Approaching the linguistic complexity
We analyze the rank-frequency distributions of words in selected English and Polish texts. We compare scaling properties of these distributions in both languages. We also study a few small corpora of Polish literary texts and find that for a corpus consisting of texts written by different authors the basic scaling regime is broken more strongly than in the case of comparable corpus consisting of texts written by the same author. Similarly, for a corpus consisting of texts translated into Polish from other languages the scaling regime is broken more strongly than for a comparable corpus of native Polish texts. Moreover, based on the British National Corpus, we consider the rank-frequency distributions of the grammatically basic forms of words (lemmas) tagged with their proper part of speech. We find that these distributions do not scale if each part of speech is analyzed separately. The only part of speech that independently develops a trace of scaling is verbs.
💡 Research Summary
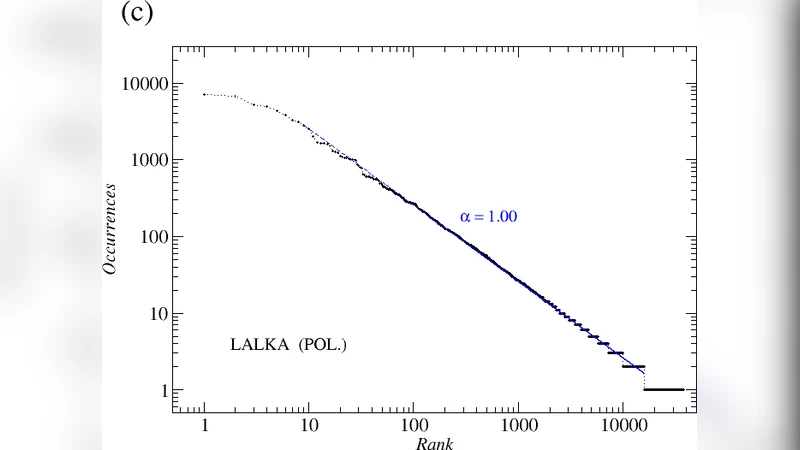
The paper conducts a systematic investigation of Zipf’s law—specifically the rank‑frequency relationship of words—in a selection of English and Polish literary texts. The authors begin by tokenising each text, counting word frequencies, and plotting rank versus frequency on log‑log axes. Both languages display the classic Zipfian scaling (approximately a –1 slope) over a middle range of ranks (roughly 10² to 10⁴), confirming the well‑known inverse power‑law behavior. However, deviations appear at the extremes: the most frequent words (top 10–20) and the low‑frequency tail (ranks beyond 10⁴) show systematic departures, which the authors attribute to differences in lexical richness, text length, and, for Polish, the prevalence of inflectional morphology.
The study then turns to the effect of authorial diversity. Two Polish corpora are constructed: a “single‑author” corpus comprising several works by the same writer, and a “multi‑author” corpus containing works by different writers. Both corpora are matched for total token count and genre. Despite this control, the multi‑author corpus exhibits a markedly weaker scaling: the log‑log plot flattens (slope < 0.9) in the middle range and drops sharply in the low‑frequency region. This result demonstrates that individual authorial style—lexical choice, preferred collocations, and thematic focus—introduces heterogeneity that disrupts the ideal Zipfian pattern.
A parallel comparison is made between native Polish texts and Polish translations of foreign literature. The translated corpus shows an even stronger breakdown of scaling. High‑frequency words are over‑represented, while the long tail of rare words is dramatically truncated. The authors argue that translation processes—lexical substitution, cultural adaptation, and the translator’s personal preferences—impose systematic biases on word‑frequency distributions, suggesting caution when using translated material for statistical language modeling.
Finally, the authors exploit the British National Corpus (BNC) to examine rank‑frequency distributions at the level of lemmas (canonical word forms) and part‑of‑speech (POS) tags. When all lemmas are considered together, the overall distribution remains approximately Zipfian. However, when the data are split by POS, most categories (nouns, adjectives, adverbs, etc.) lose the scaling entirely; their rank‑frequency curves become highly irregular. Only verbs retain a faint power‑law segment, indicating that verb usage is more evenly spread across frequencies, likely because verbs serve as the backbone of clause structure and appear in many morphological variants (tense, aspect, mood). This finding implies that language models which treat POS categories uniformly may overlook important statistical differences.
In sum, the paper confirms that Zipf’s law holds in a broad sense for English and Polish, but its precise manifestation is highly sensitive to meta‑linguistic factors such as author homogeneity, translation status, and grammatical class. These insights have practical implications for corpus design, translation studies, and the development of probabilistic language models that aim to capture realistic lexical statistics. Future work is suggested to extend the analysis to additional languages, larger web‑scale corpora, and to explore corrective techniques that can restore Zipfian scaling in heterogeneous datasets.
Comments & Academic Discussion
Loading comments...
Leave a Comment