Learning Causal Graphs with Small Interventions
We consider the problem of learning causal networks with interventions, when each intervention is limited in size under Pearl's Structural Equation Model with independent errors (SEM-IE). The objective is to minimize the number of experiments to disc…
Authors: Karthikeyan Shanmugam, Murat Kocaoglu, Alex
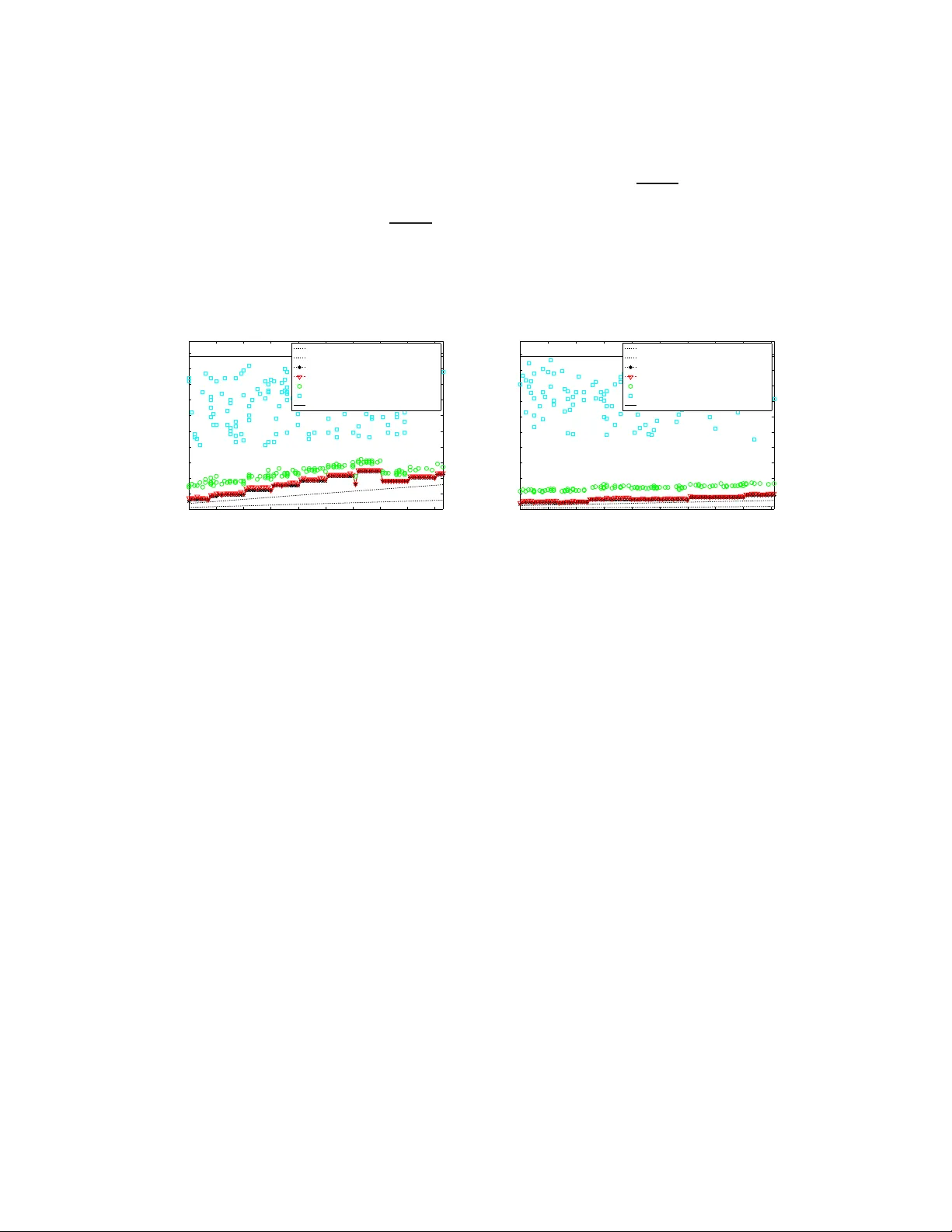
Learning Causal Graphs with Small Interventions Karthikeyan Shanmugam 1 , Murat K ocaoglu 2 , Alexandros G. Dimakis 3 , Sriram V ishwanath 4 Department of Electrical and Computer Engineering The Unive rsity of T exas a t Austin, USA 1 karthiksh@ utexas.edu , 2 mkocaoglu@ utexas.edu 3 dimakis@au stin.utexa s.edu , 4 sriram@ece .utexas.ed u November 3, 2015 Abstract W e co nsider the problem of learning causal networks with interv entions, when each interv ention is limited in size under Pearl’ s Structural Equa tion Mode l with independe nt errors (SEM-IE). The objecti v e is to minimize the n umber of experiments to discover the causal d irections of all the edges i n a ca usal graph. Previo us work has focused on the use of separating systems for complete g raphs for this task . W e pro ve that any determin istic adap tiv e alg orithm needs to be a separating system in order to learn complete graphs in the worst case. In addition, we p resent a nov el separating system con struction, whose size is close to optimal a nd is arguab ly simpler than pre viou s work in combinatorics. W e also de velo p a nove l information t heoretic lo wer bound on the number of interventions that applies in full generality , including for randomize d adaptive learning algo rithms. For g eneral chordal graphs, we deri ve wo rst case lower bou nds on the number of interventions. Building on observ ations abou t induced trees, we gi v e a ne w deterministic adapti v e algorithm t o l earn directions on an y cho rdal skeleton completely . In the worst case, our achie v able scheme is an α -approximation algorithm where α is t he independe nce number of the graph. W e also sho w that there exist graph classes for which the sufficient numbe r of experimen ts is close to the lo wer bound. In t he other extreme, there are graph classes for which the required number of e xperiments is multiplicativ ely α aw ay from our lo wer bound. In simu lations, our a lgorithm almost alway s performs v ery close t o the lowe r bo und, while the approach ba sed on separating systems for complete graphs is significantly worse for rando m chordal graphs. 1 Introd uction Causality is a fundam ental con cept in sciences and p hilosophy . The mathematical formulation of a theo ry of cau sality in a proba bilistic sense has received sign ificant atten tion recently (e. g. [2, 6, 8 , 9, 14]). A formulatio n a dvocated by Pearl considers the structural equation models : In this framework, X is a cause of Y , if Y can be written as f ( X, E ) , for some deter ministic functio n f and some latent rando m variable E . Gi ven two causally related variables X and Y , it is n ot p ossible to infer wh ether X ca uses Y or Y causes X fro m ran dom samp les, unless certain assumption s are m ade on th e distribution o f E an d/or on f [7, 1 5]. For m ore than two rando m variables, dir ected acyclic graphs (D A Gs) are the most comm on tool used fo r represen ting causal relation s. For a given D A G D = ( V , E ) , the dir ected edge ( X , Y ) ∈ E shows tha t X is a ca use of Y . If we make no assumption s o n the data generating p rocess, the standard way of inf erring the causal d irections is by performin g experiments, th e so-called interven tions . An intervention requires mo difying the process that generates the r andom variables: Th e experimen ter has to en force values on the r andom variables. Th is pro cess is different than condition ing as explain ed in detail in [14]. The natural pro blem to consider is theref ore minimizing the nu mber of in terventions req uired to learn a causal D A G. Hauser et al. [ 6] developed an ef ficient algorithm that minimizes this numb er in the worst c ase. Th e alg orithm i s based on optimal colorin g of chor dal graphs and r equires at m ost log χ interventio ns to learn any ca usal graph wh ere χ is the chromatic number of the chordal sk eleton. Howe ver , one im portant open p roblem appear s wh en one also considers the size of the used inter ventions: Each intervention is an experimen t wher e the scientist must force a set of variables to take ran dom values. Unfortunately , the interventio ns obtained in [6] can in volve up to n/ 2 variables. The simultan eous enf orcing o f many variables can 1 be q uite challen ging in many ap plications: for example in b iology , som e variables m ay not be enfor ceable at all or may require complicate d g enomic interventions for each parameter . In this pap er , we c onsider the pr oblem of lea rning a causal grap h wh en interven tion sizes a re bou nded b y some parameter k . T he first work we are aware of f or th is p roblem is by E berhard t et al. [2 ], where he provided an achiev able scheme. Further more [3] shows that the set of interventions to f ully identify a causal DA G mu st satisfy a specific set of combinato rial condition s called a sepa rating system 1 , when the intervention size is n ot co nstrained or is 1. In [9], with the assum ption that the same hold s true for any inter vention size, Hyttin en et al. draw connectio ns between causality and known separa ting system con structions. One open pro blem is: If the learning algor ithm is ad aptive after each intervention, is a sep arating system still needed or can o ne d o b etter? I t was believed that adap ti vity do es not help in the worst case [3] and that one still needs a separating system. Our Contr ib utions: W e o btain several novel r esults f or learnin g cau sal grap hs with inter ventions b ounde d by size k . The pr oblem can b e separated f or the sp ecial case where the un derlying und irected graph (the skeleton) is the complete graph and the more general case where the under lying u ndirected graph is chordal. 1. For complete graph skeletons, we show th at any adaptiv e d eterministic algorithm need s a ( n, k ) sepa rating system. This im plies that lo wer bound s for separating systems also hold for ad aptive algorith ms and resolves th e pr eviously mentioned open prob lem. 2. W e pr esent a novel comb inatorial co nstruction of a separatin g system that is close to th e pr evious lower bou nd. This simple construc tion may be of more general interest in combin atorics. 3. Recently [8] showed that randomized adaptive algorithms need on ly log lo g n interventions with h igh prob ability for the unbo unded case. W e extend this re sult and show that O n k log log k interventions of size bo unded by k suffice with high probab ility . 4. W e present a more general info rmation theore tic lower bo und of n 2 k to c apture the p erform ance of such randomized algorithm s. 5. W e exten d th e lo wer bound for adapti ve algo rithms for g eneral chordal graphs. W e show that over all orientations, the num ber of experim ents from a ( χ ( G ) , k ) separating system is ne eded where χ ( G ) is the chrom atic number of the skeleton graph. 6. W e show two extremal classes of gr aphs. For one of them , the interventions thro ugh ( χ, k ) separating system is sufficient. For the other class, we need α ( χ − 1) 2 k ≈ n 2 k experiments in the worst case. 7. W e exploit the structural prop erties of c hordal graphs to design a n ew deter ministic a daptive algor ithm that u ses the idea of separating systems together with adap tability to Meek ru les. W e simulate our new algor ithm and empirically observe that it perf orms q uite close to the ( χ, k ) separa ting system. Our algo rithm requires much fewer interventions com pared to ( n, k ) separating systems. 2 Backgrou nd and T erminology 2.1 Essential graphs A cau sal DA G D = ( V , E ) is a directed acyclic graph wh ere V = { x 1 , x 2 . . . x n } is a set of random variables and ( x , y ) ∈ E is a directed edge if and only if x is a direct cause of y . W e adop t Pearl’ s structural equ ation model with inde penden t err o rs (SEM-IE ) in this work (see [14] f or mor e details). V ariables in S ⊆ V cause x i , if x i = f ( { x j } j ∈ S , e y ) wh ere e y is a rando m variable independ ent of all other variables. The causal relations of D imp ly a set of co nditional indepen dence (CI) r elations b etween the variables. A co ndi- tional independen ce relation is of the following for m: Given Z , the set X and the set Y are conditio nally ind epende nt for some disjoin t subsets of variables X , Y , Z . Due to this, cau sal D A Gs a re also called cau sal Bayesian networks . A set V of v ariables is Bayesian with respect to a DA G D if the joint probability distrib ution of V ca n be f actorized as a produ ct o f marginals of e very variable conditioned on its parents. All th e CI relations that are learned statistically throu gh ob servations can also be inferred from the Bay esian network usin g a graphical criterio n called t he d-separation [16] as suming th at th e d istribution is f aithful to the grap h 2 . T wo causal D A Gs are said to be Marko v equivalent if they encod e the s ame set of CIs. T wo causal D A Gs are Markov 1 A separa ting s ystem is a 0 - 1 matrix with n distinc t columns and each ro w has at most k ones. 2 Gi ven Bayesian network, any CI rel ation implied by d-sepa ration holds true . All the CIs impl ied by the dist ribu tion can be found usin g d- separat ion if the distrib ution is faithfu l. Fai thfulne ss is a widel y accepte d assumption, since it is kno wn that only a measure zero set of dist ribut ions are not fai thful [13]. 2 equiv alent if an d only if th ey h av e the same skeleton 3 and the same imm oralities 4 . The class of causal DA Gs that encode the s ame set of CIs is called the Ma rkov equ ivalence cla ss . W e denote the Markov equivalence c lass of a D A G D by [ D ] . T he graph un ion 5 of all DA Gs in [ D ] is called the essential graph of D . It is deno ted E ( D ) . E ( D ) is always a chain graph with chordal 6 chain compo nents 7 [1]. The d -separ ation criterion can be used to identify the skeleton an d all th e imm oralities of th e u nderlyin g causal D A G [ 16]. Additio nal edges can be identified using the fact that the underlying D A G is acyclic and there are no more immoralities. Meek derived 3 local rule s ( Meek rules ), introdu ced in [17], to b e recur si vely applied to identify every such add itional edge (see T heorem 3 of [12]). Th e repeated app lication of Meek rules on this par tially directed gr aph with identified immoralities until they can no longer be used yields the essential graph. 2.2 Interv entions and Active Lear ning Giv en a set of variables V = { x 1 , ..., x n } , a n intervention on a set S ⊂ X of the variables is an experiment where the p erform er forc es e ach variable s ∈ S to take th e value of ano ther indepe ndent (f rom o ther variables) variable u , i.e., s = u . This op eration, and how it affects the joint distribution is formalized by the do o perator by Pearl [ 14]. An intervention modifies the causal DA G D as follows: The po st intervention D A G D { S } is obtain ed by removing th e connectio ns of node s in S to their p arents. The size of an intervention S is the n umber of in tervened variables, i.e., | S | . Let S c denote the complemen t of the set S . CI-based lear ning algorith ms can b e app lied to D { S } to identif y the set of removed edges, i.e. parents of S [ 16], and the remaining adjacent edges in the original skeleton are declared to be the children. Hence, (R0) The orientations of the edges of the cut between S and S c in the origin al D AG D can be inferr ed. Then, 4 lo cal Meek r ules (introd uced in [1 7]) ar e re peatedly a pplied to the orig inal DA G D with the new d irec- tions lea rnt fro m th e cu t to learn more till no more directed e dges can be identified. Fu rther ap plication of CI-based algorithm s on D will rev eal no more information . Th e Meek rules are gi ven belo w: (R1) ( a − b ) is oriented as ( a → b ) if ∃ c s.t. ( c → a ) and ( c, b ) / ∈ E . (R2) ( a − b ) is oriented as ( a → b ) if ∃ c s.t. ( a → c ) and ( c → b ) . (R3) ( a − b ) is oriented as ( a → b ) if ∃ c, d s.t. ( a − c ) , ( a − d ) , ( c → b ) , ( d → b ) a nd ( c, d ) / ∈ E . (R4) ( a − c ) is oriented as ( a → c ) if ∃ b, d s.t. ( b → c ) , ( a − d ) , ( a − b ) , ( d → b ) a nd ( c, d ) / ∈ E . The concep ts of essential grap hs and Markov equiv alence classes are extended in [4] to in corpor ate the role of inter ven- tions: Let I = { I 1 , I 2 , ..., I m } , be a set of intervention s and let the above process be follo wed after each intervention. Intervention al Markov equivalence class ( I eq uiv alence) of a DA G is the set of DA Gs that r epresent the same set of probab ility distributions o btained when the above p rocess is applied after every intervention in I . It is d enoted by [ D ] I . Similar to the obser vational c ase, I essential graph o f a DA G D is th e gr aph union of all D A Gs in the same I equiv alence class; it is denoted by E I ( D ) . W e have th e following sequence: D → CI learning → Mee k rules → E ( D ) → I 1 a → learn b y R0 b → Meek rules → E { I 1 } ( D ) → I 2 . . . → E { I 1 ,I 2 } ( D ) . . . (1) Therefo re, after a set of interventions I has b een perform ed, the essential gr aph E I ( D ) is a graph with some oriented edges that captures all the causal re lations we hav e d iscovered so far, u sing I . Before any interventions happen ed E ( D ) cap tures th e in itially known cau sal direction s. It is known that E I ( D ) is a chain g raph with cho rdal chain co mponen ts. Theref ore when all the dir ected edg es are r emoved, th e gr aph becom es a set of disjoint chor dal graphs. 2.3 Pr oblem Definition W e are interested in the f ollowing qu estion: 3 Skel eton of a DA G is the undirected graph obtained when directed edges are con ve rted to undirect ed edges. 4 An induc ed subgraph on X , Y , Z is an immorality if X and Y are disconne cted, X → Z and Z ← Y . 5 Graph union of two D A Gs D 1 = ( V , E 1 ) and D 2 = ( V , E 2 ) with the same skeleton is a partially directed graph D = ( V , E ) , w here ( v a , v b ) ∈ E is undir ected if the edges ( v a , v b ) in E 1 and E 2 hav e diffe rent directions, and directed as v a → v b if the edges ( v a , v b ) in E 1 and E 2 are both direc ted as v a → v b . 6 An undire cted graph is chordal if it has no induce d cycle of length greater than 3 . 7 This means tha t E ( D ) can be decomposed as a sequence of undire cted chordal graphs G 1 , G 2 . . . G m (chain components) such that ther e is a direct ed edge from a ve rtex in G i to a verte x in G j only if i < j 3 Problem 1 . Given that all intervention s in I ar e of size at mo st k < n/ 2 varia bles, i.e., fo r each intervention I , | I | ≤ k, ∀ I ∈ I , min imize the numb er of interven tions |I | such tha t the pa rtially dir ected g raph with all d ir ections learned so far E I ( D ) = D . The qu estion is the design of an algor ithm that co mputes the small set of interven tions I giv en E ( D ) . No te, of course, th at the u nknown directions of th e edges D ar e no t av ailable to the alg orithm. One can view the design of I as an active l earning pr ocess to find D from the essential grap h E ( D ) . E ( D ) is a chain gr aph with undirected chor dal compon ents and it is known that interventions on one chain components do n ot affect th e discovery proce ss of directed edges in the other compo nents [5]. So we will assume that E ( D ) is undirected and a ch ordal gr aph to start with. Our notion of alg orithm d oes not con sider the time complexity (of statistical alg orithms in volved) of steps a and b in (1). Given m inter ventions, we o nly consider efficiently com puting I m +1 using (p ossibly) the graph E { I 1 ,...I m } . W e consider the following three classes of algorithms: 1. Non-a daptive algorithm: The cho ice of I is fixed prior to the discovery p rocess. 2. Ada ptive algorithm: At every s tep m , the choice of I m +1 is a determin istic f unction of E { I 1 ,...I m } ( D ) . 3. Ran domized adaptive algorithm: At every s tep m , the choice of I m +1 is a rando m f unction of E { I 1 ,...I m } ( D ) . The prob lem is different for co mplete grap hs versus more gen eral chorda l g raphs since r ule R 1 become s ap plicable when the grap h is no t complete. Th us we g iv e a sepa rate tre atment for each case. First, we provide algo rithms for all thre e cases for lea rning the directio ns of co mplete graph s E ( D ) = K n (undir ected complete grap h) on n vertices. Then, we genera lize to ch ordal grap h skeletons and p rovide a novel adaptive algorithm with up per and lower bou nds on its perfor mance. The missing proof s of the results tha t follow ca n be found in the Appendix. 3 Complete Graphs In this section , we consider the case where the skeleton we start with, i.e. E ( D ) , is an undire cted co mplete graph (denoted K n ). It is k nown that at any stage in (1) starting f rom E ( D ) , ru les R 1 , R 3 and R 4 do not ap ply . Fu rther, the underly ing D A G D is a directed cliq ue. The dire cted clique is ch aracterized by an or dering σ o n [1 : n ] such that, in the sub graph induc ed by σ ( i ) , σ ( i + 1) . . . σ ( n ) , σ ( i ) has no incomin g edges. L et D be den oted by ~ K n ( σ ) fo r som e orderin g σ . Let [1 : n ] deno te the set { 1 , 2 . . . n } . W e need the following results on a separatin g system fo r o ur first result regarding adaptive and no n-adap ti ve algorithm s for a complete graph . 3.1 Separating System Definition 1. [10, 18] A n ( n, k ) -sep arating system on an n element set [1 : n ] is a set of subsets S = { S 1 , S 2 . . . S m } such that | S i | ≤ k an d for every pa ir i, j ther e is a su bset S ∈ S such that either i ∈ S, j / ∈ S or j ∈ S, i / ∈ S . If a pair i, j satisfies the ab ove condition with respect to S , th en S is said to separate the pair i, j . Her e , we consider th e case when k < n/ 2 In [10], Katon a g av e an ( n, k ) -separ ating system tog ether with a lower boun d on |S | . In [1 8], W egener gave a simpler argument for the lower bound and also p rovided a tighter upp er bound than the one in [10]. In th is work , we giv e a different co nstruction below wh ere the separ ating system size is at most ⌈ log ⌈ n/k ⌉ n ⌉ larger than the construction of W egener . Howev er , our constru ction has a s impler description . Lemma 1. There is a labeling pr oce dur e that pr od uces distinct ℓ length labels for all elements in [1 : n ] using letters fr om the integ er alph abet { 0 , 1 . . . a } wher e ℓ = ⌈ log a n ⌉ . Furthe r , in every d igit (o r position), any inte ger letter is used at most ⌈ n/a ⌉ times. Once we hav e a set of n string labels as in Lemma 1, our separating system constructio n is straightforward. Theorem 1. Consider an alphabet A = [0 : ⌈ n k ⌉ ] o f size ⌈ n k ⌉ + 1 wher e k < n / 2 . Lab el every elemen t of an n elemen t set u sing a distinct string o f letters fr om A of length ℓ = ⌈ log ⌈ n k ⌉ n ⌉ using the pr ocedure in Lemma 1 with a = ⌈ n k ⌉ . F or every 1 ≤ i ≤ ℓ and 1 ≤ j ≤ ⌈ n k ⌉ , choo se the subset S i,j of vertices who se string’s i -th letter is j . Th e set of all such subsets S = { S i,j } is a k -sepa rating system on n elements and |S | ≤ ( ⌈ n k ⌉ ) ⌈ log ⌈ n k ⌉ n ⌉ . 4 3.2 Adaptiv e algorithms: Equivalence to a Separating System Consider any non -adaptive alg orithm that de signs a set of inter ventions I , eac h of size at mo st k , to discover ~ K n ( σ ) . I has to b e a sep arating system in th e worst case over all σ . This is alr eady known. Now , we prove the necessity of a separating system for deterministic adaptive algo rithms in the w orst case. Theorem 2. Let there be an ada ptive d eterministic algorithm A that d esigns the set of in terventions I such that th e final graph learnt E I ( D ) = ~ K n ( σ ) for any gr ound truth ordering σ starting fr om the in itial skeleton E ( D ) = K n . Then, ther e e xists a σ such that A design s an I which is a separating system. The theorem above is ind ependen t of the individual intervention s izes. Th erefore, we ha ve th e following th eorem, which is a direct corollary of Theor em 2 : Theorem 3. In the w orst case over σ , any adaptive or a n on-a daptive deterministic algorithm o n th e DA G ~ K n ( σ ) ha s to be such that n k log ne k n ≤ |I | . There is a feasible I with |I | ≤ ⌈ ( n k ⌉ − 1) ⌈ log ⌈ n k ⌉ n ⌉ Pr o of. By Theor em 2, we need a separating sy stem in the worst case and the lower and upp er boun ds are from [10, 1 8]. 3.3 Randomized Adaptive Algorithms In this section, we show that that total number of v ariable accesses to fully identify the complete causal DA G is Ω( n ) . Theorem 4. T o fully id entify a co mplete causa l DA G ~ K n ( σ ) on n variables u sing size- k in terventions, n 2 k interventions ar e necessary . Also , the total number of variables accessed is at least n 2 . The lower bound in The orem 4 is informatio n theore tic. W e n ow give a randomized algorithm that require s O ( n k log log k ) experiments in e xpectation. W e provide a straightforward ge neralization of [8], wh ere the authors g ave a rando mized alg orithm for unboun ded in tervention size. Theorem 5. Let E ( D ) be K n and the e xperiment size k = n r for some 0 < r < 1 . Then there exists a ran- domized adaptive algorithm which designs a n I such that E I ( D ) = D with pr obability p olynomia l in n , and |I | = O ( n k log log ( k )) in expectation. 4 General Chordal Graphs In this section , we turn to intervention s o n a general DA G G . After the i nitial stages in (1), E ( G ) is a chain graph with chorda l chain com ponen ts. There are no f urther immo ralities thro ugho ut th e gr aph. In this work , we fo cus on o ne o f the ch ordal chain com ponen ts. Thus th e DA G D we work o n is assumed to be a directe d graph with no im moralities and whose skeleton E ( D ) is chor dal. W e are interested in recovering D from E ( D ) using interventions of size at most k fo llowing (1). 4.1 Bounds f or Chordal skeletons W e provide a l ower bou nd for both adaptive and non-ad aptive determin istic schem es for a cho rdal s keleton E ( D ) . Le t χ ( E ( D )) be the colo ring n umber of the given cho rdal graph . Since, chor dal g raphs are perfe ct, it is the sam e as the clique numb er . Theorem 6. Given a chor dal E ( D ) , in the worst ca se over all DA Gs D (which ha s skeleton E ( D ) an d n o immoralities), if every intervention is o f size at most k , then |I | ≥ χ ( E ( D )) k log χ ( E ( D )) e k χ ( E ( D )) fo r a ny a daptive a nd no n-ada ptive algorithm with E I ( D ) = D . Upper bound : Clearly , th e separ ating system based algo rithm of Section 3 can be ap plied to the vertices in the chorda l skeleton E ( D ) and it is po ssible to find all the directions. Thus, |I | ≤ n k log ⌈ n k ⌉ n ≤ α ( E ( D )) χ ( E ( D )) k log ⌈ n k ⌉ n . This with the lower bo und im plies an α app roximation a lgorithm (since log ⌈ n k ⌉ n ≤ log χ ( E ( D )) e k χ ( E ( D )) , u nder a mild assumption χ ( E ( D )) ≤ n e ). Remark: The separ ating system on n no des g iv es an α appr oximation . Howe ver , the new algorithm in Section 4.3 exploits c hordality and p erform s m uch better empirica lly . It is possible to show th at our heu ristic also has an α approx imation g uarantee b ut we skip that. 5 4.2 T wo extr eme counter examples W e provide two classes of chor dal skeletons G : One f or which th e numb er of interven tions close to the lower b ound is sufficient and the other for which the number of intervention s need ed is very close to the upper bound . Theorem 7. Ther e exists chordal skeletons such that for any a lgorithm with intervention size constraint k , the numb er of inte rventions |I | r equir ed is at least α ( χ − 1) 2 k wher e α a nd χ are the ind ependen ce number an d chr o matic numb ers r espectively . There e xists c hor dal gr aph classes such that |I | = ⌈ χ k ⌉⌈ log ⌈ χ k ⌉ χ ⌉ is sufficient. 4.3 An Impr ov ed Algorithm using Meek Rules In this section, we design an adaptive d eterministic algorithm that anticipates Meek rule R 1 usage along with the idea of a separatin g system. W e evaluate this experimentally o n rand om chorda l graph s. First, we m ake a few ob serva- tions on le arning c onnected directed trees T fr om the skeleton E ( T ) (und irected tree s are ch ordal) that d o not have immoralities using Meek rule R 1 where e very intervention is of size k = 1 . Becau se the t ree has no c ycle, Meek rules R 2 -R 4 d o not apply . Lemma 2. Every node in a dir ected tr ee with n o immoralities h as a t most one incoming ed ge. Ther e is a r oot n ode with no in coming e dges an d intervening on that no de alone iden tifies the whole tr ee using repeated a pplication o f rule R 1 . Lemma 3. If every intervention in I is of size a t most 1 , learning all dir ection s on a d ir ected tr ee T with no immoral- ities can be do ne adaptively with at most |I | ≤ O (log 2 n ) where n is the numbe r of vertices in th e tr ee. The algorithm runs in time poly ( n ) . Lemma 4. Given an y c hor dal gr aph and a valid coloring, the gr aph induced by any two color classes is a for est. In th e n ext section , we combin e the above sing le in tervention adap tiv e algorithm on d irected tr ees which u ses Meek rules, with that of the non-ada ptiv e separating system app roach. 4.3.1 Description of the algorit hm The ke y m otiv ation be hind th e algorithm is that, a pair of color class es is a forest (Lemma 4). Ch oosing the r ight node to in tervene leaves o nly a small subtr ee unlear nt as in the proo f o f Le mma 3. In su bsequent steps, suitable node s in the remaining subtrees could be chosen until all edges are learnt. W e give a b rief description of the algorithm below . Let G d enote the initial undirected chorda l skeleton E ( D ) a nd let χ be its co loring numb er . Consider a ( χ, k ) separating system S = { S i } . T o intervene on the actu al graph , an interventio n set I i correspo nding to S i is c hosen. W e would like to intervene on a node of color c ∈ S i . Consider a nod e v of color c . No w , we attach a scor e P ( v , c ) as follows. For any co lor c ′ / ∈ S i , consider the induced forest F ( c, c ′ ) on the colo r classes c and c ′ in G . Conside r th e tree T ( v, c, c ′ ) containing nod e v in F . L et d ( v ) be the degree of v in T . Let T 1 , T 2 , . . . T d ( v ) be the resulting disjoint trees after nod e v is removed from T . If v is intervene d on, acco rding to th e proo f of Lemm a 3: a) All edge d irections in a ll trees T i except on e o f them would be learnt when applyin g Meek R ules and rule R 0 . b) All the direction s from v to all its neighbo rs would be fo und. The score is taken to be th e total nu mber o f edge dir ections g uaranteed to b e learnt in th e worst case. The refore, the score P ( v ) is: P ( v ) = P c ′ : | c,c ′ T | =1 | T ( c, c ′ ) | − max 1 ≤ j ≤ d ( v ) | T j | . The node with the highest score among the color class c is used for the inte rvention I i . After intervening o n I i , all the edges wh ose directions a re known thro ugh Meek Rules (by r epeated app lication till n othing mo re can be learnt) and R 0 are deleted fro m G . Once S is p rocessed, we recolor the spar ser gr aph G . W e find a new S with th e new chrom atic num ber on G an d th e above proc edure is repeated. Th e exact h ybrid algorithm is described in Algorithm 1. Theorem 8. Given an un dir ected c horal skeleton G of an u nderlying dir ected graph wi th no immoralities, Algorithm 1 en ds in fin ite time an d it r eturns the corr ect underlying directed g raph. The algo rithm has run time complexity polynomia l in n . 6 Algorithm 1 Hybrid Algorithm using Meek rules with separating system 1: Input: Cho rdal Graph skeleton G = ( V , E ) with no Immoralities. 2: Initialize ~ G ( V , E d = ∅ ) with n nod es and no directed edges. Initialize time t = 1 . 3: while E 6 = ∅ do 4: Color the chordal graph G with χ colors. ⊲ Stand ard algorithms exist to do it in linear time 5: Initialize color set C = { 1 , 2 . . . χ } . Form a ( χ, min ( k , ⌈ χ/ 2 ⌉ )) separating system S such that | S | ≤ k , ∀ S ∈ S . 6: for i = 1 until |S | do 7: Initialize Intervention I t = ∅ . 8: for c ∈ S i and e very node v in color class c do 9: Consider F ( c, c ′ ) , T ( c, c ′ , v ) and { T j } d ( i ) 1 (as per definitions in Sec. 4 .3.1). 10: Compute: P ( v , c ) = P c ′ ∈C T S c i | T ( c, c ′ , v ) | − max 1 ≤ j ≤ d ( i ) | T j | . 11: end for 12: if k ≤ χ/ 2 then 13: I t = I t S c ∈ S i { ar gmax v : P ( v ,c ) 6 =0 P ( v , c ) } . 14: else 15: I t = I t ∪ c ∈ S i { First k ⌈ χ/ 2 ⌉ no des v with largest no nzero P ( v , c ) } . 16: end if 17: t = t + 1 18: Apply R 0 an d Meek ru les using E d and E after intervention I t . Ad d newly learn t directed edg es to E d and delete them from E . 19: end for 20: Remove all nod es which hav e de gree 0 in G. 21: end while 22: return ~ G . 5 Simulations W e simulate our n ew heuristic, namely Algo rithm 1, on randomly generate d chordal gr aphs and co mpare it with a naive algorithm that follows the interventio n sets giv en by our ( n, k ) separating system as in Theor em 1. Both algorithm s apply R 0 and Meek rules after each intervention accordin g to (1). W e p lot the fo llowing lo wer bound s: a ) Information Theoretic LB o f χ 2 k b) Max. Clique Sep . Sys. Entr opic LB which is th e chrom atic numb er based lower bound o f T heorem 6. Mo reover , we use two known ( χ, k ) sepa rating system construction s for the max imum cliq ue size as “refere nces”: Th e b est kno wn ( χ, k ) separating system is shown b y th e lab el Ma x. Cliqu e Se p. Sys. Achievable LB and o ur new simpler separ ating system con struction (T heorem 1) is shown by Ou r Construction Clique Sep. Sys. LB . As an u pper bou nd, we use the size of the best known ( n, k ) separating system (witho ut any Meek rules) and is denoted Separating System UB . Rando m generation of chordal g raphs: Start with a random or dering σ on the vertices. Consider every vertex starting from σ ( n ) . For each vertex i , ( j, i ) ∈ E with proba bility inversely propo rtional to σ ( i ) for every j ∈ S i where S i = { v : σ − 1 ( v ) < σ − 1 ( i ) } . The propo rtionality constant is ch anged to adjust sparsity o f the graph. After all such j are consid ered, make S i ∩ ne ( i ) a clique b y addin g edges respecting the o rdering σ , whe re ne ( i ) is the neig hborh ood of i . T he resultant graph is a DA G and the corresponding skeleton is chordal. Also, σ is a perfect elimination ordering. Results: W e are in terested in co mparin g our algorithm and the naive one which dep ends on the ( n, k ) sepa rating system to the size o f the ( χ, k ) separating system. T he size of the ( χ, k ) separating system is roughly ˜ O ( χ/ k ) . Consider values around χ = 100 on the x-axis for the plots with n = 1000 , k = 10 and n = 200 0 , k = 10 . Note that, our algor ithm perf orms very clo se to the size of the ( χ, k ) separ ating system, i.e. ˜ O ( χ/k ) . In fact, it is always < 40 in b oth cases while th e average perf ormance of naive algorithm go es fro m 130 (close to n/k = 100 ) to 260 (close to n/k = 200 ). The result poin ts to this: For rand om chord al graph s, the structu red tree search allows us to learn th e edges in a n umber o f experime nts quite clo se to the lower boun d based only on the max imum cliqu e size and no t n . The plots for ( n, k ) = (500 , 10) and ( n, k ) = (20 00 , 20 ) are given in Ap pendix. 7 20 40 60 80 100 120 0 20 40 60 80 100 120 140 160 180 200 Chromatic Number, χ Number of Experiments Information Theoretic LB Max. Clique Sep. Sys. Entropic LB Max. Clique Sep. Sys. Achievable LB Our Construction Clique Sep. Sys. LB Our Heuristic Algorithm Naive (n,k) Sep. Sys. based Algorithm Seperating System UB (a) n = 1000 , k = 10 20 40 60 80 100 120 0 50 100 150 200 250 300 350 400 Chromatic Number, χ Number of Experiments Information Theoretic LB Max. Clique Sep. Sys. Entropic LB Max. Clique Sep. Sys. Achievable LB Our Construction Clique Sep. Sys. LB Our Heuristic Algorithm Naive (n,k) Sep. Sys. based Algorithm Seperating System UB (b) n = 20 00 , k = 10 Figure 1: n : no. of vertices, k : Intervention size b ound . The nu mber of e xperimen ts is c ompared betwe en our heuristic an d the naive algorithm b ased on the ( n, k ) sep arating system on r andom ch ordal grap hs. The r ed mar kers represent t he sizes o f ( χ, k ) sep arating system . Green circle markers and the cyan square markers fo r th e same χ value correspo nd to the number o f exper iments r equired by our h euristic and the alg orithm b ased on an ( n, k ) separating system(Theo rem 1 ), respec ti vely , on the same set of chor dal grap hs. Note that, w hen n = 1 000 and n = 2000 , the naive algorithm requ ires on average about 13 0 and 26 0 (close to n/k ) experim ents respectively , wh ile o ur algorith m requires at most ∼ 40 (orderwise close to χ/k = 10 ) when χ = 1 00 . 6 Conclusions W e have considered the pr oblem o f ad aptiv ely designin g interventio ns of boun ded size to learn a ca usal graph und er Pearl’ s SEM-IE mo del. W e prop osed lower and upper bounds for the n umber of interventions needed in th e worst case for various classes of algorithm s, when the causal graph skeleton is co mplete. W e developed lo wer and upper boun ds on the m inimum number of i nterventions req uired in the worst case for g eneral grap hs. W e chara cterized two extrem al graph classes such that the minimum number of interventions in one class is close to the lower bound and in the other class it is clo se to the upp er bou nd. In the case o f ch ordal skeleton s, we p roposed an alg orithm that co mbines ideas for the complete graphs with the ones when the skeleton is a for est via ap plication o f Meek rules. Empirically , on random ly generated chordal graph s, our algorithm per forms close to the lower bou nd and it o utperfo rms the previous state o f the art. Possible futu re work inc ludes obtain ing a tigh ter lower bound f or chor dal grap hs that would p ossibly establish a tighter approxim ation gu arantee for our algorithm. Acknowledgments Authors acknowledge th e su pport from g rants: NSF CCF 134 4179, 1344 364, 14072 78, 1 4225 49 and a ARO YIP award (W911NF-14-1- 0258). W e also thank Frederick Eberh ardt for h elpful discussions. 8 Refer ences [1] Steen A. Andersson, David Mad igan, and Mich ael D. Perlman. A characterization of markov equ iv alence classes for acyclic digraphs. The An nals of Statistics , 25(2):50 5–541 , 19 97. [2] Frederich Eberh ardt, Clark Glymour, and Richard Schein es. On the nu mber of experiments suffi cient and in th e worst case necessary to identify all causal relations amo ng n variables. In Pr oceed ings of the 2 1st C onfer ence on Uncertainty in Artificial Intelligence (U A I) , pages 178–18 4. [3] Frederick Eberh ardt. Causatio n and Intervention (Ph.D. Thesis) , 2007. [4] Alain Hauser and Peter B ¨ uhlmann . Characterization and greedy lear ning of interventional m arkov equ iv alence classes of directed acyclic graphs. Journal of Machine Learning Resear ch , 1 3(1):24 09–2 464, 2 012. [5] Alain Hauser and Peter B ¨ uhlmann. T wo op timal strategies for activ e learning of causal networks from interven- tional data. In Pr o ceedings of Sixth Eur opean W o rkshop on Pr obabilistic Gr aphical Models , 2012. [6] Alain Hauser and Peter B ¨ uhlmann . T wo optimal strategies f or activ e learn ing of cau sal mo dels f rom interven- tional data. Internation al Journal o f Appr oximate Reasoning , 55(4):926–9 39, 2014. [7] Patrik O Hoyer, Do minik Janzin g, Jo ris M ooij, Jonas Peters, and Bernhard Sch ¨ olkopf. Nonlinear causal discovery with additive noise mode ls. In Pr oceeding s of NIPS 2008 , 2008. [8] Huining Hu, Z hentao Li, and Ad rian V etta. Rando mized experimental d esign for cau sal grap h d iscovery . In Pr o ceedings of NIPS 2014 , Montreal, CA, December 2014. [9] Antti Hy ttinen, Frederick Eberhar dt, a nd Patrik Hoyer . Experim ent selectio n for causal d iscovery . Journal of Machine Learning Resear ch , 14:304 1–307 1, 2013. [10] Gyula Katona. On separating systems of a finite set. Journal of Combinatorial Theory , 1(2):174–19 4, 1966 . [11] Richard J Lipton and Rob ert Endr e T arjan. A separator theo rem for p lanar gr aphs. SI AM Journal on Ap plied Mathematics , 36(2):1 77–18 9, 1 979. [12] Christoph er Meek. Causal inferen ce and causal explanation with backgr ound knowledge. In Pr oceedings of the eleventh international confer e nce on uncertainty in artificial intelligence , 1995. [13] Christoph er Me ek. Strong completen ess and faithfu lness in bay esian networks. In Pr oceedings o f the eleventh internationa l co nfer ence on uncertainty in artificial intelligence , 1995. [14] Judea Pearl. Causality: Mo dels, Reasoning and Infer ence . Cambrid ge Uni versity P ress, 2009 . [15] S Shimizu, P . O Hoyer , A Hyvarinen, and A. J Kerminen. A lin ear n on-gau ssian a cyclic mode l for causal discovery . Journal of Machine Lea rning Resear ch , 7:2 003–2 030, 20 06. [16] Peter Spirtes, Clark Glymour, and Richard Scheines. Causation, Pr ediction, and S ear ch . A Bradford Book, 2001. [17] Tho mas V erm a and Jud ea Pearl. An algorithm for deciding if a set of ob served in depend encies h as a causal explanation. In Pr oceeding s of the Eighth intern ational con fer ence o n un certainty in artificial intelligence , 1 992. [18] Ing o W egener . On separating systems who se elemen ts are sets of at m ost k elem ents. Discr ete Ma thematics , 28(2) :219–2 22, 1979. 9 A pp endix 6.1 Pr oof of Lemma 1 W e describ e a string labeling procedure as follows to label elemen ts of the set [1 : n ] . String Lab elling: L et a > 1 be a positive integer . Le t x be the integer such that a x < n ≤ a x +1 . x + 1 = ⌈ log a n ⌉ . Every elemen t j ∈ [1 : n ] is given a label L ( j ) which is a string of integer s of len gth x + 1 dr awn from th e alph abet { 0 , 1 , 2 . . . a } o f size a + 1 . Let n = p d a d + r d and n = p d − 1 a d − 1 + r d − 1 for some in tegers p d , p d − 1 , r d , r d − 1 , where r d < a d and r d − 1 < a d − 1 . Now , we descr ibe the sequ ence o f the d -th dig it acro ss th e string labels of all eleme nts from 1 to n : 1. Repeat 0 a d − 1 times, repeat the next integer 1 a d − 1 times and so on circularly 8 from { 0 , 1 . . . a − 1 } till p d a d . 2. After that, repeat 0 ⌈ r d /a ⌉ times followed by 1 ⌈ r d /a ⌉ times till we reach the n th po sition. Clearly , n -th inte ger in the sequence would not e xceed a − 1 . 3. Every integer o ccurring after the position a d − 1 p d − 1 is increased by 1 . From the thre e steps u sed to gen erate every digit, a straightfo rward calcu lation shows that e very integer letter is repeated at most ⌈ n/a ⌉ times in e very d igit i in the string. Now , we would like to prove indu ctiv ely th at the labels are distinct for all n elem ents. Let us assume the induction hypothesis: For all n < a q +1 , the labels are distinct. The base case of q = 0 is easy to see. Th en, we w ould like to show th at for a q +1 ≤ n < a q +2 , the labels are distinct. Another way of loo king a t the la beling p rocedu re is as fo llows. L et n = a q +1 p + r with r < a q +1 . Divide the label matrix L (of dimensions ( q + 2) × n ) into two parts, one L 1 consisting of the first pa q +1 columns and the other L 2 consisting of the remaining co lumns. The first q + 1 rows of L 1 is noth ing but the string labels for all number s from 0 to p a q +1 expressed in b ase a . For a ny row i ≤ ⌈ log a r ⌉ in th e or iginal matrix L o f lab els, till th e end of first pa q +1 columns, the labeling procedu re wou ld be stil l in Step 1 . After that, on e can take r to be the new s ize of the set of elements to be labelled and then restart the procedu re with this r . Therefo re we have the following key o bservation: L 2 (1 : ⌈ log a r ⌉ , :) (the ma trix with first ⌈ log a r ⌉ rows o f L 2 ) is no thing but the la bel matrix for r d istinct elements from the above lab eling procedur e. Since, r < a q +1 , by the induction h ypothesis, the co lumns are distinct. Hence, any two columns in L 2 are distinct. Suppose th e first q + 1 rows of two colum ns b and c of L 1 are id entical. The se corr espond to base a expansion o f b − 1 and c − 1 . They are separated b y at least a q +1 + 1 co lumns. But the last row of colu mns b and p in L 1 has to be distinct because according to Step 2 and Step 3 of the labeling procedur e, in the q + 2 th row , every integer is repeated at most ⌈ n/ a ⌉ ≤ a q +1 times continuously , and only once. Th erefor e, any tw o colu mns i n L 1 are distinct. The last ro w entries in L 1 are different from L 2 because of the addition in Step 3 . Therefo re, all columns of L are distinct. Hence, by induction , the result is shown. 6.2 Pr oof of Theor em 1 By Lemma 1, i th p lace ha s at most ⌈ n ⌈ n/k ⌉ ⌉ ≤ k occu rrences of sym bol j . Th erefore, | S i,j | ≤ k . Now , consider th e pair of distinct elemen ts p, q ∈ [1 : n ] . Since th ey are labelled distinctly (Lemma 1), the re is at least o ne letter i in their string labels wher e they differ . Suppose the distinct i th letters are a, b ∈ A , a 6 = b and let us say a 6 = 0 witho ut loss of generality . Th en, clearly the separation criterion is met by the subset S i,a . This proves the claim. 6.3 Pr oof of Theor em 2 W e c onstruct a worst case σ inductively . Before every step m , the adap tiv e algo rithm determin istically ch ooses I m based on E { I 1 ,I 2 ...I m − 1 } ( K n ) . Therefo re, we w ill reveal a p artial order σ ( m − 1) to satisfy the observations so far . Inductively f or every m , we will m ake sure that after I m is ch osen by the algo rithm, fu rther details abo ut σ can be revealed to form σ ( m ) such that after intervening on I 2 and then app lying R 0 , we will make sure t here is no opportunity to apply the rule R 2 . Th is would make sure that I is a sep arating system on n elem ents. Before intervention at any step m , let us ‘tag’ every vertex i using a subset C ( m − 1) i ⊆ [1 : m ] such t hat C ( m − 1) i = { p : i ∈ I p , p ≤ m − 1 } . C ( m − 1) i contains indices of all th ose inter ventions that co ntain vertex i bef ore step m . 8 Circula r m eans that afte r a − 1 is complete d, we start with 0 again. 10 Let C ( m − 1) contain distinct elements of th e multi-set { C ( m − 1) i } .W e will construct σ partially such that it s atisfies the following criterion al ways: Inductive Hypo thesis: The pa rtial or der σ ( m − 1) is such that for any two elements i, j with C i and C j , i and j ar e incompar able if C i = C j and compara ble other wise. This me ans the edges betwee n the e lements tagged with the same tag C has not been re vealed, and t hus the relev ant directed edges are not known by the algorith m. Now , we b riefly d igress to argue that if we c ould construct σ (1) , σ (2) . . . satisfying such a prop erty thr ougho ut, then clear ly all vertices m ust be tagged differently oth erwise the directions amon g the vertices th at are tagged similarly cannot be learne d b y the algor ithm. Therefo re, th e alg orithm has not succeeded in its task . If all vertices are tagged differently , then it means it is a separating system. Construction o f σ ( m ) : W e now constru ct σ ( m ) that ca n be shown to satisfy the induction h ypothesis b efore step m + 1 . Befo re step m , consider the vertices in C ∈ C ( m − 1) for any C . Let the cur rent intervention be I m chosen by the determin istic algor ithm. W e make the f ollowing changes: Modify σ ( m − 1) such th at vertices in I m T C come before ( I m ) c T C in the p artial order σ ( m ) (vertices inside either sets are still not ord ered amongst themselves) in the orderin g a nd clearly the directions between these two sets are re vealed by R 0 . By the induction hypo thesis fo r step m and with the new tag ging of vertices into C ( m ) , it is easy to see that only d irections between distinct C ′ s in the new C ( m ) have been rev ealed an d all d irections within a tag set C are not revealed and all vertices in a tag set are contig uous in the or dering so far . W e ne ed to only show that rule R 2 cannot rev eal anymore edges amongst vertices in C ∈ C ( m ) after the ne w σ ( m ) and intervention I m . Suppo se there are two v ertices i, j such that just af ter intervention I m and the modified σ ( m ) , they are tagged identically and applicatio n of R 2 reveals the direction between i and j before the next intervention. Then there h as to b e a vertex k tagged differently from i, j such that j → k and k → i are bo th known. But this im plies that j and i are com parable in σ ( m ) leading to a con tradiction. T his imp lies the hyp othesis holds for step m + 1 . Base case: Tri vially , the induc tion hypothesis ho lds for step 0 where σ (0) leav es the entire set unord ered. 6.4 Pr oof of Lemma 2 The proof is a direct obvious consequence of ac yclicity , non-existence of immoralities and the definition of rule R1. 6.5 Pr oof of Lemma 3 By Lemma 2, i t is suf ficient for an algorithm to identify th e root node of the tree. Su ppose the root node is b unkn own to th e algorith m. E very tree has a single vertex separator that par titions the tree into co mponen ts each of whic h has size at most 2 3 n [1 1]. Choose tha t vertex separato r a 1 (it can be f ound in b y removin g every nod e an d deter mining the c ompon ents left) . If it is a roo t nod e we stop h ere. Otherwise, its p arent p 1 (if it is n ot) after ap plication of rule R 0 is iden tified. Let us consider c ompon ent trees T 1 , T 2 . . . T k that result by r emoving n ode a 1 . Let T 1 contain p 1 . All directio ns in all other trees are known after repeated application of R 1 o n the origin al tree after R 0 is applied . Directions in T 1 will not be kno wn. For the next step, E ( T 1 ) is the ne w skeleton which ha s no immoralities. Again , we find the best vertex s eparator a 2 and the process continues. This pr ocedure will terminate at some step j when a j = b or there is only one node left which shou ld be b by Lemma 2. Sin ce the numbe r o f nodes reduce by about 1 / 3 at least each time, and initially it can be at most n , this proced ure term inates in at most O (log 2 n ) steps. 6.6 Pr oof of Lemma 4 The graph indu ced b y two colors classes in any graph is a bi-par tite g raph and bi-par tite g raphs d o not have odd induced cycles. Since the gr aph and any induce d subgr aph is cho rdal, it implies the in duced graph on a p air o f co lor classes does not have a cycle. Th is proves the theor em. 6.7 Pr oof of Theor em 4 Assume n is e ven for simplicity . W e d efine a family of par tial order σ ( p ) as follows: Group i, i + 1 into C i . Ordering among i and i + 1 is not revealed. But all the edges between C i and C j for any j > i are directed from C i to C j . Now , one has t o design a set of interventions su ch that e xactly one n ode among every C i is intervened on at least o nce. This is because, if neither i nor i + 1 in C i are intervened on, then th e d irection b etween i and i + 1 can not be figured o ut b y 11 applying ru le R 2 on any other set of directio ns in the rest of th e graph . Since th e size of every intervention is at most k and at least n/ 2 nodes need to be covered by interven tion sets, the n umber of interventions required is at least n 2 k . 6.8 Pr oof of Theor em 5 Pr o of. Separ ate n vertices arbitr arily into n k disjoint su bsets C i of size- k . Let the first n/k in terventions { I 1 , I 2 , ..., I n/k } be su ch that I i ( v ) = 1 if and on ly if v ∈ C i . Th is divides the pro blem of learning a clique o f size n in to learnin g n/k cliques of size k . Then, we can apply the clique learning algo rithm in [ 8] as a black box to each of the n k blocks: E ach b lock is lear ned with pro bability k − c after log c lo g k exp eriments in expe ctation. For k = cn r , ch oose c > 1 /r − 1 . Then the u nion bo und over n/k blo cks yield s p robab ility po lynomial in n . Since ea ch block takes O (lo g log k ) experiments, we nee d n k O (lo g log k ) experiments. 6.9 Pr oof of Theor em 6 W e need the fo llowing d efinitions and some results before proving the theorem. Definition 2. A pe rfect elimination or dering σ p = { v 1 , v 2 . . . v n } o n the vertices o f an undir ected chor dal graph G is such that for all i , the induced neighborho od of v i on the subgraph formed by { v 1 , v 2 . . . v i − 1 } is a clique. Lemma 5. ( [6]) If all dir ections in the chordal graph ar e acco r ding to perfect elimina tion ordering (edges g o only fr om vertices lower in the or der to higher in the or der), then ther e are no immo ralities. W e make th e fo llowing o bservation: Let the direc tions in a graph D b e or iented acco rding to an ord ering σ on the vertices. If a cliq ue c omes first in the o rdering , then the k nowledge o f ed ge d irections in the rest o f the graph, excluding th at of th e clique, cannot help at any stage of the intervention pr ocess on the clique; beca use all the ed ges are directed outwards from the cliqu e and hen ce n one of the Meek rules app ly . This is b ecause, if a → b is to be inferred by Meek rules f rom o ther kn own dir ections, then either there has to be a kn own ed ge directio n into a o r b before the inf erence step. So if one of the directed edges not fro m the clique was to help in the discovery process, either that edge h as to be d irected to wards a o r b (like in Meek rules R 1 , R 2 and R 3 ), or it has to be directed towards c in another c → a (R 4 ) which belongs to the clique. Both the above ca ses are not possible. Lemma 6. ( [6]) Let C be a maximum clique of an undirected chor dal graph E ( D ) , th en ther e is an underlying D AG D on the chor dal skeleton that is o riented according to a perfect elimination or dering (implying no immoralities), wher e the clique C occurs first. By Le mmas 5, 6 and the observation above, given a chordal skeleton, we can co nstruct a D AG on the skeleton with no immoralities such that the directions of the maximu m clique in D cann ot be learned b y using knowledge of the directions outside . This means that only th e intervention sets { I 1 T C, I 2 T C . . . } matter fo r learnin g the dir ections on this cliq ue. The refore in ference on th e clique is isolated. Hence, all the lower bou nds for the cliqu e case tran sfer to this case and since the size of the largest clique is exactly the coloring numb er of the chordal skeleton, the theorem follows. 6.10 Proof of Th eor em 7 Example with a fea sible solution with |I | close to the lower bo und: Consider a graph G that can be partitione d into a cliqu e o f size χ an d an indepe ndent set α . Such g raphs are called split graphs and as n → ∞ , the fraction of split graphs to ch ordal graph s tends to 1 . If E ( D ) = G where G is a split gr aph skeleton, it is e nough to interven e only on the nod es in the clique an d the refore th e num ber of inter ventions that ar e needed is th at for the clique. It is cer tainly possible to orient the edges in such a way so as to a void immoralities, s ince the graph is chordal. Example with |I | which needs to be clo se to the upp er bound : W e construct a connected ch ordal skeleton with indepen dent set α an d clique s ize χ (also coloring number) s uch that i t would require α ( χ − 1) 2 k interventions a t least for any algorithm ov er a clas s of orientation s. Consider a line L co nsisting of vertices 1 , 2 . . . 2 α such that e very node 1 < i < 2 α is connected to i − 1 an d i + 1 . For , all 1 ≤ p ≤ α , c onsider a cliqu e C p of size χ wh ich only ha s n odes 2 p − 1 , 2 p from the lin e L . Now assume that the actual orientation of the L is 1 → 2 . . . → 2 α . In every cliq ue, the orientation is p artially specified as follo ws: In every clique C p , all edges fro m n ode 2 p − 1 are outgo ing. It is very clear that this partial orientation excludes all 12 immoralities. Fu rther, each clique C p − { 2 p − 1 } can hav e any a rbitrary orientation out of χ − 1 possible ones in the actual DA G. Now , even if all the specified dire ctions ar e revealed to the algorithm , the alg orithm h as to intervene o n all α disjoint cliques { C p − { 2 p − 1 }} α p =1 each of size χ − 1 and directions in one clique will not force directions on the o thers th rough any o f th e Meek rules or rule R 0 . Therefore, the lower bo und of α ( χ − 1) 2 total n ode accesses (to tal number of no des intervened) is implied b y T heorem 4. Gi ven ev ery interventio n is of size k , these cho rdal skeletons with the revealed partial ord er needs at least α ( χ − 1) 2 k more experiments. 6.11 Per f ormance Comparison of O ur Algorithm v s. Naiv e Scheme for n = 500 , k = 1 0 and n = 2000 , k = 20 20 30 40 50 60 70 80 90 100 110 0 10 20 30 40 50 60 70 80 90 100 Chromatic Number, χ Number of Experiments Information Theoretic LB Max. Clique Sep. Sys. Entropic LB Max. Clique Sep. Sys. Achievable LB Our Construction Clique Sep. Sys. LB Our Heuristic Algorithm Naive (n,k) Sep. Sys. based Algorithm Seperating System UB (a) n = 500 , k = 10 40 50 60 70 80 90 100 110 120 130 0 20 40 60 80 100 120 140 160 180 200 Chromatic Number, χ Number of Experiments Information Theoretic LB Max. Clique Sep. Sys. Entropic LB Max. Clique Sep. Sys. Achievable LB Our Construction Clique Sep. Sys. LB Our Heuristic Algorithm Naive (n,k) Sep. Sys. based Algorithm Seperating System UB (b) n = 20 00 , k = 20 Figure 2: n : no. of vertices, k : Intervention size b ound . The nu mber of e xperimen ts is c ompared betwe en our heuristic an d the naive algorithm b ased on the ( n, k ) sep arating system on r andom ch ordal grap hs. The r ed mar kers represent t he sizes o f ( χ, k ) sep arating system . Green circle markers and the cyan square markers fo r th e same χ value correspo nd to the number o f exper iments r equired by our h euristic and the alg orithm b ased on an ( n, k ) separating system(Theo rem 1), respectively , on the same set o f chord al graph s. All four plots (in cluding the ones in th e ma in text) in dicate that ou r algor ithm requ ires n umber o f experime nts propo rtional to the cliqu e num ber χ , whereas naive separating system based algorithm require s experiments on the order of number of v ariables n . 6.12 Proof of Th eor em 8 W e provid e th e following ju stifications for the correctness of Algorithm 1. 1. At line 4 of th e algorithm, when Meek rules and R 0 a re applied after every in tervention, the intermediate graph G , with unlear ned edges, will always be a disjoint union of cho rdal componen ts (refer t o (1) and the comme nts below) a nd hence a chordal graph. 2. The number of unlearne d ed ges befo re and after the main wh ile loo p in Algorithm 1 reduc es by at least one . Every edg e in E is incident on two co lors a nd one of the color s is always picked fo r p rocessing b ecause we use a separating system on the colors. Therefo re, one node be longing to some e dge has a p ositiv e score and is intervened on. The edg e direction is learnt through rule R 0 . Th erefor e, th e algorithm terminates. 3. It id entifies the co rrect ~ G because every edge is in ferred after some intervention I t by ap plying rule R 0 and Meek rules as in (1) both of which are correct. 4. the algor ithm has polyn omial run tim e complexity because the main while loop ends in time | E | . 13
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment