0 , 2) , 1 3 ( F (1 , 1) + F (1 , 2) + F (1 , 3))) . For generic choices of θ the vector F ( x, h θ ( x )) is a vertex of the polytope con v { F ( x, y ) : y ∈ Y } , for all x . Proposition 4 shows that we can estimate the dimension of the marginal model by studying the maximum rank ov er θ of the piecewise constant matrix-v alued function A θ := ( ¯ F ( x, h θ ( x ))) x . For each x ∈ X , the column ¯ F ( x, h θ ( x )) is the average of the maximizers of the linear form h θ , ·i over F ( x, y ) , y ∈ Y . For generic choices of θ ∈ R d , the set of maximizers F ( x, y ) , y ∈ h θ ( x ) , consists of one single element, for each x . In particular, when all vectors F ( x, y ) are different, for generic choices of θ , the inference function h θ maps each x to a single y . The vectors ¯ F ( x, h θ ( x )) , x ∈ X , do not necessarily lie on the same supporting hyperplane of F ( x, y ) , ( x, y ) ∈ X × Y , although the conv erse is true in the following sense. If there is supporting hyperplane that intersects F ( x, y ) , ( x, y ) ∈ X × Y , e xactly at F ( x, f ( x )) , x ∈ X , for some f : X → Y , then f is an inference function. Howe ver , since these v ectors lie on a supporting hyperplane (which usually defines a proper face of the con ve x support polytope), they are not suited for estimating the maximum rank. The matrix A θ defines a geometric object called the tropical version of the original marginal model: Definition 5. The tropical v ersion of M F , denoted M tropical F , is the set of all vectors in 6 R X / R 1 (modulo addition of constant vectors) of the form Φ θ ( x ) = h θ , ¯ F ( x, h θ ( x ) i , x ∈ X , parametrized by θ ∈ R d . Proposition 4 can be regarded as a version of the Bieri-Groves theorem [ 3 , 8 ], stating that the dimension of the mar ginal model is bounded below by the dimension of its tropical version: dim( M F ) ≥ dim( M tropical F ) . In particular , when M tropical F has the expected dimension, then M F also has the ex- pected dimension. This is the central idea of [ 8 ] and subsequently [ 6 , 19 ] for estimating the dimension of secant varieties and restricted Boltzmann machines. W e note that the marginal model and its tropical version are independent of the sufficient statistics matrix used to parametrize the underlying e xponential family: Proposition 6. If E = Q > F is a non-singular linear transformation of F , then E E = E F , M E = M F , and M tropical E = M tropical F . Mor e generally , if G = R > F is a linear transformation of F , then E G ⊆ E F , M G ⊆ M F , and M tropical G ⊆ M tropical F . Pr oof. The equality of the exponential families follows from the equality of the ro w spaces of F and E . For the tropical models note that for each θ there is a ϑ = Q − 1 θ with h θ , F ( x, h θ ( x )) i = h ϑ, E ( x, h ϑ ( x )) i . For the inclusions note that the row space of G = R > F is a linear subspace of the ro w space of F . 3 The Kr onecker Pr oduct Model Kronecker product models are marginals of exponential families whose sufficient statis- tics matrix factorizes as the Kronecker product of a sufficient statistics matrix over the visible states and one over the hidden states. Recall the definition of the Kronecker product ( A i,j ) i,j ⊗ ( B k,l ) k,l := ( A i,j B k,l ) ( i,k ) , ( j,l ) . Definition 7. A Kr oneck er pr oduct model is a marginal model M F , where F factorizes as F ( x, y ) = A ( x ) ⊗ B ( y ) , x ∈ X , y ∈ Y , for some A ∈ R a ×X and B ∈ R b ×Y . W e will use the notations A = ( A x ) x ∈ R a ×X , B = ( B y ) y ∈ R b ×Y , and assume that the row space of each matrix contains a constant non-zero vector . For simplicity in the following we assume that all columns of B are different. The general case with repeated columns is very similar , but needs more complicated notations. Consider a generic choice of the parameter θ , such that the inference function h θ maps each x ∈ X to a single y ∈ Y . The tropical morphism Φ θ ( x ) = h θ, A θ i of a Kronecker product model has the form A θ = ( F ( x, h θ ( x ))) x = ( A x ⊗ B h θ ( x ) ) x = A B h θ , (3) where ( A i,j ) i,j ( B k,l ) k,l := ( A i,j B k,j ) ( i,k ) ,j denotes the column-wise Kronecker product or Khatri-Rao product [ 15 ]. Alternatively , after rearranging columns, we can write this as A θ = ( B y ⊗ A h − 1 θ ( y ) ) y = B A h − 1 θ , 7 where now denotes the column-block-wise Kronecker product. Here the column- blocks, index ed by y , are B y and A h − 1 θ ( y ) . When h − 1 θ ( y ) = ∅ , we simply omit the block B y ⊗ A h − 1 θ ( y ) . Unfortunately there is no formula for expressing the rank of a Khatri-Rao product in terms of the ranks of its factors. A simple lower bound for matrices consisting of non- zero columns is rank( A B h ) ≥ max { rank( A ) , rank( B h ) } . More elaborate lower bounds can be given in terms of Kruskal ranks [ 24 ], also for column-block partitioned matrices [ 17 ]. Our analysis seeks to characterize pairs of matrices A and B for which the upper bound rank( A B h ) ≤ rank( A ⊗ B h ) = rank( A ) · rank( B h ) is attained for some inference function h . F or this it is critical to study the possible inference functions. The factorization property F = A ⊗ B leads to highly structured inference func- tions. W e e xplain this in the following. For a giv en parameter vector θ = ( θ ( i,j ) ) ( i,j ) ∈ R ab let Θ = ( θ ( i,j ) ) j,i ∈ R b × a denote the matrix with column-by-column vectorization equal to θ . By Roth’ s lemma [ 23 ] we have the follo wing equalities: h θ , ( A ⊗ B ) ( x,y ) i = h Θ A x , B y i = h Θ > B y , A x i for all x ∈ X , y ∈ Y . In turn, the same inner product describes the following distributions o ver ( x, y ) , y , and x : p θ ( · , · ) = 1 Z ( θ ) exp( h θ , A ⊗ B i ) ∈ E A ⊗ B , p θ ( ·| x ) = 1 Z (Θ A x ) exp( h Θ A x , B i ) ∈ E B , (4) p θ ( ·| y ) = 1 Z (Θ > B y ) exp( h Θ > B y , A i ) ∈ E A . In particular , p θ ( ·| x ) appears in the Equation 2 of the Jacobian rank. Geometrically , Θ A is the linear projection of the columns of A by the matrix Θ to the parameter space of the hidden exponential family E B . Similarly , Θ > B is the projection of the columns of B by the matrix Θ > to the parameter space of the visible exponential family E A . The inference function of a Kronecker model satisfies h θ ( x ) = argmax y p θ ( y | x ) = argmax y h θ , A x ⊗ B y i = argmax y h Θ A x , B y i = { y ∈ Y : Θ A x ∈ N B ( y ) } = argmax y h A x , Θ > B y i = { y ∈ Y : A x ∈ N Θ > B ( y ) } . Here the normal cones of B at B y and of Θ > B at Θ > B y are defined, respectiv ely , as N B ( y ) := { r ∈ R b : h r, B y − B y 0 i ≥ 0 for all y 0 ∈ Y \ { y }} , N Θ > B ( y ) := { r ∈ R a : h r, Θ > B y − Θ > B y 0 i ≥ 0 for all y 0 ∈ Y \ { y }} . In turn, the inference function h θ can be interpreted as a slicing of Θ A by the normal fan of B , or , equi valently , a slicing of A by the normal fan of Θ > B : 8 Definition 8. A B -slicing of A is a partition of the column set of A into the blocks A C y := ( A x ) x ∈ C y with C y := h − 1 θ ( y ) = { x ∈ X : h θ ( x ) = y } , for all y ∈ Y . Here we assume that h θ maps each x to a single y , which is the generic case when all columns of B are different. Note that some of the sets C y = h − 1 θ ( y ) may be empty . Related to the statements of Proposition 6 we hav e the follo wing observations: If B 0 = D B for some matrix D , then any B 0 -slicing is also a B -slicing. Furthermore, if B 0 is a matrix consisting of all columns of B that lie in a common supporting hyper - plane of B , then any B 0 -slicing is a B -slicing. Note also that, by the mixed-product property of the Kronecker product, ( C ⊗ D )( A ⊗ B ) = ( C A ) ⊗ ( D B ) , the Kronecker product of two linearly transformed matrices C A and D B is gi ven by a linear transfor- mation of the Kronecker product of the two original matrices. 4 Hierar chical Models W e are interested in Kronecker product models for which the factor exponential fam- ilies E A and E B are hierarchical models. In this section we provide the necessary definitions. Consider n random v ariables with finite state sets X i = { 0 , 1 . . . , |X i | − 1 } , i ∈ [ n ] := { 1 , . . . , n } . W e write x = ( x 1 , . . . , x n ) for an element of X = X 1 × · · · × X n . Giv en some x ∈ X and λ ⊆ [ n ] , we write x λ = ( x i ) i ∈ λ for the natural projection of x to the λ -coordinates. Unless otherwise stated, in all that follows Λ will denote an inclusion closed set of subsets of [ n ] , such that λ ∈ Λ and λ 0 ⊆ λ imply λ 0 ∈ Λ . Consider the linear subspace of R X consisting of all linear combinations of real-v alued functions that depend only on x λ , λ ∈ Λ , V Λ ( X ) := n X λ ∈ Λ f λ : f λ ( x ) = f λ ( x λ ) o ⊆ R X . Definition 9. The hierarchical model on X with interactions Λ is the e xponential fam- ily E A , where A ∈ R a ×X is a matrix with ro w span V Λ ( X ) . W e will denote this model by E Λ . An important special case is the k -interaction model E Λ k , defined by some 1 ≤ k ≤ n and Λ k = { λ ⊆ [ n ] : | λ | ≤ k } . An important example is the independence model E Λ 1 , which is the k -interaction model with k = 1 . The independence model consists of probability distributions that factorize as p ( x 1 , . . . , x n ) = p 1 ( x 1 ) ⊗ · · · ⊗ p n ( x n ) , where, for each i ∈ [ n ] , p i is a probability distribution over x i . This model corresponds to the Segre embedding of P |X 1 |− 1 × · · · × P |X n |− 1 into P Q i ∈ [ n ] |X i |− 1 . The suf ficient statistics matrix of a hierarchical model can be constructed in the following simple way . The first row , with inde x ∅ , is the constant v ector of ones A ∅ ,x := 1 , x ∈ X . The other rows are index ed by pairs ( λ, ˜ x λ ) , with λ ∈ Λ and ˜ x λ ∈ ˜ X λ := × i ∈ λ ( X i \ { 0 } ) . The (( λ, ˜ x λ ) , x ) -th entry of the matrix is A ( λ, ˜ x λ ) ,x := ( 1 , if x λ = ˜ x λ 0 , otherwise . (5) 9 Proposition 10. The matrix A fr om Equation 5 has r ow space V Λ ( X ) . Furthermore, dim( E Λ ) = rank( A ) − 1 = dim( V Λ ( X )) − 1 = P λ ∈ Λ \∅ Q i ∈ λ ( |X i | − 1) . The statement of Proposition 10 is well known in the context of hierarchical mod- els. One way of proving it is as follo ws: Pr oof. Let λ ∈ Λ and let f λ ∈ R X be a function with f λ ( x ) = f λ ( x λ ) for all x ∈ X . Note that f λ can be written as a linear combination of indicator functions of cylinder sets as f λ ( x ) = P x ∗ λ ∈X λ f λ ( x ∗ λ ) 1 { x 0 ∈X : x 0 λ = x ∗ λ } ( x ) for all x ∈ X . Hence we only need to show that the row span of A contains the indicator functions 1 { x 0 ∈X : x 0 λ = x ∗ λ } for all x ∗ λ ∈ X λ . For any x ∗ λ and λ ∗ = supp( x ∗ ) ∩ λ we have that 1 { x 0 ∈X : x 0 λ = x ∗ λ } ( x ) = X λ ∗ ⊆ λ 0 ⊆ λ ( − 1) | λ 0 \ λ ∗ | X ˜ x λ 0 ∈ ˜ X λ 0 : ˜ x λ ∗ = x ∗ λ ∗ A ( λ 0 , ˜ x λ 0 ) ,x , for all x ∈ X . Hence the ro w span of A contains the indicator function 1 { x 0 ∈X : x 0 λ = x ∗ λ } . Since x ∗ λ was arbitrary , this shows that the ro w span contains f λ . Since λ was arbitrary in Λ , this shows that the row span contains V Λ ( X ) . The rev erse inclusion is direct. The matrix A has 1 + P λ ∈ Λ \∅ Q i ∈ λ ( |X i | − 1) linearly independent rows, including a row of ones. This implies the dimension statement. W e now introduce the concept of Λ -balls, which we will use for constructing slic- ings of hierarchical models and formulating our theorems later on. Definition 11. Let X = X 1 × · · · × X n . The Λ -ball in X centered at x ∈ X is the set of vectors that dif fer from x exactly at the entries from some λ ∈ Λ , K X ( x, Λ) := { x 0 ∈ X : { i ∈ [ n ] : x 0 i 6 = x i } = λ ∈ Λ } . Note that all Λ -balls in X ha ve the same cardinality , regardless of their center , K X (Λ) := | K X ( x, Λ) | = 1 + X λ ∈ Λ \∅ Y i ∈ λ ( |X i | − 1) . W e will drop the subscript X when it is clear from the conte xt. An important special case of Λ -balls are Hamming balls. Recall that the Hamming distance between two vectors x, x 0 ∈ X is defined as d H ( x, x 0 ) := |{ i ∈ [ n ] : x i 6 = x 0 i }| . The radius- k Hamming ball in X centered at x is the set of vectors that differ from x at most in k entries, K ( x, Λ k ) = { x 0 ∈ X : d H ( x, x 0 ) ≤ k } . In later sections we will consider slicings of a matrix A with row span V Λ ( X ) into blocks corresponding to Λ -balls. W e will use the following lemma: Lemma 12. Let X = X 1 × · · · × X n , let A be a matrix with r ow span V Λ ( X ) , let x ∈ X , and let K ( x, Λ) be the Λ -ball in X centered at x . Then A K ( x, Λ) has full rank, rank( A K ( x, Λ) ) = dim( V Λ ( X )) = 1 + X λ ∈ Λ \∅ Y i ∈ λ ( |X i | − 1) = K (Λ) . 10 Pr oof. Consider the matrix entries A ( λ, ˜ x λ ) ,x defined in Equation 5 . For any λ 6∈ Λ and ˜ x λ ∈ ˜ X λ = × i ∈ λ X i \ { 0 } , we hav e that A ( λ, ˜ x λ ) ,x = 0 for all x ∈ K (0 , Λ) . On the other hand, by Proposition 14 the full matrix ( A ( λ, ˜ x λ ) ,x ) ( λ ∈ 2 [ n ] , ˜ x λ ∈ ˜ X λ ) ,x ∈X has rank equal to dim( V 2 [ n ] ( X )) = |X | and thus it has ro w span R X . This implies that the matrix ( A ( λ, ˜ x λ ) ,x ) ( λ ∈ Λ , ˜ x λ ∈ ˜ X λ ) ,x ∈ K (0 , Λ) has row span R K (0 , Λ) . This proves the claim for the case of a Λ -ball centered at the zero vector . The other cases follow from this after relabeling the states. Lemma 12 states that certain collections of columns of the sufficient statistics ma- trix of a hierarchical model are linearly independent. This property is related to the notion of Kruskal rank, defined as the largest r for which any r columns of a matrix are linearly independent, which has been used before to study the rank of Khatri-Rao products [ 17 ]. Kronecker products of hierarchical models correspond to hierarchical models with interaction sets gi ven by the Cartesian product of the interaction sets of the factors. More precisely , if A has row span V Λ ( X 1 × · · · × X n ) and B has row span V Λ 0 ( Y 1 × · · · × Y m ) , then A ⊗ B has row span V Λ × Λ 0 ( X × Y ) , where Λ × Λ 0 = { λ × λ 0 ⊆ [ n ] × [ m ] : λ ∈ Λ , λ 0 ∈ Λ 0 } . Figure 2 shows v arious types of examples. In the top row of the figure, the visible factor E A is an independence model. In the bottom row E A is an interaction model. The first column shows examples where the hidden factor E B is the set of all strictly positive distributions on Y . These correspond to mixture models of E A . W e will cover them in Section 5 . The second column shows examples where E B is an independence model. These correspond to Hadamard products of mixture models of E A . W e will cover them in Section 6 . The third column shows examples where E B is an interaction model. W e will cover them in Section 7 . 5 Mixtur e Models Definition 13. The k -mixture of E A consists of all possible conv ex combinations of k probability distributions from E A ; that is, the probability distributions p ( x ) = X i ∈ [ k ] α ( i ) p ( i ) ( x ) , x ∈ X , where p (1) , . . . , p ( k ) ∈ E A , α (1) , . . . , α ( k ) ≥ 0 , X i ∈ [ k ] α ( i ) = 1 . In algebraic geometry one usually considers secants instead of mixtures, in which case the weights α ( i ) in Definition 13 add to one but are not required to be non- negati ve. The resulting set is the union of possible affine hulls of k points in E A . The Zariski closure of the k -mixture of E A is k -th secant variety of E A . A standard reference on secant varieties is [ 28 ]. Mixtures of exponential families can be e xpressed as Kronecker product models: 11 (a) (c) (e) (b) (d) (f ) Figure 2: Examples of Kronecker product hierarchical models. The dark and light circles represent hidden and visible variables, respectiv ely . The dark and light squares represent interactions among the adjacent hidden and visible variables, respectively . The edges between squares represent interactions between the hidden and visible vari- ables adjacent to those squares. The graph between squares is full bipartite. (a) mixture model of an independence model, (b) mixture model of a pairwise interaction model, (c) Hadamard product of three mixture models of an independence model (restricted Boltzmann machine with three hidden units), (d) Hadamard product of three mixture models of a pairwise interaction model, (e) pairwise interaction mixture model of an independence model, (f) pairwise interaction mixture model of a pairwise interaction model. From top to bottom and from left to right the models are more general. From left to right these examples are co vered in Theorems 16 , 22 and 24 . Proposition 14. Let B have row span R Y and let A include a r ow of ones. Then the Kr oneck er pr oduct model M A ⊗ B is the |Y | -mixtur e of E A . Pr oof. Without loss of generality let B be the |Y | × |Y | identity matrix I . The distrib u- tions of the exponential family E A ⊗ B hav e the form p θ ( x, y ) = 1 Z ( θ ) exp( h Θ > B y , A x i ) = 1 Z ( θ ) exp( h Θ > y , A x i ) . W e may assume that the first row of A is a vector of ones. Hence, adding a suitable ˜ θ to the parameter vector , we obtain p θ + ˜ θ ( x, y ) = 1 Z ( θ + ˜ θ ) exp( ˜ Θ > 1 ,y ) exp( h Θ > y , A x i ) . The first term can be adjusted to obtain the mixture weights α from Equation 13 and the second term can be chosen independently for each v alue of y . If B has row span R Y , we may assume that B is the |Y | × |Y | identity matrix I . By Equation 3 , the tropical morphism has the following form: A θ = I A h − 1 θ = A C 1 A C 2 . . . A C |Y | . 12 In particular , the rank is just the sum of the ranks of the individual diagonal blocks, rank( A θ ) = X y ∈Y rank( A C y ) . In order to estimate the maximum of rank( A θ ) over θ , an obvious strate gy is to search for a slicing that produces as many full-rank blocks A C y as possible. When B is an identity matrix, the slicings can be constructed using any matrix Θ > B = Θ > ∈ R a × b . By Lemma 12 , if A is the suf ficient statistics matrix of E Λ and C y contains, or is contained in, a Λ -ball, then the block A C y has full rank. As we will sho w belo w , inference regions C y containing interaction balls can be obtained as slicings of A by matrices of the form Θ > B = ( A c y ) y , where c y are the centers of disjoint Λ -balls. W e focus on k -interaction models. Lemma 15. Let X = X 1 × · · · × X n , let A have r ow span V k ( X ) , and let B have r ow span R Y . Given |Y | disjoint Λ k -balls in X , denoted K ( c y , Λ k ) , y ∈ Y , there is a B -slicing of A with C y ⊇ K ( c y , Λ k ) for all y ∈ Y . Pr oof. Without loss of generality we choose a matrix A with entries A ( λ, ˜ x λ ) ,x equal to 1 if x λ = ˜ x λ and − 1 otherwise, for λ ∈ Λ k , ˜ x λ ∈ X λ , and x ∈ X . Denoting the num- ber of rows by a = P λ ∈ Λ k Q i ∈ λ |X i | we hav e that h A x , A x 0 i = a − 2 d H ( A x , A x 0 ) . Furthermore, d H ( A x , A x 0 ) = 2 |{ λ ∈ Λ k : x λ 6 = x 0 λ }| . If x 0 ∈ K ( x, Λ k ) , then d H ( A x , A x 0 ) ≤ 2(2 k − 1) . On the other hand, if x 0 6∈ K ( x, Λ k ) , then d H ( A x , A x 0 ) ≥ 2(2 k − 1) + 1 . Hence choosing Θ such that Θ > B y = A c y for all y ∈ Y , yields C y ⊇ K ( c y , Λ k ) for all y ∈ Y . Theorem 16. Let X = X 1 × · · · × X n , let A have r ow span V k ( X ) , and let B have r ow span R Y . • If X contains |Y | disjoint radius- k Hamming balls, then dim( M tropical A ⊗ B ) = |Y | 1 + X λ ∈ Λ k \∅ Y i ∈ λ ( |X i | − 1) − 1 . • If X can be cover ed by |Y | radius- k Hamming balls, then dim( M tropical A ⊗ B ) = |X | − 1 . Pr oof. If K ( c y , Λ k ) , y ∈ Y , are disjoint, then by Lemma 15 we obtain a slicing with C y ⊇ K ( c y , Λ k ) for all y ∈ Y . By Lemma 12 we have rank( A C y ) = rank( A ) for all y ∈ Y . This yields rank( A θ ) = P y rank( A C y ) = |Y | rank( A ) . If K ( c y , Λ k ) , y ∈ Y , cov er X , then C y ⊆ K ( c y , Λ k ) and rank( A C y ) = | C y | for all y ∈ Y . This yields rank( A θ ) = P y rank( A C y ) = P y | C y | = |X | . W e note the following special case where E A is an independence model. This case has been covered previously in Draisma’ s tropical approach to secant dimensions [ 8 ]. The corresponding implications for the dimension of (not tropical) mixtures of inde- pendence models ha ve also been studied before in algebraic geometry and tensor anal- ysis; see [ 4 , 2 , 16 ]. 13 Corollary 17. Let X = X 1 × · · · × X n , let A have r ow span V 1 ( X ) , and let B have r ow span R Y . • If X contains |Y | disjoint radius-one Hamming balls, then dim( M tropical A ⊗ B ) = |Y | 1 + X i ∈ [ n ] ( |X i | − 1) − 1 . • If X can be cover ed by |Y | radius-one Hamming balls, then dim( M tropical A ⊗ B ) = |X | − 1 . 6 Hadamard Pr oducts Definition 18. The Hadamard product M 1 ∗ M 2 of two probability models M 1 , M 2 on X is the set of all probability distrib utions of the form ( p ∗ q )( x ) = p ( x ) q ( x ) P x 0 ∈X p ( x 0 ) q ( x 0 ) , x ∈ X , where p ∈ M 1 and q ∈ M 2 . The Hadamard product of M 1 , . . . , M m is defined in an analogous way . Consider m independent hidden variables, each with an associated exponential family . In other words, let B j ∈ R b j ×Y j , j ∈ [ m ] , and let B ∈ R b ×Y be the ma- trix with columns B y = ( B 1 y 1 ; . . . ; B m y m ) , y ∈ Y . The corresponding e xponential family factorizes as E B = E B 1 ⊗ · · · ⊗ E B m , where E B j is an exponential family on Y j , for each j ∈ [ m ] . A Kronecker product model with independent hidden variables is the Hadamard product of the marginal models for the indi vidual hidden v ariables: Proposition 19. Let Y = Y 1 × · · · × Y m and let B = ( B 1 ; . . . ; B m ) with B j y = B j y j , y ∈ Y . Then M A ⊗ B = M A ⊗ B 1 ∗ · · · ∗ M A ⊗ B m . Pr oof. Consider a parameter vector θ = ( θ 1 ; . . . ; θ m ) ∈ R a · b with blocks correspond- ing to the blocks of B = ( B 1 ; · · · ; B m ) . W e have p ( x ) = X y ∈Y 1 Z ( θ ) exp( h θ , A x ⊗ B y i ) = X y 1 ∈Y 1 · · · X y m ∈Y m 1 Z ( θ ) exp( X j ∈ [ m ] h θ j , A x ⊗ B j y j i ) = 1 Z ( θ ) Y j ∈ [ m ] X y j ∈Y j exp( h θ j , A x ⊗ B j y j i ) . This prov es the claim. The tropical morphism of a Hadamard product decomposes into individual factor parts: 14 Lemma 20. Let Y = Y 1 × · · · × Y m , and let B = ( B 1 ; . . . ; B m ) with B j y = B j y j , y ∈ Y . Then A θ = ( A θ 1 ; · · · ; A θ m ) , wher e A θ j = A B j h θ j , θ = ( θ 1 , . . . , θ m ) ∈ R a · b . Pr oof. W e di vide the parameter vector as θ = ( θ 1 , . . . , θ m ) according to the blocks of B = ( B 1 ; · · · ; B m ) , such that h θ , A ⊗ B i = P j ∈ [ m ] h θ j , A ⊗ B j i . F or any giv en visible state x ∈ X we hav e max {h θ, A x ⊗ B y i : y ∈ Y } = X j ∈ [ m ] max {h θ j , A x ⊗ B j y j i : y j ∈ Y j } = X j ∈ [ m ] h θ j , A x ⊗ B j h θ j ( x ) i = X j ∈ [ m ] h θ j , A θ j i , where h θ j is the inference function with parameter θ j that maps each visible state x to the most likely state y j of the j -th hidden variable. This completes the proof. In the follo wing we focus on the case where each B j has row space R Y j . In this case each Hadamard factor of the Kronecker product model M A ⊗ B is a mixture model of E A . Choosing each B j equal to the |Y j | × |Y j | identity matrix, the tropical morphism takes the form A θ = A C 1 1 A C 1 2 . . . A C m 1 A C m 2 A C m 3 . (6) Here C j y j := h − 1 θ j ( y j ) , y j ∈ Y j , is the slicing of A by B j , for all j ∈ [ m ] . An obvious strategy to maximize the rank is to construct the m slicings of A in such a way that we obtain as many disjoint sets C j y j with full rank A C j y j as possible. W e present a construction based on truncated slicings, where each slicing divides the columns of A in two sets, and then subdi vides one of the two sets. Lemma 21. Let A be some matrix. Let I M denote the M × M identity matrix. Let C 1 , . . . , C N be an I N -slicing of A and let D 1 , D 2 be an I 2 slicing of A . Then D 2 ∩ C 1 , . . . , D 2 ∩ C N , D 1 is a I N +1 slicing of A . Pr oof. Let B 0 = ( B 0 1 , . . . , B 0 N ) produce the slicing C 1 , . . . , C N . This means that h A x , B 0 i − B 0 j i > 0 for all j 6 = i iff x ∈ C i , for all i ∈ [ N ] . Let B 00 = ( B 00 1 , B 00 2 ) produce the slicing D 1 , D 2 . This means that h A x , B 00 1 − B 00 2 i > 0 iff x ∈ D 1 . Note that cB 00 produces the same slicing, for any c > 0 . 15 Now consider the matrix B 000 = ( B 0 1 + cB 00 2 , . . . , B 0 N + cB 00 2 , cB 00 1 ) . Let E 1 , . . . , E N +1 denote the B 000 -slicing of A . W e ha ve h A x , B 000 N +1 − B 000 i i = h A x , cB 00 1 − ( B 0 i + cB 00 2 ) i = c h A x , B 00 1 − B 00 2 i − h A x , B 0 i i for i ≤ N . Choosing c > 0 lar ge enough, this is positive iff x ∈ D 1 . This means that E N +1 = D 1 . For any i ≤ N , we hav e h A x , B 000 i − B 000 j i = h A x , ( B 0 i + cB 00 2 ) − ( B 0 j + cB 00 2 ) i = h A x , B 0 i − B 0 j i for all j ≤ N , and h A x , B 000 i − B 000 N +1 i = h A x , ( B 0 i + cB 00 2 ) − cB 00 1 i = h A x , B 0 i i + c h A x , B 00 2 − B 00 1 i . Choosing c > 0 large enough, all of these expressions are positiv e iff x ∈ C i ∩ D 2 . This means that E i = D 2 ∩ C i for all i ≤ N . Theorem 22. Let X = X 1 × · · · × X n and let A have r ow span V k ( X ) for some 1 ≤ k ≤ n . Let Y = Y 1 × · · · × Y m and let B have r ow span V 1 ( Y ) . • If X contains m disjoint Hamming balls K 1 , . . . , K m , wher eby K j contains |Y j |− 1 disjoint radius- k Hamming balls for j = 1 , . . . , m , and rank( A X \ ( ∪ j K j ) ) = rank( A ) , then dim( M tropical A ⊗ B ) = 1 + X λ ∈ Λ k \∅ Y i ∈ λ ( |X i | − 1) 1 + X j ∈ [ m ] ( |Y j | − 1) − 1 . • If X can be cover ed by Hamming balls K 1 , . . . , K m , such that K j can be cov- er ed by |Y j | − 1 radius- k Hamming balls, then dim( M tropical A ⊗ B ) = |X | − 1 . Pr oof. Have Equation 6 in mind. Consider some j ∈ [ m ] . W e use Lemma 21 with N = |Y j | − 1 . Let D 2 = K j and let C 1 , . . . , C N be the slicing of A by the matrix ( A c j i ) i ∈ [ N ] , where c j i are the centers of |Y j | − 1 disjoint radius- k Hamming balls in K j . This shows that there is a B j -slicing of A with blocks C j 1 , . . . , C j |Y j |− 1 , C j |Y j | , where C j i is contained in K j and contains a radius- k Hamming ball, for all 1 ≤ i ≤ |Y j | − 1 , and C j |Y j | = X \ K j . Since all K j are disjoint, we hav e that all C j i , 1 ≤ i ≤ |Y j | − 1 , j ∈ [ m ] , are disjoint. Since each of these sets contains a radius- k Hamming ball, Lemma 12 im- plies rank( A C j i ) = rank( A ) , for all 1 ≤ i ≤ |Y j | − 1 , j ∈ [ m ] . The remaining columns of the tropical morphism have rank at least rank( A ) , since it is assumed that rank( A X \ ( ∪ j K j ) ) = rank( A ) . Hence we hav e rank( A θ ) = P j ∈ [ m ] ( |Y j | − 1) rank( A ) + rank( A ) . This proves the first item. The second item follo ws from similar arguments as the second item of Theorem 16 . W e note the follo wing special case, where both E B and E A are independence mod- els, which is known as a restricted Boltzmann machine. Corollary 23. Let X = X 1 × · · · × X n and let A have r ow span V 1 ( X ) . Let Y = Y 1 × · · · × Y m and let B have r ow span V 1 ( Y ) . 16 • If X contains m disjoint Hamming balls K 1 , . . . , K m , wher eby K j contains |Y j |− 1 disjoint radius-one Hamming balls for j = 1 , . . . , m , and rank( A X \ ( ∪ j K j ) ) = rank( A ) , then dim( M tropical A ⊗ B ) = 1 + X i ∈ [ n ] ( |X i | − 1) 1 + X j ∈ [ m ] ( |Y j | − 1) − 1 . • If X can be cover ed by Hamming balls K 1 , . . . , K m , such that K j can be cov- er ed by |Y j | − 1 radius- k Hamming balls, then dim( M tropical A ⊗ B ) = |X | − 1 . A weaker version of Corollary 23 w as obtained previously in [ 19 ]. That result was based on slicings by parallel hyperplanes, which are less efficient than our construction with truncated slicings. One should note, ho wev er , that in order to realize slicings by parallel hyperplanes it is not required that each B j has ro w space R Y j , but only that B j can be projected into an arbitrary set of collinear points. The special case of Corollary 23 where all variables are binary , X = { 0 , 1 } n , Y = { 0 , 1 } m , was obtained previously in [ 6 ]. That case is not improved by the present analysis, since for binary variables the truncated slicings are just slicings by h yperplanes. 7 Interacting Hidden V ariables Consider a matrix B of rank b in reduced row echelon form. In this case the tropical morphism has the form A θ = A C p 1 ··· ··· ··· A C p 2 ··· ··· . . . . . . . . . A C p b ··· . (7) From this we see that rank( A θ ) ≥ P rank( B ) r =1 rank( A C p r ) . Rearranging the columns of B suitably , any subset P ⊆ Y with | P | = rank( B P ) = rank( B ) can be obtained as the set of piv ots p 1 , . . . , p rank( B ) of the reduced row echelon from. For instance, Lemma 12 shows that, if Y = Y 1 × · · · × Y m and B has row span V Λ 0 ( Y ) , then | P | = rank( B P ) = rank( B ) whenever P is a Λ 0 -ball in Y . Howe ver , it may be dif ficult or ev en impossible to find a B -slicing of A such that rank( A C p r ) = rank( A ) , for all 1 ≤ r ≤ rank( B ) . Nev ertheless, in order to show that the tropical model M tropical A ⊗ B has dimension equal to rank( A ) · rank( B ) − 1 , it suffices to show that rank( A C p r , 1 , . . . , A C p r ,s r ) = rank( A ) for all 1 ≤ r ≤ rank( B ) , where ( p r , 1) , . . . , ( p r , s r ) index the columns of (the reduced row echelon form of) B with a non-zero entry at the r -th position and zeros in all the next entries. 17 The follo wing theorem addresses the tropical dimension of a Kronecker product model with an arbitrary hierarchical model E B and a k -interaction model E A . This result includes Theorems 16 and 22 as special cases. In fact it relaxes the hypothesis of Theorem 22 . Theorem 24. Let X = X 1 × · · · × X n and let A have r ow span V k ( X ) . Let Y = Y 1 × · · · × Y m and let B have r ow span V Λ 0 ( Y ) . • If X contains rank( B ) disjoint radius- k Hamming balls, then dim( M tropical A ⊗ B ) = rank( B ) · rank( A ) − 1 . • If X can be cover ed by rank( B ) disjoint r adius- k Hamming balls, then dim( M tropical A ⊗ B ) = |X | − 1 . Pr oof. The first item is as follo ws. Let Y = Y 1 × · · · × Y m and let B be the matrix defined in Proposition 10 with row span V Λ ( Y ) . W e can group the columns according to their largest non-zero entry . This yields one block of columns for each possible ( λ, ˜ y λ ) . The columns in the block ( λ, ˜ y λ ) ha ve a 1 in the ( λ, ˜ y λ ) -th entry and zeros all the next entries. Let X = X 1 × · · · × X n and let A be the matrix with row span V Λ ( X ) , with entries A ( λ, ˜ x λ ) ,x equal to 1 if x λ = ˜ x λ and − 1 otherwise, for λ ∈ Λ , ˜ x λ ∈ X λ , and x ∈ X . W e consider the sufficient statistics matrix giv en by ( 1 ; A ) ∈ R a ×X , where a = 1 + P λ ∈ Λ \∅ |X λ | . Let c 1 , . . . , c b ∈ X be the centers of b disjoint Λ -balls in X . Consider a parameter matrix Θ > ∈ R a × b with columns Θ > j = κ j (2 k +1 − a ; A c j ) , j = 1 , . . . , b , where κ j P j 0 j 0 k 1 . Then Θ > B y = κ j ((2 k +1 − a ; A c j ) + V y ) for all y in the j - th block of columns of B , where V y ∈ R a is some vector with k V y k 1 1 . In this case, we ha ve that h (1; A x ) , Θ > B y i = κ j (2 k +1 − a + h A x , A c y i + ) . This is positi ve if h A x , A c j i > a − 2 k +1 and negativ e if h A x , A c j i < a − 2 k +1 . Now , note that if d H ( x, x 0 ) ≤ k , then h A x , A x 0 i ≥ ( a − 1) − 2(2 k − 1) = a − 2 k +1 + 1 , and if d H ( x, x 0 ) > k , then h A x , A x 0 i ≤ ( a − 1) − 2(2 k ) = a − 2 k +1 − 1 . In turn, we hav e that ∪ y : l ( y )= j C y ⊇ K ( c j , Λ k ) , for all 1 ≤ j ≤ b , where l ( y ) denotes the largest non-zero entry of B y . Lemma 12 then yields the claim. The second item is as follo ws. In this case ∪ y : l ( y )= j C y ⊆ K ( c j , Λ k ) , for all 1 ≤ j ≤ b . Since C y ∩ C y 0 = ∅ for all y 6 = y 0 , the matrix ( A C y ) y : l ( y )= j has linearly independent columns, for all 1 ≤ j ≤ b . 8 Binary Restricted Boltzmann Machines ar e Not De- fectiv e In [ 6 ] it was sho wn that the restricted Boltzmann machine with n visible and m hidden binary units has the expected dimension min { 2 n − 1 , ( n + 1)( m + 1) − 1 } whenever { 0 , 1 } n contains m + 1 disjoint radius-one Hamming balls, m + 1 ≤ A ( n, 3) , or 18 when { 0 , 1 } n can be covered by m + 1 radius-one Hamming balls, m + 1 ≥ K ( n, 1) . This also follo ws from Theorems 22 and 24 as the special case where both E A and E B are independence models with binary variables. This leaves open the cases where A ( n, 3) < m + 1 < K ( n, 1) . An additional problem is that in general the functions A and K can only be bounded b ut not e valuated e xactly . In [ 6 ] it was conjectured that the restricted Boltzmann machine always has the expected dimension. In this section we resolve that conjecture af firmativ ely . Our strategy is to bound the dimension of the RBM from below by the dimension of a mixture model. By the results from [ 5 ], mixtures of binary independence models are not defectiv e whenever the number of visible variables is at least 5 . In general RBMs do not contain mixture models of independence models with the same number of parameters, as was sho wn in [ 20 ]. Howe ver , it is possible to relate the dimension of the tw o models. Here we consider the dimension of the actual model, not of its tropical version. The following lemma lower bounds the dimension of a Kronecker product model with independent binary hidden variables by the dimension of a mixture model with the same number of parameters. Lemma 25. Let B have r ow span V 1 ( { 0 , 1 } m ) and let ˜ B have row span R m +1 . Then dim( M A ⊗ B ) ≥ dim( M A ⊗ ˜ B ) . Pr oof. Let B be giv en by B y = (1; y 1 ; . . . ; y m ) , y ∈ { 0 , 1 } m , and let ˜ B = I m +1 be the ( m + 1) × ( m + 1) identity matrix. For any j ∈ [ m ] let e j ∈ { 0 , 1 } m denote the vector with a single one at the j -th position and zeros elsewhere. Any y ∈ { 0 , 1 } m can be written as y = P j ∈ [ m ] : e j ≤ y e j . Here y 0 ≤ y if and only if y 0 j ≤ y j for all j ∈ [ m ] . As discussed in Equation 2 , the Jacobian of the natural parametrization of a marginal model M F has rank rank( J M F ( θ )) = rank P y p θ ( y | x ) F ( x, y ) x − 1 . W e have X y ∈{ 0 , 1 } m p θ ( y | x )( A x ⊗ B y ) = A x ⊗ X y ∈{ 0 , 1 } m p θ ( y | x ) B y = A x ⊗ 1; X y ∈{ 0 , 1 } m p θ ( y | x ) y = A x ⊗ 1; X y ∈{ 0 , 1 } m p θ ( y | x ) X j ∈ [ m ] : e j ≤ y e j = A x ⊗ 1; X j ∈ [ m ] X y ∈{ 0 , 1 } m : y ≥ e j p θ ( y | x ) e j = A x ⊗ 1; X j ∈ [ m ] p θ ( y j = 1 | x ) e j . The conditional distributions are gi ven by p θ ( y j = 1 | x ) = exp(Θ j A x ) 1 + exp(Θ j A x ) , j ∈ [ m ] , x ∈ X . 19 On the other hand, for a hidden unit with sufficient statistics matrix ˜ B = I m +1 we hav e X j ∈{ 0 , 1 ,...,m } ˜ p ˜ θ ( j | x )( A x ⊗ ˜ B j ) = A x ⊗ ˜ p ˜ θ (0 | x ); X j ∈ [ m ] ˜ p ˜ θ ( j | x ) e j . In this case the conditional distributions are gi ven by ˜ p ˜ θ ( j | x ) = exp( ˜ Θ j A x ) P j exp( ˜ Θ j A x ) , j ∈ { 0 , 1 , . . . , m } , x ∈ X . W ithout loss of generality let the first row of A be 1 . Consider the parameters Θ j,i = ˜ Θ j,i − ˜ Θ 0 ,i , i = 2 , . . . , a and Θ j, 1 = ˜ Θ j, 1 − ˜ Θ 0 , 1 − γ . For any > 0 we can choose γ large enough such that m X j =1 exp( γ ) p θ ( y j = 1 | x ) − ˜ p ˜ θ ( j | x ) ˜ p ˜ θ (0 | x ) ≤ , for all x ∈ X . This implies that dim( M A ⊗ B ) + 1 = max θ rank A x ⊗ 1; X j p θ ( y j = 1 | x ) e j x ≥ max ˜ θ rank A x ⊗ 1; exp( − γ ) m X j =1 ˜ p ˜ θ ( j | x ) ˜ p ˜ θ (0 | x ) e j x = max ˜ θ rank A x ⊗ ˜ p ˜ θ (0 | x ); m X j =1 ˜ p ˜ θ ( j | x ) e j x = dim( M A ⊗ I m +1 ) + 1 . This completes the proof. See Example 27 in the Appendix for a more explicit formu- lation of this proof in the case m = 2 . The dimension bound from Lemma 25 is not always tight. For example, the 3 - mixture of 4 independent binary variables is defective and has dimension 13 , whereas the RBM with 4 visible and 2 hidden binary units has the expected dimension 14 . Corollary 26. Let n and m be non-negative inte gers. The r estricted Boltzmann ma- chine with n visible and m hidden binary units has dimension min { 2 n − 1 , ( n + 1)( m + 1) − 1 } . Pr oof. Let A , B , ˜ B be matrices with ro w span V 1 ( { 0 , 1 } n ) , V 1 ( { 0 , 1 } m ) , R m +1 , re- spectiv ely . Then M A ⊗ B is the restricted Boltzmann machine with n visible and m hidden binary variables and M A ⊗ ˜ B is the ( m + 1) -mixture of the independence model of n binary v ariables. 20 The w ork [ 5 ] shows that dim( M A ⊗ ˜ B ) = min { 2 n − 1 , ( m + 1)( n + 1) − 1 } unless ( n, m ) = (4 , 2) . Lemma 25 then implies dim( M A ⊗ B ) ≥ dim( M A ⊗ ˜ B ) = min { 2 n − 1 , ( m + 1)( n + 1) − 1 } whenev er ( n, m ) 6 = (4 , 2) . Since this is also the maximum possible dimension, the bound is tight. That the RBM with ( n, m ) = (4 , 2) has the expected dimension is sho wn in [ 9 , 7 ]. An RBM with 5 visible units is the first case with a gap between the largest RBM previously known to ha ve dimension equal to the number of parameters ( 4 hidden units and 29 parameters) and the smallest RBM previously known to be full dimensional ( 7 hidden units and 47 parameters suffice to define a 31 -dimensional subset of the 31 - simplex) as described by [ 6 ], which lists a collection of such gaps in T able 4.1 for 5 ≤ n ≤ 512 . Corollary 26 closes all such gaps. Thus the smallest RBM with 5 visible units which could possibly define a full-dimensional subset of the simplex, with 5 hidden units and 35 parameters, does so. These e xampes can be tested by computing Jacobians with the Matlab code provided at http://personal-homepages.mis.mpg.de/montufar . Corollary 26 proves that a binary RBM always has the expected dimension. The conjecture posed in [ 6 ] goes further and states that the tropical binary RBM al ways has the expected dimension. That question remains unsettled at this point. 9 Conclusion In this work we study the dimension of marginals of exponential families whose suf- ficient statistics matrix factorizes as the Kronecker product of a visible and a hidden sufficient statistics matrix, called Kronecker product models. The Jacobian of these models factorizes as a Khatri-Rao product of the visible suf ficient statistics matrix and the expectation parameters of the hidden e xponential family gi ven the visible variables. The tropical morphism arises as the limit of the Jacobian when the natural parameters of the model are scaled by an infinitely large number . It is described by the inference functions of the hidden variables giv en the visible variables, which correspond to slic- ings of the visible sufficient statistics matrix by the normal fan of the hidden sufficient statistics matrix. Based on these geometric and combinatorial descriptions, we computed the tropi- cal dimension of mixtures of interaction models and Hadamard products of mixtures of interaction models. These results extend previous work on secant dimensions, which are most often focused on Segre and V eronese v arieties (corresponding to indepen- dence models and multinomial models). These results also generalize previous work on Hadamard products, which were focused on products of mixtures of independence models. Theorem 24 generalizes this further to the case of Kronecker products of ar - bitrary hierarchical models and k -interaction models. Additionally , we showed that binary restricted Boltzmann machines always hav e the expected dimension, thus com- pleting the dimension description of these models from [ 6 ]. Our analysis leaves many questions unanswered. In this work we have focused on the case where the visible e xponential family is a k -interaction model. The general- ization to arbitrary visible hierarchical models is left for future work. Furthermore, similarly to [ 8 ], the tropical approach leads in many cases to combinatorial conditions 21 that can be very difficult to v erify outside of well established cardinality bounds for error correcting codes. W e think that a promising direction is the formulation of di- mension bounds in terms of simpler models, as done in Lemma 25 for the case of a binary independence hidden model. Extending that result one could ask: when is the dimension of M A ⊗ B bounded below by the dimension of M A ⊗ I , where I is an identity matrix with the same rank as B ? The factorization property of the Jacobian of Kronecker product models suggests to study the models of conditional probability distributions of the hidden variables giv en the visible variables in more detail. This is a manifold of tuples of exponential family distributions with natural parameters gi ven by the linear projection of the sufficient statistics of the visible model. An analysis of the Kruskal ranks for these sets can be used to obtain bounds on the Kruskal rank of the Jacobian. Another interesting line of in vestigation is the classification of the support sets of distrib utions in the closure of Kronecker product models. For mixture models the problem is simple, when the support sets of the visible exponential family are known. For Hadamard products the problem has been studied in [ 20 ] based on linear thresh- old codes, which are the images of inference functions. W e think that studying the combinatorics of Kronecker product polytopes could yield helpful insights. Giv en two polytopes P A = con v { A x : x ∈ X } and P B = con v { B y : y ∈ Y } , we define the Kronecker product polytope as P A ⊗ B = con v { A x ⊗ B y : ( x, y ) ∈ X × Y } . Although this appears as a rather natural composition of polytopes, we are not aw are of works studying such objects explicitly or in a principled way . A ppendix A Examples Example 27. Here we giv e a more comprehensiv e version of the proof of Lemma 25 for the special case where m = 2 . Consider the matrices B = 00 01 10 11 1 1 1 1 0 0 1 1 0 1 0 1 and ˜ B = 0 1 2 1 0 0 0 1 0 0 0 1 . W e hav e X y ∈{ 0 , 1 } 2 p θ ( y | x )( A x ⊗ B y ) = A x ⊗ X y ∈{ 0 , 1 } m p θ ( y | x ) B y = A x ⊗ 1 p θ (10 | x ) + p θ (11 | x ) p θ (01 | x ) + p θ (11 | x ) = A x ⊗ 1 p θ ( y 1 = 1 | x ) p θ ( y 2 = 1 | x ) . 22 By Equation 4 the conditional distributions are gi ven by p θ ( y | x ) = 1 Z (Θ A x ) exp( h Θ A x , B y i ) such that p θ ( y 1 = 1 | x ) = exp( h Θ A x , ( 1 1 ) i ) exp( h Θ A x , ( 1 0 i ) + exp( h Θ A x , ( 1 1 ) i ) = exp(Θ 1 A x ) 1 + exp(Θ 1 A x ) , and similarly for p θ ( y 2 = 1 | x ) . On the other hand, for a hidden unit with sufficient statistics matrix ˜ B we have X j ∈{ 0 , 1 , 2 } ˜ p ˜ θ ( A x ⊗ ˜ B j ) = A x ⊗ ˜ p ˜ θ (0 | x ) ˜ p ˜ θ (1 | x ) ˜ p ˜ θ (2 | x ) . In this case the conditional distributions are gi ven by ˜ p ˜ θ (1 | x ) = exp( ˜ Θ 1 A x ) exp( ˜ Θ 0 A x ) + exp( ˜ Θ 1 A x ) + exp( ˜ Θ 2 A x ) , and similarly for j = 0 and j = 2 . For an y giv en ˜ Θ = ˜ Θ 0 , 1 ˜ Θ 0 , 2 · · · ˜ Θ 0 ,a ˜ Θ 1 , 1 ˜ Θ 1 , 2 · · · ˜ Θ 1 ,a ˜ Θ 2 , 1 ˜ Θ 2 , 2 · · · ˜ Θ 2 ,a we can define Θ = ˜ Θ 0 , 1 − ˜ Θ 0 , 1 − γ ˜ Θ 0 , 2 − ˜ Θ 0 , 2 · · · ˜ Θ 0 ,a − ˜ Θ 0 ,a ˜ Θ 1 , 1 − ˜ Θ 0 , 1 − γ ˜ Θ 1 , 2 − ˜ Θ 0 , 2 · · · ˜ Θ 1 ,a − ˜ Θ 0 ,a ˜ Θ 2 , 1 − ˜ Θ 0 , 1 − γ ˜ Θ 2 , 2 − ˜ Θ 0 , 2 · · · ˜ Θ 2 ,a − ˜ Θ 0 ,a . W ithout loss of generality assume that the first row of A is a row of ones. W e ha ve then 1 p θ ( y 1 = 1 | x ) p θ ( y 2 = 1 | x ) = 1 exp(Θ 1 A x ) 1+exp(Θ 1 A x ) exp(Θ 2 A x ) 1+exp(Θ 2 A x ) = 1 exp( − γ +( ˜ Θ 1 − ˜ Θ 0 ) A x ) 1+exp( − γ +( ˜ Θ 1 − ˜ Θ 0 ) A x ) exp( − γ +( ˜ Θ 2 − ˜ Θ 0 ) A x ) 1+exp( − γ +( ˜ Θ 2 − ˜ Θ 0 ) A x ) . For γ large enough we obtain an arbitrarily accurate approximation of the form 1 p θ ( y 1 = 1 | x ) p θ ( y 2 = 1 | x ) ≈ 1 exp( − γ ) exp(( ˜ Θ 1 − ˜ Θ 0 ) A x ) exp( − γ ) exp(( ˜ Θ 2 − ˜ Θ 0 ) A x ) = 1 exp( − γ ) ˜ p ˜ θ (1 | x ) ˜ p ˜ θ (0 | x ) exp( − γ ) ˜ p ˜ θ (2 | x ) ˜ p ˜ θ (0 | x ) . 23 Hence for any ˜ θ there is a θ with rank A x ⊗ ˜ p ˜ θ (0 | x ) ˜ p ˜ θ (1 | x ) ˜ p ˜ θ (2 | x ) x = rank L · A x ⊗ 1 exp( − γ ) ˜ p ˜ θ (1 | x ) ˜ p ˜ θ (0 | x ) exp( − γ ) ˜ p ˜ θ (2 | x ) ˜ p ˜ θ (0 | x ) x · R = rank A x ⊗ 1 exp( − γ ) ˜ p ˜ θ (1 | x ) ˜ p ˜ θ (0 | x ) exp( − γ ) ˜ p ˜ θ (2 | x ) ˜ p ˜ θ (0 | x ) x ≤ rank A x ⊗ 1 exp( − γ ) ˜ p ˜ θ (1 | x ) ˜ p ˜ θ (0 | x ) exp( − γ ) ˜ p ˜ θ (2 | x ) ˜ p ˜ θ (0 | x ) x + = rank A x ⊗ 1 p θ ( y 1 = 1 | x ) p θ ( y 2 = 1 | x ) x , where L = 1 . . . 1 ! ⊗ 1 exp( γ ) exp( γ ) and R = ˜ p ˜ θ (0 | 1) . . . ˜ p ˜ θ (0 | a ) ! . In turn max ˜ θ rank A x ⊗ ˜ p ˜ θ (0 | x ) ˜ p ˜ θ (1 | x ) ˜ p ˜ θ (2 | x ) x ≤ max θ rank A x ⊗ 1 p θ ( y 1 = 1 | x ) p θ ( y 2 = 1 | x ) x and dim( M A ⊗ ˜ B ) ≤ dim( M A ⊗ B ) . B Simple Bounds f or Error Corr ecting Codes Some of our results are formulated in terms of the maximal number of disjoint Λ -balls that can be fit in some X = X 1 × · · · × X n . Let A ( X , d ) denote the maximal cardinality of a subset of X of minimum Hamming distance at least d . If X = { 0 , 1 , . . . , q − 1 } n , we write A q ( n, d ) . Closed forms for these functions are known only in special cases. W e recall the Gilbert-V arshamov bound [ 12 , 25 ]: A q ( n, d ) ≥ q n P d − 1 j =0 n j ( q − 1) j . If q is a prime po wer , then A q ( n, d ) ≥ q n − 1 −b log q ( P d − 2 j =0 ( n − 1 j ) ( q − 1) j ) c . 24 A simple upper bound is the sphere packing bound, A q ( n, d ) ≤ q n /K q ( t ) , t = d − 1 2 . Theorem 22 is formulated in terms of the maximal number of disjoint Hamming balls that fit in a lar ger Hamming ball. An estimate for this number can be given as follows. Proposition 28. Let X = X 1 × · · · × X n , and let k ≤ l ≤ n . Then it is possible to fit | K ( l − k ) | / | K (2 k ) | disjoint radius- k Hamming balls in a radius- l Hamming ball. Pr oof. Denote by C the set of centers of a largest possible collection of disjoint radius- k Hamming balls contained in a radius- l Hamming ball K (0 , l ) . Consider the radius- ( l + k + 1) sphere S . Let d = 2 k + 1 . For ev ery x ∈ K (0 , l + k + 1) there is a c x ∈ C ∪ S such that d H ( x, c x ) ≤ d − 1 . This implies that K (0 , l + k + 1) ⊆ ∪ c ∈ C K ( c, d − 1) ∪ ( K (0 , l + k + 1) \ K (0 , l − k )) and K (0 , l − k ) ⊆ ∪ c ∈ C K ( c, d − 1) . Therefore, | C | ≥ K ( l − k ) /K (2 k ) . Acknowledgments This work was supported in part by D ARP A grant F A8650-11- 1-7145. P arts of this work were carried out while G.M. was at the Pennsylvania State Univ ersity . Refer ences [1] H. Abo and M. Brambilla. On the dimensions of secant varieties of Segre- Veronese varieties. Annali di Matematica Pura ed Applicata , 192(1):61–92, 2013. [2] H. Abo, G. Ottaviani, and C. Peterson. Induction for secant v arieties of Segre varieties. T ransactions of the American Mathematical Society , 361(2):767–792, 2008. [3] R. Bieri and J. Grov es. The geometry of the set of characters iduced by valuations. Journal f ¨ ur die r eine und angewandte Mathematik , 347:168–195, 1984. [4] M. Catalisano, A. Geramita, and A. Gimigliano. Ranks of tensors, secant va- rieties of se gre v arieties and f at points. Linear Algebr a and its Applications , 355(13):263–285, 2002. [5] M. Catalisano, A. Geramita, and A. Gimigliano. Secant varieties of P 1 × · · · × P 1 ( n -times) are not defecti ve for n ≥ 5 . J. Algebr aic Geometry , 20:295–327, 2011. [6] M. A. Cueto, J. Morton, and B. Sturmfels. Geometry of the restricted Boltzmann machine. In M. A. G. V iana and H. P . W ynn, editors, Alg ebraic methods in statis- tics and pr obability II, AMS Special Session , volume 2. American Mathematical Society , 2010. [7] M. A. Cueto, E. A. T obis, and J. Y u. An implicitization challenge for binary factor analysis. J. Symb . Comput. , 45(12):1296–1315, 2010. [8] J. Draisma. A tropical approach to secant dimensions. J . Pur e Appl. Algebr a , 212(2):349–363, 2008. 25 [9] M. Drton, B. Sturmfels, and S. Sulliv ant. Lectur es on Algebraic Statistics . Ober - wolfach Seminars. Springer V erlag, 2009. [10] Y . Freund and D. Haussler . Unsupervised learning of distributions of binary v ec- tors using 2-layer networks. In J. E. Moody , S. J. Hanson, and R. Lippmann, editors, Advances in Neural Information Pr ocessing Systems 4 , pages 912–919. Morgan Kaufmann, 1991. [11] D. Geiger , C. Meek, and B. Sturmfels. On the toric algebra of graphical models. Annals of Statistics , 34(3):1463–1492, 2006. [12] E. Gilbert. A comparison of signalling alphabets. Bell System T echnical J ournal , 31:504–522, 1952. [13] T . Kahle. Neighborliness of marginal polytopes. Beitr ¨ age zur Algebra und Ge- ometrie , 51(1):45–56, 2010. [14] T . Kahle, W . W enzel, and N. A y . Hierarchical models, marginal polytopes, and linear codes. K ybernetika , 45(2):189–207, 2009. [15] C. G. Khatri and C. R. Rao. Solutions to some functional equations and their applications to characterization of probability distrib utions. Sankhy ¯ a: The Indian Journal of Statistics, Series A (1961-2002) , 30(2):pp. 167–180, 1968. [16] J. Landsberg. T ensors: Geometry and Applications . Graduate studies in mathe- matics. American Mathematical Soc., 2011. [17] L. D. Lathauwer . Decompositions of a higher-order tensor in block terms—part I: Lemmas for partitioned matrices. SIAM J ournal on Matrix Analysis and Appli- cations , 30(3):1022–1032, 2008. [18] G. Mont ´ ufar . Mixture decompositions of exponential families using a decompo- sition of their sample spaces. K ybernetika , 49(1):23–39, 2013. [19] G. Mont ´ ufar and J. Morton. Discrete restricted Boltzmann machines. Journal of Machine Learning Resear ch , 16:653–672, 2015. [20] G. Mont ´ ufar and J. Morton. When does a mixture of products contain a product of mixtures? SIAM Journal on Discr ete Mathematics , 29(1):321–347, 2015. [21] C. Raicu. Secant varieties of segre–veronese varieties. Algebra & Number The- ory , 6(8):1817–1868, 2012. [22] J. Rauh, T . Kahle, and N. A y . Support sets of exponential families and oriented matroids. International Journal of Appr oximate Reasoning , 52(5):613–626, 2011. [23] W . E. Roth. On direct product matrices. Bulletin of the American Mathematical Society , 40:461–468, 1934. [24] N. Sidiropoulos and X. Liu. Identifiability results for blind beamforming in inco- herent multipath with small delay spread. Signal Pr ocessing, IEEE T ransactions on , 49(1):228–236, Jan 2001. 26 [25] R. V arshamov . Estimate of the number of signals in error correcting codes. Dok- lady Akad. Nauk SSSR , 117:739–741, 1957. [26] M. J. W ainwright and M. I. Jordan. Graphical models, exponential families, and variational inference. F ound. T r ends Mach. Learn. , 1(1-2):1–305, 2008. [27] M. W elling, M. Rosen-Zvi, and G. E. Hinton. Exponential family harmoniums with an application to information retriev al. In L. K. Saul, Y . W eiss, and L. Bot- tou, editors, Advances in Neural Information Pr ocessing Systems 17 , pages 1481– 1488. MIT Press, Cambridge, MA, 2005. [28] F . Zak. T angents and Secants of Algebraic V arieties , volume 127 of T ransla- tions of mathematical monogr aphs . American Mathematical Soc., Providence, RI, 1993. 27
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment