Standards for language resources in ISO -- Looking back at 13 fruitful years
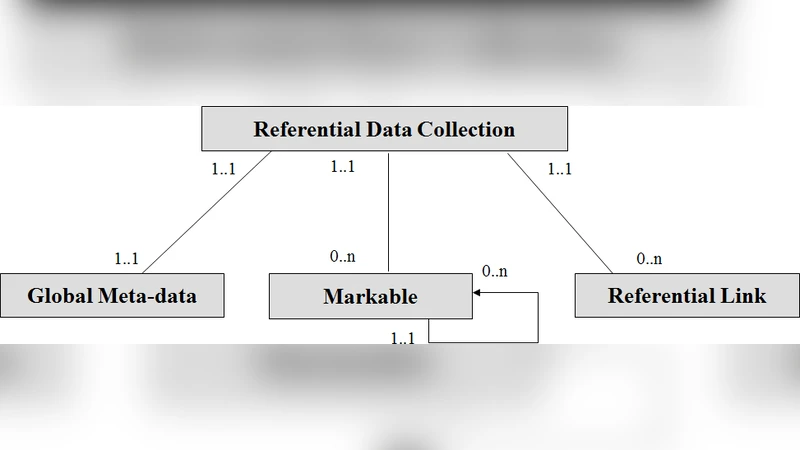
This paper provides an overview of the various projects carried out within ISO committee TC 37/SC 4 dealing with the management of language (digital) resources. On the basis of the technical experience gained in the committee and the wider standardization landscape the paper identifies some possible trends for the future.
💡 Research Summary
The paper provides a comprehensive retrospective of the work carried out by ISO Technical Committee 37, Sub‑Committee 4 (TC 37/SC 4) over the past thirteen years in the field of digital language‑resource management. It begins by outlining the rapid growth of electronic linguistic assets—lexicons, terminological databases, corpora, and annotation layers—and argues that a coordinated international standardization effort is essential to ensure interoperability, long‑term preservation, and efficient reuse of these resources.
The authors then chronologically review the major standards that have emerged from the committee. The Language Resource Metamodel (LRM), published as ISO 24613, introduced a modular, hierarchical representation for lexical entries, capturing form, sense, and relational information in a technology‑neutral way. Complementary to this, ISO 24610 defined a terminological data model that facilitates multilingual term alignment and concept mapping across disparate vocabularies.
From 2008 onward, the focus shifted toward corpus annotation. ISO 24614 established a generic annotation framework that can accommodate morphological, syntactic, semantic, and pragmatic layers, while ISO 24615 added support for multi‑layered annotations, allowing several independent annotation streams to coexist on the same text. Both standards rely heavily on the Data Category Registry (DCR) to provide a shared semantic backbone, ensuring that categories such as “part‑of‑speech”, “named‑entity type”, or “sentiment polarity” are consistently defined across projects and languages.
Beyond the technical specifications, the paper emphasizes the committee’s extensive community‑building activities. By aligning ISO standards with the Text Encoding Initiative (TEI) guidelines, releasing open‑source toolkits (e.g., LRM‑Toolkit, ISO‑Annotator), and organizing regular workshops and webinars, TC 37/SC 4 has fostered a vibrant ecosystem of implementers, researchers, and industry stakeholders. These outreach efforts have been crucial for translating abstract specifications into concrete, interoperable workflows used in language‑technology pipelines worldwide.
Drawing on this accumulated experience, the authors identify four emerging trends that will shape the next generation of language‑resource standards. First, the adoption of FAIR (Findable, Accessible, Interoperable, Reusable) principles demands richer, machine‑readable metadata and automated discovery mechanisms, especially as massive corpora are assembled for training large language models. Second, the integration of linked‑data and Semantic Web technologies is seen as a natural extension of the DCR, enabling resources to be published as RDF triples and linked across the global web of linguistic data. Third, the rise of AI and deep‑learning models calls for a formalized data‑governance framework that addresses data quality, bias mitigation, ethical use, and privacy protection—issues that are currently only loosely covered by existing standards. Fourth, the sustainable management of multilingual and multicultural resources, together with clear licensing and copyright guidance, requires stronger international collaboration between standard bodies, publishers, and research institutions.
In the concluding section, the paper argues that the standards developed over the past thirteen years have laid a solid technical foundation for language‑resource management, but that future success will depend on making those standards more flexible, extensible, and tightly coupled with emerging AI workflows. Continued investment in community education, open‑source tooling, and cross‑sector partnerships is presented as essential to ensure that ISO standards remain relevant and widely adopted in an increasingly data‑driven linguistic landscape.