Representation Benefits of Deep Feedforward Networks
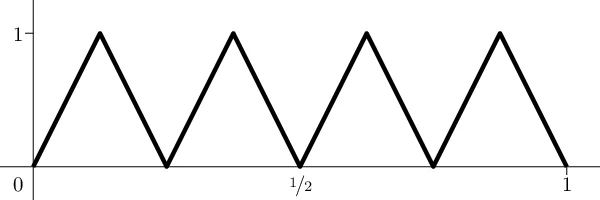
This note provides a family of classification problems, indexed by a positive integer $k$, where all shallow networks with fewer than exponentially (in $k$) many nodes exhibit error at least $1/6$, whereas a deep network with 2 nodes in each of $2k$ layers achieves zero error, as does a recurrent network with 3 distinct nodes iterated $k$ times. The proof is elementary, and the networks are standard feedforward networks with ReLU (Rectified Linear Unit) nonlinearities.
💡 Research Summary
The paper “Representation Benefits of Deep Feedforward Networks” presents a clean, elementary construction that demonstrates an exponential advantage of depth over width for a specific family of classification problems. The authors define a data set called the n‑alternating‑point (n‑ap) problem: for a given integer k they take n = 2^k points uniformly spaced in the interval
Comments & Academic Discussion
Loading comments...
Leave a Comment