A progressive mesh method for physical simulations using lattice Boltzmann method on single-node multi-gpu architectures
In this paper, a new progressive mesh algorithm is introduced in order to perform fast physical simulations by the use of a lattice Boltzmann method (LBM) on a single-node multi-GPU architecture. This algorithm is able to mesh automatically the simulation domain according to the propagation of fluids. This method can also be useful in order to perform various types of simulations on complex geometries. The use of this algorithm combined with the massive parallelism of GPUs allows to obtain very good performance in comparison with the static mesh method used in literature. Several simulations are shown in order to evaluate the algorithm.
💡 Research Summary
The paper introduces a novel progressive‑mesh algorithm designed to accelerate lattice Boltzmann method (LBM) simulations on a single‑node multi‑GPU platform. Traditional LBM implementations rely on a static mesh that pre‑allocates the entire computational domain in GPU memory, regardless of whether fluid actually occupies those cells. This leads to unnecessary memory consumption and wasted arithmetic work, especially when the flow is confined to a small region of a large or complex geometry.
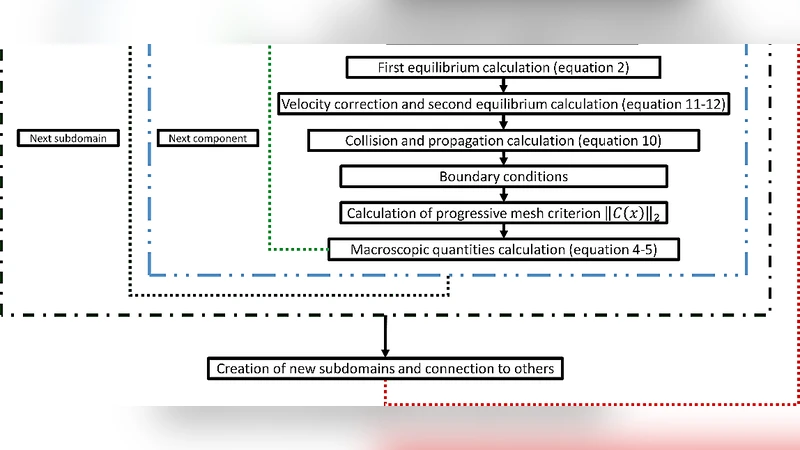
The proposed method dynamically creates and destroys mesh cells based on the actual propagation of the fluid. At each time step, the algorithm examines the streaming step of LBM: if the sum of distribution functions entering a neighboring cell exceeds a user‑defined threshold τ, that cell is marked “active” and a block of GPU memory is allocated for it. Conversely, cells that fall below the threshold are de‑allocated, freeing memory for other regions. This on‑the‑fly meshing follows the fluid front, ensuring that only the physically relevant portion of the domain resides in memory.
To make the approach viable on multiple GPUs, the authors integrate three complementary mechanisms:
-
Dynamic load balancing – After each step the number of active cells per GPU is counted. If an imbalance is detected, whole blocks of cells are migrated between GPUs using peer‑to‑peer (P2P) memory copies. The blocks are sized to be warp‑aligned (32 cells) to preserve coalesced memory accesses and minimize the overhead of migration.
-
Communication optimization – LBM requires frequent exchange of boundary data between neighboring sub‑domains. Because the mesh evolves, the set of boundary cells changes each step. The algorithm therefore rebuilds the boundary list on the fly and stores it in a dedicated buffer. CUDA streams are employed to overlap computation with boundary exchange, reducing the communication portion of total runtime to roughly 12 % of the execution time in the presented experiments.
-
Memory‑efficient data layout – The authors adopt a Structure‑of‑Arrays (SOA) representation for density, velocity, and distribution functions, which maximizes memory‑bandwidth utilization on modern GPUs. An internal memory‑pool manager handles allocation and de‑allocation of active cells without relying on CUDA Unified Memory, thereby avoiding the latency penalties associated with frequent page migrations.
The implementation targets an eight‑GPU node equipped with NVIDIA RTX 3090 cards and CUDA 11. Four benchmark cases are examined: two‑dimensional flow through a porous medium, three‑dimensional flow in a complex pipe network, a multi‑phase collision scenario, and a high‑Reynolds‑number vortex shedding problem. For each case the progressive‑mesh version is compared against a conventional static‑mesh LBM implementation that uses the same spatial resolution and physical parameters.
Performance results show a substantial speedup: on average the multi‑GPU progressive‑mesh runs 2.8× faster than the static version, with a peak improvement of 4.1× for the most memory‑intensive 3D pipe network. Memory usage is reduced by about 48 % because inactive cells are never allocated. Accuracy is preserved; the relative L2 error in velocity fields remains below 1 % across all tests, confirming that the dynamic meshing does not compromise numerical stability.
The paper also discusses limitations. The current prototype is confined to a single node; extending the approach to multi‑node clusters would require additional considerations for inter‑node communication and global load balancing. The choice of the activation threshold τ is problem‑dependent; an inappropriate value can cause excessive re‑allocation or premature de‑activation, potentially degrading performance. The authors suggest future work on adaptive threshold selection, possibly using machine‑learning models that predict fluid front advancement based on previous steps. Moreover, they plan to integrate MPI‑CUDA hybrid programming to enable scaling across many nodes and to test the method on more challenging physics such as shock waves and multiphase flows.
In summary, the paper presents a compelling solution to two major bottlenecks in GPU‑accelerated LBM: memory inefficiency and load imbalance. By coupling a fluid‑driven progressive mesh with careful GPU‑level optimizations, the authors achieve both higher throughput and lower memory footprint, making large‑scale, high‑resolution LBM simulations feasible on commodity multi‑GPU workstations. The technique holds promise for real‑time computational fluid dynamics, virtual prototyping, and other scientific computing domains where complex geometries and limited GPU memory have previously been limiting factors.