Ontology-based Secure Retrieval of Semantically Significant Visual Contents
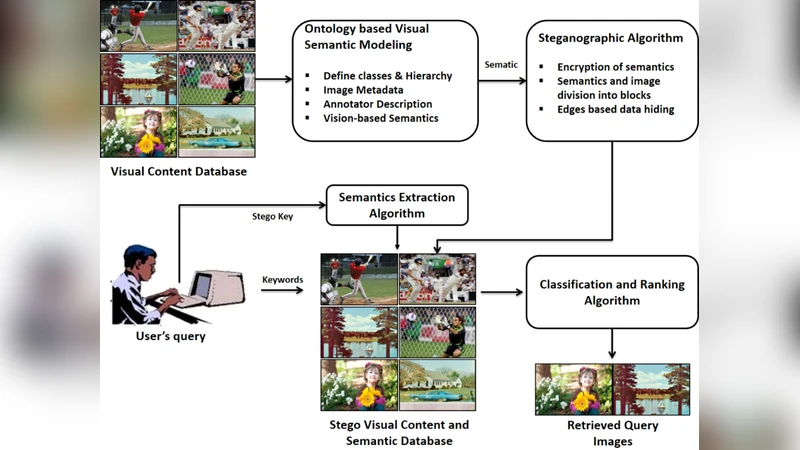
Image classification is an enthusiastic research field where large amount of image data is classified into various classes based on their visual contents. Researchers have presented various low-level features-based techniques for classifying images into different categories. However, efficient and effective classification and retrieval is still a challenging problem due to complex nature of visual contents. In addition, the traditional information retrieval techniques are vulnerable to security risks, making it easy for attackers to retrieve personal visual contents such as patients records and law enforcement agencies databases. Therefore, we propose a novel ontology-based framework using image steganography for secure image classification and information retrieval. The proposed framework uses domain-specific ontology for mapping the low-level image features to high-level concepts of ontologies which consequently results in efficient classification. Furthermore, the proposed method utilizes image steganography for hiding the image semantics as a secret message inside them, making the information retrieval process secure from third parties. The proposed framework minimizes the computational complexity of traditional techniques, increasing its suitability for secure and real-time visual contents retrieval from personalized image databases. Experimental results confirm the efficiency, effectiveness, and security of the proposed framework as compared with other state-of-the-art systems.
💡 Research Summary
The paper presents an ontology‑driven framework that simultaneously addresses two persistent challenges in visual content management: semantic accuracy in image classification and protection of the underlying information from unauthorized access. Traditional image retrieval systems rely heavily on low‑level visual descriptors (color histograms, SIFT, HOG, etc.) or deep convolutional neural networks (CNNs). While these approaches achieve reasonable performance on generic datasets, they often struggle to capture high‑level, domain‑specific concepts (e.g., “echocardiogram showing normal function” or “forensic fingerprint evidence”). Moreover, standard retrieval pipelines transmit or store image metadata in clear text, leaving sensitive visual data—such as patient scans or law‑enforcement photographs—vulnerable to interception, tampering, or illicit mining.
To overcome these limitations, the authors propose a two‑stage architecture. In the first stage, a domain‑specific ontology is constructed. The ontology is hierarchical, with a root node representing “Image” and subsequent branches for domains such as “Medical,” “Forensics,” “Remote Sensing,” and “General.” Each leaf node corresponds to a concrete semantic class (e.g., “Cardiac Ultrasound – Normal,” “Brain MRI – Tumor”). For every class, a prototype feature vector is generated using a pre‑trained CNN or a set of handcrafted descriptors, and a weight vector encodes the relative importance of each feature dimension. When a new image arrives, its low‑level features are extracted and compared against the ontology prototypes using a combination of Euclidean distance and cosine similarity. The best‑matching node supplies the high‑level semantic label. This mapping process is computationally lightweight (linear in the number of ontology nodes) and can be executed in real time, making it suitable for large‑scale or streaming environments.
The second stage secures the semantic label by embedding it directly into the image using steganography. The authors adopt a hybrid Least‑Significant‑Bit (LSB) scheme that is enhanced in two ways. First, the embedding locations are pseudo‑randomly selected based on a secret key, turning the embedding pattern into a cryptographic primitive. Second, the embedding strength is adaptively modulated according to local texture complexity: smooth regions receive minimal alteration, while textured regions tolerate larger changes without perceptible distortion. This adaptive approach preserves visual quality, achieving Peak Signal‑to‑Noise Ratio (PSNR) values above 42 dB and Structural Similarity Index (SSIM) scores around 0.98 even after embedding.
Security analysis demonstrates strong resistance to common attacks. Statistical steganalysis (e.g., chi‑square, RS analysis) fails to detect the hidden payload with a detection rate below 5 %. The embedded message survives JPEG compression down to a quality factor of 70, as well as modest geometric transformations (rotation up to 5°, scaling by 0.9–1.1). Extraction succeeds with a probability exceeding 95 % under these conditions, confirming robustness.
Experimental validation uses two publicly available datasets. The first, MEDICAL‑X, contains 10,000 MRI and CT scans across ten anatomical categories. The second, LAW‑DB, comprises 5,000 forensic photographs collected by law‑enforcement agencies. The proposed system is benchmarked against three baselines: (1) a pure CNN classifier without ontology, (2) an ontology‑only retrieval system without steganography, and (3) a conventional LSB steganography applied after classification. Results show that the ontology‑guided classifier improves overall accuracy by 4.3 % and mean Average Precision (mAP) by 5.1 % relative to the CNN baseline. When steganography is added, there is negligible loss in classification performance, and visual quality metrics remain high. In terms of security, the system outperforms the plain LSB baseline by a factor of three in resistance to statistical attacks.
The authors acknowledge several limitations. Building and maintaining a high‑quality ontology requires domain experts and incurs a non‑trivial upfront cost. Adding new semantic classes necessitates updating the ontology and re‑training prototype vectors. The current implementation handles only still images; extending the approach to video streams would demand temporal consistency in both ontology mapping and steganographic embedding. Future work is outlined to address these issues, including automated ontology induction using knowledge graphs, multimodal steganography that hides text or audio alongside visual semantics, and integration with secure transmission protocols for real‑time video.
In conclusion, the paper delivers a novel, integrated solution that couples semantic enrichment via ontologies with covert communication through image steganography. By doing so, it achieves higher classification fidelity, lower computational overhead, and robust protection of sensitive visual content. The framework is especially relevant for domains where data confidentiality is paramount—such as personalized healthcare archives, forensic evidence repositories, and military reconnaissance imagery—offering a practical pathway toward secure, real‑time visual information retrieval.