Theoretical Analysis of the Optimal Free Responses of Graph-Based SFA for the Design of Training Graphs
Slow feature analysis (SFA) is an unsupervised learning algorithm that extracts slowly varying features from a time series. Graph-based SFA (GSFA) is a supervised extension that can solve regression problems if followed by a post-processing regressio…
Authors: Alberto N. Escalante-B., Laurenz Wiskott
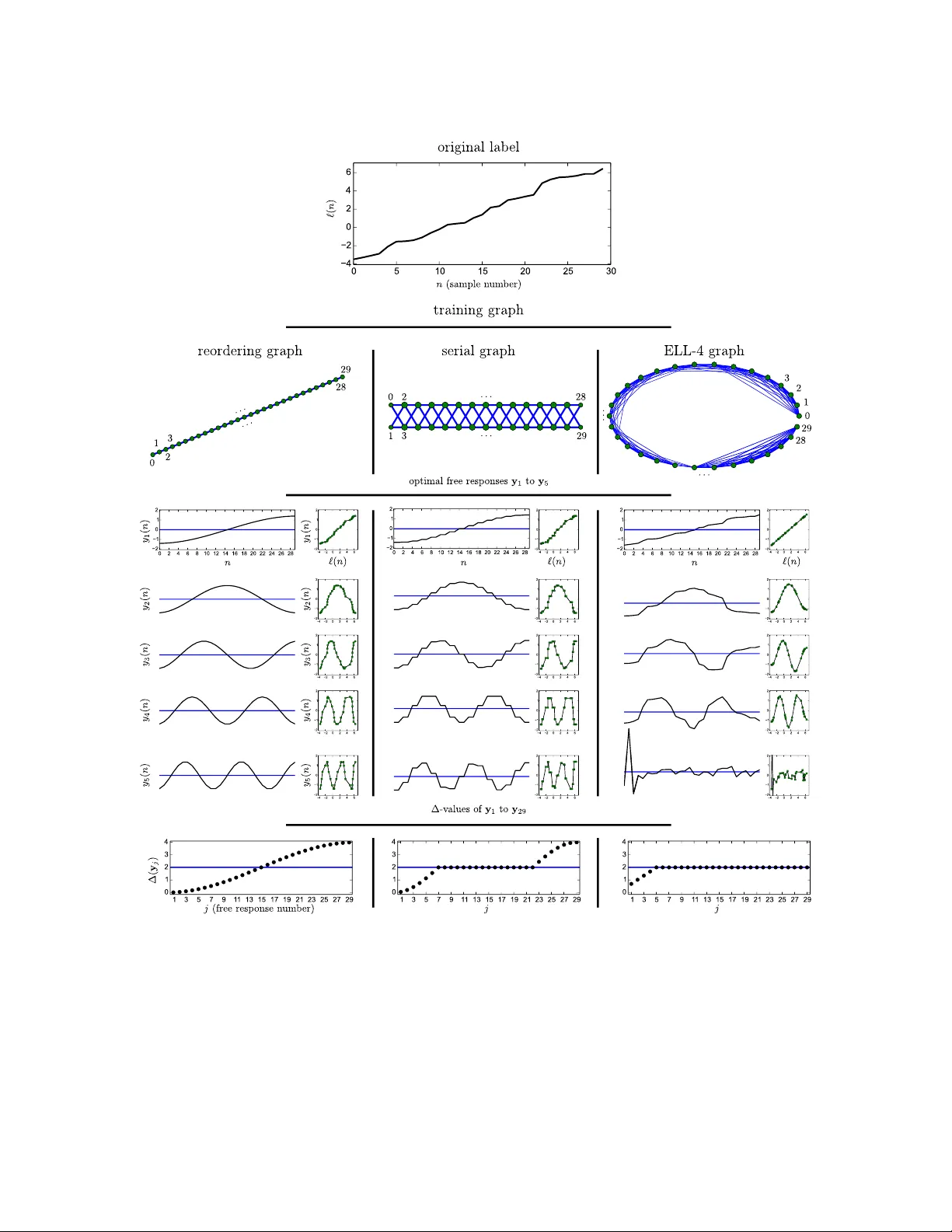
Theoretical Analysis of the Optimal F ree Resp onses of Graph-Based SF A for the Design of T raining Graphs (Preprin t) Alb erto N. Escalante-B. alber to.escalante@ini.r ub.de Laurenz Wisk ott laurenz.wisk ott@ini.rub.de The ory of Neur al Systems Institut f¨ ur Neur oinformatik R uhr-University Bo chum Bo chum D-44801, Germany Abstract Slo w feature analysis (SF A) is an unsup ervised learning algorithm that extracts slowly v arying features from a time series. Graph-based SF A (GSF A) is a sup ervise d extension that can solv e regression problems if follow ed by a p ost-processing regression algorithm. A training graph sp ecifies arbitrary connections b et ween the training samples. The connec- tions in curren t graphs, ho wev er, only dep end on the r ank of the in v olved lab els. Exploiting the exact lab el v alues mak es further improv ements in estimation accuracy p ossible. In this article, w e prop ose the exact lab el learning (ELL) metho d to create a graph that co des the desired lab el explicitly , so that GSF A is able to extract a normalized version of it directly . The ELL metho d is used for three tasks: (1) W e estimate gender from artificial images of human faces (regression) and sho w the adv an tage of co ding additional lab els, particularly skin color. (2) W e analyze tw o existing graphs for regression. (3) W e extract c omp act discriminativ e features to classify traffic sign images. When the num ber of output features is limited, a higher classification rate is obtained compared to a graph equiv alen t to nonlinear Fisher discriminan t analysis. The metho d is versatile, directly supp orts multiple lab els, and pro vides higher accuracy compared to current graphs for the problems considered. Keyw ords: Slo w F eature Analysis, Nonlinear Regression, Image Analysis, Pattern Recog- nition, Man y Classes 1. Introduction The slowness principle is one of the learning paradigms that might explain, at least in part, the self-organization of neurons in the brain to extract in v arian t represen tations of relev an t features. This principle operates on an abstract lev el and p ostulates that the most relev an t abstract information that can b e extracted from the environmen t typically c hanges muc h slo wer than the individual sensory inputs (e.g., the p osition of a bug compared to the quic kly c hanging neural activ ations in the retina of a frog observing it). The slo wness principle w as probably first form ulated b y Hin ton (1989), and online learn- ing rules w ere dev elop ed shortly after by F¨ oldi´ ak (1991) and Mitchison (1991). The first closed-form algorithm is referred to as slow feature analysis (SF A, Wiskott, 1998; Wisk ott and Sejnowski, 2002). Escalante-B. and Wiskott Recen tly , an extension of SF A for sup ervised learning called graph-based SF A (GSF A, Escalan te-B. and Wiskott, 2013) has b een prop osed. In contrast to SF A, which is trained with a sequence of samples, GSF A is trained with a so-called training graph, in which the v ertices are the samples and the edge weigh ts represen t similarities of the corresp onding lab els. In SF A, slowness requires the minimization of the squared output differences b et ween (temp orally) consecutiv e pairs of samples, whereas in GSF A the pairs of samples do not ha ve to b e consecutive, are weigh ted, and are defined by the training graph. GSF A can b e used to explicitly exploit the av ailable lab els b y establishing an output similarit y ob jectiv e inv olving arbitrary samples. T ypically , GSF A is more effective than SF A at extracting a set of features that tend to concentrate the lab el information and allo w the accurate prediction of the lab els, implicitly solving the sup ervised learning problem. Although GSF A and locality preserving pro jections (LPP , He and Niy ogi, 2003) originate from different bac kgrounds and were first motiv ated with differen t goals and applications in mind, there is a close relation b etw een them, sharing very similar ob jective functions and constrain ts. Tw o differences are that in GSF A the vertex weigh ts are indep endent of the edge weigh ts and that GSF A is in v arian t to the scale of the w eights, providing a normalized ob jective function. It is p ossible to use GSF A to compute LPP features, and vice v ersa. The results of this article might th us also b e of interest for the LPP communit y . In real life, man y supervised learning problems are solved by applying feature extraction, (unsup ervised) dimensionalit y reduction (DR), and an explicit supervised step (Figure 1.a). Another approac h (Figure 1.b), based on GSF A, first uses GSF A for sup ervise d DR, and then p ost-processes a small n umber of slow features with a conv en tional classification or regression algorithm. Sup ervised DR might result in higher accuracy than unsup ervised DR. The sup ervised learning problem is mostly solv ed b y GSF A implicitly , b ecause it fre- quen tly concentrates the lab el-predictiv e information in a few features. Therefore, the p ost-processing step is not crucial, and might b e a simple mapping from the slow features to the lab el domain. V arious training graphs for classification (clustered graph) and regression (e.g., serial, mixed, sliding window graphs) ha v e b een prop osed (Escalan te-B. and Wisk ott, 2013). These pre-defined graphs offer great efficiency; although the num b er of edges con tained in them is O ( N 2 ), where N is the num b er of samples, their structure makes the training complexit y linear w.r.t. N . Ho wev er, the construction of pre-defined graphs only tak es in to account the rank of the lab els and not their exact v alue, a simplification that might decrease the estimation accuracy . In this article, w e fo cus on the analysis and design of training graphs. W e explore a new approach for solving regression problems with GSF A based on the construction of a sp ecial training graph, in whic h the slo west feature extracted is already a lab el estimation, up to a linear scaling (Figure 1.c). T o dev elop this exact lab el learning (ELL) metho d, we first study the slow est p ossible features that can be extracted b y GSF A from a giv en graph when the feature space is unrestricted. Suc h features hav e also b een called optimal free resp onses and hav e b een computed for SF A in contin uous time b y Wisk ott (2003) using v ariational calculus. F or GSF A, we use a different metho d based on linear algebra to cop e with the discrete nature of the index n that takes the place of the time. Expressing the optimal free responses of GSF A in closed form then allows us to dev elop a theoretical metho d for the con verse op eration; from a set of free resp onses w e design 2 Optimal Free Responses of GSF A and the Design of Training Graphs Figure 1: Three approac hes for solving supervised learning problems. (a) A traditional and common approach. (b) Previous approac h using GSF A with a pre-defined training graph, which is defined by the input samples, no de weigh ts v , and edge weigh ts Γ . The samples are assumed to b e ordered b y increasing lab el. (c) The approac h prop osed here, which consists of a single GSF A architecture that is trained with a sp ecially constructed graph Γ ( ` , v ). The first slow feature (with a global sign adjustmen t) directly provides the lab el estimation. If the lab el ` do es not ha ve w eighted zero mean and weigh ted unit v ariance, a final linear scaling should b e included. the corresp onding training graph. The metho d allows the creation of a graph in which the slow est p ossible feature is the lab el to b e learned. Moreo ver, one can learn multiple lab els simultaneously (e.g., ob ject p osition, av erage color, shap e, and size), and balance their imp ortance. This prop ert y can b e exploited to learn auxiliary lab els , whic h pro vide a redundant co ding of the original labels that ma y increase their estimation accuracy . In this case, as later explained, it is p ossible and desirable to emphasize the imp ortance of the original lab els ov er the auxiliary ones. Cascaded GSF A refers to the consecutiv e application of m ultiple passes of GSF A. One adv an tage o v er direct GSF A is that the join t feature space may b e more complex. Hier- arc hical GSF A (HGSF A), similarly to hierarc hical SF A, is a divide-and-conquer approac h for the extraction of slow features from high-dimensional data. HGSF A offers an excellen t computational complexity compared to direct GSF A that can b e as go od as linear w.r.t the n umber of samples and the input dimensionality , depending on the net work architecture. A graph designed with the prop osed ELL metho d can b e used to train GSF A, cascaded GSF A, and HGSF A, b eing th us also applicable to high-dimensional data. Although the ELL metho d is based on theory and mostly contributes to a deep er un- derstanding of GSF A, it can also b e used in practice, providing higher accuracy than pre- defined graphs. While in general the ELL method results in a higher complexity compared to GSF A trained with an efficient pre-defined graph, it is still computationally viable for some datasets without resorting to sp ecialized hardware or parallelization. 3 Escalante-B. and Wiskott In the next section, we shortly review GSF A. In Section 3, we prop ose the ELL method. In Section 4, w e pro vide three applications. Firstly , we solv e a regression problem on gender estimation from artificial images, v alidating the method. Secondly , w e analyze efficient pre- defined training graphs for regression. Thirdly , we use the ELL metho d in a differen t w ay to design a training graph for the extraction of compact features for c lassification, yielding impro ved performance when log 2 ( C ) to C − 2 features are preserv ed. F or the first and third application, the accuracy is ev aluated exp erimentally . Section 5 closes the article with a discussion. 2. Graph-Based SF A (GSF A) In this section, we recall the GSF A optimization problem, review the GSF A algorithm, and sho w ho w GSF A can b e trained for b oth classification and regression. 2.1 T raining Graphs and the GSF A Problem GSF A is trained with a so-called training graph, in which the vertices are the samples and the edges b etw een tw o samples ma y represen t or b e related to the similarit y of their lab els. In mathematical terms, the training data is represen ted as a training graph G = ( V , E ) (illustrated in Figure 2.a) with a set V = { x ( n ) } n of v ertices, each vertex b eing a sample, and a set E of edges ( x ( n ) , x ( n 0 )), whic h are pairs of samples, with 1 ≤ n, n 0 ≤ N . The index n (or n 0 ) replaces the time v ariable t used by SF A. The edges are directed but typically ha ve symmetric weigh ts Γ T = Γ = { γ n,n 0 } n 0 ,n ; weigh ts v n > 0 are asso ciated with the v ertices x ( n ) and can b e used to reflect their imp ortance, frequency , or reliability . This represen tation includes the standard time series of SF A as a special case in which the graph has a linear structure (see Figure 2.b). T raining graphs for classification typically fa vor connections b et w een samples from the same class by means of larger edge w eights compared to those of different classes, whereas training graphs for regression fa vor connections b et ween samples with similar lab els. The concept of slowness has been generalized from sequences of samples (as in SF A) to training graphs. The general goal is to extract features that fulfill certain normalization restrictions and minimize the sum of the weigh ted squared output differences of all connected samples. More formally , the GSF A optimization problem (Escalante-B. and Wisk ott, 2013) can b e stated as follows. F or 1 ≤ j ≤ J , find features y j ( n ) def = g j ( x ( n )), where 1 ≤ n ≤ N and g j b elongs to the feature space F (frequent choices for F are all linear or quadratic transformations of the inputs), suc h that the ob jective function (weigh ted delta v alue) ∆ j def = 1 R X n,n 0 γ n,n 0 ( y j ( n 0 ) − y j ( n )) 2 is minimal (1) 4 Optimal Free Responses of GSF A and the Design of Training Graphs Figure 2: (a) Example of a training graph with N = 7 vertices. (b) A regular sample se- quence (time series), whic h can b e used to train SF A. This sequence is represen ted here as a linear graph that can b e used with GSF A. If lab els are av ailable and the samples hav e b een reordered b y increasing/decreasing label (e.g., instead of ha ving b een ordered b y time), it is called sample r e or dering graph. (Figure from Escalan te-B. and Wiskott, 2013). under the constrain ts 1 Q X n v n y j ( n ) = 0 , (2) 1 Q X n v n ( y j ( n )) 2 = 1 , and (3) 1 Q X n v n y j ( n ) y j 0 ( n ) = 0 , for j 0 < j , (4) with Q def = X n v n and R def = X n,n 0 γ n,n 0 . (5) The ob jectiv e function penalizes the squared output differences b et w een arbitrary pairs of samples using the edge w eights as weigh ting factors. The feature y 1 ( n ), for 1 ≤ n ≤ N , is the slo west one, y 2 ( n ) is the second slow est, and so on. Constrain ts (2)–(4) are called w eigh ted zero mean, w eigh ted unit v ariance, and w eighted decorrelation, resp ectiv ely . They are similar to the normalization constrain ts of SF A, except for the inclusion of vertex w eights. The factors 1 /R and 1 /Q are not essential for the optimization problem, but they pro vide inv ariance to the scale of the edge weigh ts as well as to the scale of the vertex w eights, and serve a normalization purp ose. 2.2 Linear GSF A Algorithm The linear GSF A algorithm is similar to standard SF A (Wiskott and Sejnowski, 2002) and only differs in the computation of the matrices C and ˙ C , which in GSF A takes in to account the neighborho o d structure sp ecified by the training graph (samples, edges, and weigh ts). 5 Escalante-B. and Wiskott The sample co v ariance matrix C G is defined as: C G def = 1 Q X n v n ( x ( n ) − ˜ x )( x ( n ) − ˜ x ) T , (6) where x ( n ) and v n denote an input sample and its w eight, resp ectiv ely , and ˜ x def = 1 Q X n v n x ( n ) (7) is the w eigh ted av erage of all samples. The deriv ative second-momen t matrix ˙ C G is defined as: ˙ C G def = 1 R X n,n 0 γ n,n 0 x ( n 0 ) − x ( n ) x ( n 0 ) − x ( n ) T , (8) where edge w eights γ n,n 0 are defined as 0 if the graph do es not ha ve an edge ( x ( n ) , x ( n 0 )). Giv en these matrices, a sphering matrix S and a rotation matrix R are computed with S T C G S = I , and (9) R T S T ˙ C G SR = Λ , (10) where Λ is a diagonal matrix with diagonal elements λ 1 ≤ λ 2 ≤ · · · ≤ λ J . Finally the algorithm returns ∆( y 1 ) , . . . , ∆( y J ), W and y ( n ), where W = SR , and (11) y ( n ) = W T ( x ( n ) − ˜ x ) . (12) It has been shown that the GSF A algorithm presen ted ab o ve indeed solv es the optimiza- tion problem (1 – 4) in the linear function space. The pro of is similar to the corresp onding pro of of standard linear SF A (Wisk ott and Sejnowski, 2002). Probabilistic in terpretation of a graph. In terestingly , if the graph is connected and the following consistency restriction is fulfilled ∀ n : v n /Q = X n 0 γ n,n 0 /R, (13) then GSF A yields the same features as standard SF A trained on a sequence generated b y using the graph as a Marko v c hain with transition probabilities γ n,n 0 /R (see Klampfl and Maass, 2010; Escalante-B. and Wiskott, 2013). Th us, one can use SF A to emulate GSF A. Ho wev er, dep ending on the training graph used, em ulating GSF A with SF A ma y b e more computationally exp ensiv e. 2.3 Clustered and Serial T raining Graphs In this section, w e present t wo efficient pre-defined graphs, the cluster e d gr aph for classifi- cation and the serial gr aph for regression (Escalante-B. and Wiskott, 2013). 6 Optimal Free Responses of GSF A and the Design of Training Graphs Figure 3: Illustration of a cluster e d training graph used for a classification problem with C classes. Each v ertex represen ts a sample, and edges represen t transitions. The N c samples b elonging to a class c ∈ { 1 , . . . , C } are connected, constituting a fully connected subgraph. Samples of different classes are not connected. V ertex w eights are iden tical and equal to one, whereas edge w eigh ts depend on the cluster size as γ n,n 0 = 1 / ( N c − 1), where x ( n ) and x ( n 0 ) b elong to class c and n 6 = n 0 . (Figure from Escalan te-B. and Wiskott, 2013). The clustered graph, describ ed in Figure 3, generates features useful for classification. The optimization problem asso ciated with this graph explicitly demands that samples from the same class should t ypically b e mapp ed to similar outputs. The features learned by GSF A on this graph are equiv alen t to those learned b y Fisher discriminan t analysis (FDA, see Klampfl and Maass, 2010 and also compare Berk es, 2005a and Berkes, 2005b). This type of problem can b e analyzed theoretically when the function space of SF A is unrestricted. Consisten t with FDA, the first C − 1 slo w features extracted (optimal free responses) are orthogonal step functions, and are piece-wise constan t for sam- ples from the same class (Berkes, 2005a). The serial training graph, describ ed in Figure 4, is constructed by discretizing the original lab el ` in to a relatively small set of K discrete lab el v alues, namely { ` 1 , . . . , ` K } , where ` 1 < ` 2 < · · · < ` K . Afterwards, the samples are divided into K groups of size N /K sharing the same discrete labels. Edges connect all pairs of samples from consecutiv e groups with discrete lab els ` k and ` k +1 , for 1 ≤ k ≤ K − 1. Thus, connections are only in ter-group, and intra-group connections do not app ear. Notice that since an y tw o v ertices of the same group are adjacent to exactly the same neigh b ors, they are likely to be mapped to similar outputs by GSF A. F ollowing GSF A a complementary explicit regression step on a few features solves the original regression problem. There are several efficient graphs for regression b esides the serial gr aph . W e emplo y the serial graph in this article, because it has consistently giv en go o d results for v arious regression problems. The clustered and serial graphs allow efficien t training in linear time w.r.t N , whereas the n umber of connections considered is O ( N 2 ) if the n um b er of clusters or groups is constant. 7 Escalante-B. and Wiskott Figure 4: Illustration of a serial training graph with K discrete lab el v alues { ` 1 , . . . , ` K } . In this graph, the vertices are ordered and then group ed according to their discrete lab el. Even though the original lab el of t w o samples migh t differ, they will be group ed together if they hav e the same discrete lab el. Eac h dot represents a sample, edges represent connections, and ov als represent groups of samples. The samples of groups with discrete labels ` 2 to ` K − 1 ha ve a weigh t of 2, whereas the samples of extreme groups with labels ` 1 or ` K ha ve a w eight of 1 (sample w eigh ts represen ted by bigger/smaller dots). The w eight of all edges is 1. (Figure from Escalan te-B. and Wiskott, 2013). 2.4 GSF A Optimization Problem in Matrix Notation In order to apply linear algebra metho ds to analyze GSF A, we use matrix notation. In what follo ws w e assume that the edge w eights are symmetric 1 ( Γ = Γ T ) and that the consistency restriction (13) is fulfilled. This restriction can also b e written as v (13) = Q R Γ1 , (14) where 1 is a v ector of ones of length N . If y is a feasible solution (i.e., satisfying (2) and (3)) and the graph fulfills the consistency restriction (14), the weigh ted delta v alue (1) can b e simplified as follows, ∆ y (1) = 1 R X n,n 0 γ n,n 0 ( y ( n 0 ) − y ( n )) 2 (15) = 1 R X n 0 ( y ( n 0 )) 2 X n γ n,n 0 + X n ( y ( n )) 2 X n 0 γ n,n 0 − 2 X n,n 0 γ n,n 0 y ( n 0 ) y ( n ) (16) (14) = 1 R X n 0 ( y ( n 0 )) 2 R Q v ( n 0 ) + X n ( y ( n )) 2 R Q v ( n ) − 2 y T Γy (17) (3) = 2 − 2 R y T Γy . (18) 1. An asymmetric edge-weigh t matrix Γ can be conv erted in to a symmetric one Γ 0 def = Γ + Γ T 2 without altering the solution to the optimization problem. 8 Optimal Free Responses of GSF A and the Design of Training Graphs The optimization problem can then b e stated as: F or 1 ≤ j ≤ J , find vectors y j of length N , with y j ( n ) def = g j ( x ( n )) and g j ∈ F , minimizing ∆ j (1 , 3 , 14) = 2 − 2 R y T j Γy j (19) sub ject to: v T y j (2) = 0 (20) y T j Diag( v ) y j (3) = Q (21) y T j Diag( v ) y j 0 (4) = 0 , for j 0 < j , (22) where Q (5 .a ) = 1 T v , (23) R (5 .b ) = 1 T Γ1 , (24) and Diag( v ) denotes a diagonal matrix with diagonal v . 3. Explicit Lab el Learning for Regression Problems 3.1 Optimal F ree Responses of GSF A In this section, we calculate the slo west possible solutions (optimal free responses) to the GSF A problem (19)–(22) that one could find if the feature space w ere unlimited. W e use the Lagrange m ultiplier metho d to find critical p oints y that are candidates for the optimal free resp onses. F or the momen t, w e ignore the w eigh ted decorrelation constrain t (22) to solve for the first optimal free resp onse, but we consider the remaining resp onses later. Due to the close relationship betw een GSF A and LPP , the approach b elo w is strongly related to Laplacian Eigenmaps (Belkin and Niy ogi, 2003). Let L def = 2 − 2 R y T Γy + α v T y + β y T Diag( v ) y − Q (25) b e a Lagrangian corresponding to the ob jectiv e function (19), under the constraints (20) and (21). A signal y is a critical p oin t if the partial deriv ativ es of L with resp ect to α, β , and y ( n ), for 1 ≤ n ≤ N , are simultaneously zero: ∂ L/∂ α (25) = v T y ! = 0 , (26) ∂ L/∂ β (25) = y T Diag( v ) y − Q ! = 0 , and (27) ∂ L/∂ y (25) = − 4 R Γy + α v + 2 β Diag( v ) y ! = 0 , (28) where 0 is a v ector of zeros. 9 Escalante-B. and Wiskott Equations (26) and (27) merely require that the output y has weigh ted zero mean and w eighted unit v ariance, resp ectiv ely . Multiplying (28) with 1 T from the left and taking into accoun t that 1 T Diag( v ) = v T , 1 T v (23) = Q , 1 T Γ (14) = R Q v T , and Q > 0 results in: − 4 R R Q v T y + αQ + 2 β v T y = 0 , (29) implying α = 0 due to (26). Therefore, (28) can b e simplified to: − 4 R Γ + 2 β Diag( v ) y = 0 , (30) ⇔ Diag( v − 1 / 2 ) 4 R Γ − 2 β Diag( v ) Diag( v − 1 / 2 )Diag( v 1 / 2 ) y = 0 , (31) ⇔ 4 R Diag( v − 1 / 2 ) Γ Diag( v − 1 / 2 ) − 2 β I Diag( v 1 / 2 ) y = 0 , (32) ⇔ Diag( v − 1 / 2 ) Γ Diag( v − 1 / 2 ) − Rβ 2 I Diag( v 1 / 2 ) y = 0 , (33) where v 1 / 2 is defined as the elemen t-wise square ro ot of the elements of v , and v − 1 / 2 is defined similarly (as usual, w eights v j are required to b e strictly p ositiv e). In a few words, y is a critical point if it fulfills the weigh ted normalization conditions and the v ector Diag( v 1 / 2 ) y is an eigen vector of the matrix M defined as M def = Diag( v − 1 / 2 ) Γ Diag( v − 1 / 2 ) . (34) The corresp onding eigenv alue is denoted λ = Rβ 2 . (35) W e denote the (orthogonal) eigen vectors of the matrix M as u j with u T j u j = 1. Each eigen- v ector gives rise to a critical p oin t y j def = Q 1 / 2 Diag( v − 1 / 2 ) u j if the weigh ted normalization conditions are also satisfied b y y j . The slo west p ossible solution is the critical p oin t y j with the smallest ∆-v alue. As w e sho w b elo w, the ∆-v alue of a critical p oin t y j is directly related to the eigen v alue λ j of the eigenv ector u j = Q − 1 / 2 Diag( v 1 / 2 ) y j of M and can b e computed as follo ws. ∆ y j (19) = 2 − 2 R ( y j ) T Γy j (36) (34) = 2 − 2 R ( y j ) T Diag( v 1 / 2 ) M Diag( v 1 / 2 ) y j (37) (35) = 2 − 2 R ( y j ) T Diag( v 1 / 2 ) λ j Diag( v 1 / 2 ) y j (38) (21) = 2 − 2 Q R λ j (39) Th us, the slo west solution is the critical p oin t y j with the largest eigen v alue λ j . The re- maining optimal free responses are the remaining critical points, and their the corresponding 10 Optimal Free Responses of GSF A and the Design of Training Graphs eigen v alue defines their order, from largest to smallest. The weigh ted decorrelation condition (22) is fulfilled due to the orthogonality of the eigen vectors: u T i u j = 0 ⇔ 1 Q y T i Diag( v ) y j = 0 (follo ws from the definition of y j ab o v e). One sp ecial case is when an eigen v alue has m ultiplicities. This means that t wo or more optimal free responses and any rotation of them hav e the same delta v alue. In this case, some optimal free resp onses are not unique, but any rotation of them is equiv alent. 3.2 Design of a T raining Graph for Learning One or Multiple Lab els Giv en a set of samples { x (1) , . . . , x ( N ) } with lab el ` = ( ` 1 , . . . , ` N ), w e sho w how to generate a training graph, suc h that the slow est feature that could b e extracted b y GSF A is equal to a normalized version of the label. Notice that this problem (determining the structure of a training graph, or more concretely , its edge-weigh t matrix Γ , ha ving a particular optimal solution) differs considerably from the original GSF A problem of finding an optimal solution giv en a training graph and a feature space. The approac h can b e extended to m ultiple labels p er sample. T o distinguish them, we introduce an index 1 ≤ j ≤ L , making ` j denote the j -th lab el. In this case, the L lab els can b e expressed linearly in terms of the first L free resp onses. V ertex-w eights v n indicate a priori lik eliho o d information ab out the samples, and are th us assumed to b e giv en and strictly p ositiv e. If this information is absen t, one may set the vertex w eights constan t, e.g. v = 1 N 1 . Due to the normalization constrain ts, the outputs generated b y GSF A m ust hav e weigh ted zero mean (20) and weigh ted unit v ariance (21). Therefore, we learn a w eight-normalized lab el ˜ ` , as follo ws: Let µ ` = 1 Q v T ` b e the weigh ted lab el a verage and σ 2 ` = 1 Q ( ` − µ ` 1 ) T Diag( v )( ` − µ ` 1 ) b e the weigh ted lab el v ariance. Then, the normalized lab el is com- puted as ˜ ` = 1 σ ` ( ` − µ ` 1 ) . (40) Hence, it is trivial to map from a normalized to a non-normalized lab el and vic e versa . In order for the construction to w ork when samples ha ve m ultiple lab els, w e m ust w eight decorrelate them first. T o decorrelate t wo labels ` j 0 and ` j , with j 0 > j , one can pro ject ` j out of ` j 0 ; ` dec j 0 ( n ) = ` j 0 ( n ) − 1 Q ` T j 0 Diag( v ) ` j ` j ( n ), which is an inv ertible linear op eration. F rom no w on, w e assume that the lab els ` 1 , . . . , ` L are decorrelated and normalized. W e compute edge w eights γ n,n 0 suc h that the j -th optimal free response is equal to ` j (with arbitrary p olarit y). Define Γ ELL def = Diag( v 1 / 2 ) M ELL Diag( v 1 / 2 ) , (41) where M ELL def = N − 1 X j =0 λ j u ELL j ( u ELL j ) T . (42) If L < N − 1 one can set λ j >L = 0. The matrix Γ ELL defined ab o ve is symmetric b y construction. The eigenv ectors and eigenv alues of M ELL , which are explicit in its eigenv ec- tor decomposition ab o ve, directly define the matrix Γ ELL and determine the optimal free 11 Escalante-B. and Wiskott resp onses of the resulting graph. Concretely , for eac h j ≥ 1 one sets u ELL j according to the desired lab el ` j (ignore u ELL 0 and λ 0 for the time b eing). u ELL j = Q − 1 / 2 Diag( v 1 / 2 ) ` j , for j ≥ 1 (43) Notice that the w eighted decorrelation of the lab els translates directly into the orthog- onalit y of the corresp onding eigen vectors 1 Q ( ` j ) T Diag( v ) ` j 0 (22) = 0 (43) ⇔ ( u ELL j ) T u ELL j 0 = 0 (44) Once the eigen vectors are computed we must decide whic h eigen v alues we w ant to give them. Alternatively , we can decide which ∆ v alues we giv e to the lab els, b ecause ∆ ` j and λ j are directly related: λ j (39) = R 2 Q (2 − ∆ ` j ). Larger eigenv alues (equiv alen t to smaller ∆ v alues) might result in higher accuracy for the corresponding lab el. W e giv e some intuition on how to choose the eigen v alues of the eigenv ectors. a) In general, important lab els should ha v e larger eigenv alues than less imp ortan t ones. b) The global scale of the eigen v alues λ j > 0 is irrelev ant, only their relativ e scales matter. F or conv enience one can scale them so that P λ j > 0 = 1. c) If tw o lab els are similarly imp ortan t, their eigenv alues should b e also sim ilar. F or example, if one only wan ts to learn a single label ` 1 with a delta v alue ∆ ` 1 = 0, one can set u ELL 1 = Q − 1 / 2 Diag( v 1 / 2 ) ` 1 , λ 1 = 1, and the eigen v alues λ j > 1 to zero. If ` 1 tak es only t wo p ossible v alues (e.g., − 1 and 1), the resulting graph will b e disconnected and con tain t wo clusters. Otherwise, the resulting graph will b e connected, and the condition ∆ ` 1 = 0 necessarily implies that some of the resulting edge w eigh ts will b e negativ e, a condition that w e deal with in Section 3.3. The analysis of Section 3.1, which is used b y the ELL metho d requires that the graph fulfills the consistency restriction (14), which dep ends on u 0 and λ 0 , as follo ws, Γ ELL 1 (41 , 42) = Diag( v 1 / 2 ) X λ j u ELL j ( u ELL j ) T Diag( v 1 / 2 ) 1 (45) = Diag( v 1 / 2 ) X λ j u ELL j ( u ELL j ) T u ELL 0 Q 1 / 2 (46) = Diag( v 1 / 2 ) λ 0 u ELL 0 Q 1 / 2 (47) ! = ( R/Q ) v . (48) T o satisfy the equation ab o ve one can set u ELL 0 = Q − 1 / 2 v 1 / 2 with eigenv alue λ 0 = R/Q , which also ensures ( u ELL 0 ) T u ELL 0 = 1 and 1 T Γ ELL 1 = R . The free pseudo-resp onse ` 0 (43) = 1 corresp onding to u ELL 0 fulfills equations (21) and (22) but not (20). Therefore, ` 0 is not a feasible solution, but it has similar prop erties to the optimal free resp onses. The introduction of u ELL 0 do es not reduce the generality of the lab els ` j > 0 that can b e learned; orthogonalit y betw een u ELL 0 and u ELL j > 0 is equiv alen t to the weigh ted zero mean of ` j > 0 (20), which is required anyw a y for an y feasible solution, i.e., ( u ELL 0 ) T u ELL j = 0 (44) ⇔ ( Q − 1 / 2 v 1 / 2 ) T Q − 1 / 2 Diag( v 1 / 2 ) ` j = Q − 1 v T ` j = 0. Although only L free responses are explicitly defined, N − L − 1 additional optimal free resp onses are defined implicitly with an eigenv alue of 0, corresp onding to ∆ = 2 . 0. This 12 Optimal Free Responses of GSF A and the Design of Training Graphs ∆ v alue has a particular meaning, b ecause as we prov e in the next paragraph, it is the ∆ v alue of unit-v ariance zero-mean i.i.d. noise for certain graphs. 3.2.1 Expected Weighted ∆ V alue of a Noise Fea ture Let y b e a noise feature randomly sampled from a zero-mean unit-v ariance distribution D , i.e., y ( n ) ← D (0 , 1). On av erage, y fulfills the normalization conditions, as can be seen as follo ws. (20): h v T y i D = v T h y i D = 0 , (49) (21): h y T Diag( v ) y i D = h X n v n y ( n ) 2 i D = X n v n h y ( n ) 2 i D = Q , (50) where h·i D denotes expected v alue when sampling ov er D . The expected delta v alue can b e computed as h ∆ y i D (1) = 1 R X n,n 0 γ n,n 0 h ( y ( n 0 ) − y ( n )) 2 i D (51) = 1 R X n,n 0 ,n 6 = n 0 γ n,n 0 h ( y ( n 0 ) − y ( n )) 2 i D + X n γ n,n h ( y ( n ) − y ( n )) 2 i D (52) = 1 R X n,n 0 ,n 6 = n 0 γ n,n 0 h y ( n 0 ) 2 i D + h y ( n ) 2 i D − 2 h y ( n 0 ) i D h y ( n ) i D + 0 (53) = 1 R X n,n 0 ,n 6 = n 0 γ n,n 0 (1 + 1 − 0) (54) = 2 R X n,n 0 γ n,n 0 − X n γ n,n = 2( R − P n γ n,n ) R . (55) Therefore, if the graph has no self-lo ops (i.e., ∀ n : γ n,n = 0), the exp ected ∆ v alue h ∆ y i D of a noise feature is 2. The self-lo ops of a graph (e.g., one constructed using the ELL metho d) can be remov ed without changing the free responses, only affecting the scale of the delta v alues due to the c hange in R . The consistency restriction migh t b e broken, though. 3.3 Elimination of Negativ e Edge W eights F rom the ob jective function (1), it is ob vious that a positive edge w eight connecting t w o samples expresses that those samples should be mapp ed close to eac h other in feature space. In con trast, negativ e edge w eights express that t wo samples should b e mapp ed as far apart as p ossible, th us enco ding output dissimilarities. Nev ertheless, the weigh ted unit v ariance constrain t still applies, so the solutions are not unbounded. If the edge weigh ts are non-negative, the smallest p ossible ∆ v alue is ∆ = 0. Ho wev er, if negative edge w eights are allo w ed, some feasible features migh t hav e ∆ < 0. A feature with ∆ < 0 would app ear to b e “slow er” than the infeasible constant feature y = 1 with ∆ = 0, contradicting the in tuitive interpretation of slo wness. Moreo ver, negativ e edge 13 Escalante-B. and Wiskott w eights hinder the probabilistic in terpretation of the graph (see Section 2.2), because some of the transition probabilities γ n,n 0 /R of the resulting Marko v chain w ould b e negative. T raining graphs constructed using the ELL method migh t include negative edge w eights, whic h w ould result in the disadv an tages describ ed ab o v e. In this section, w e add an additional step to the ELL method to ensure that the training graph has non-negativ e edge w eights. More concretely , w e sho w ho w to transform a training graph with strictly positive v ertex w eigh ts v n and arbitrary edge w eights Γ (positive and negativ e) in to a graph with the same vertex w eights and only non-negative edge weigh ts Γ 0 . The optimization problem defined b y Γ 0 is equiv alen t to the original optimization problem in terms of its solutions and their order. Only the v alue of the ob jective function is linearly c hanged (or, more precisely , changed b y an affine function). Assume that ∀ n : v n > 0, and that there is at least one elemen t γ n,n 0 < 0. Let c def = max n,n 0 − γ n,n 0 v n v n 0 . The new edge weigh ts Γ 0 are defined as Γ 0 def = 1 1 + cQ 2 /R ( Γ + c vv T ) . (56) No w, w e sho w the prop erties of Γ 0 and its relation to Γ : 1. All elements of Γ 0 are greater or equal to zero, as desired. (F ollows from the definition of c ; γ n,n 0 + cv n v n 0 ≥ 0.) 2. Symmetry is preserved; clearly Γ 0 is symmetric if and only if Γ is symmetric. 3. The sum of edge-weigh ts is preserved: R 0 = 1 T Γ 0 1 = R + cQ 2 1 + cQ 2 /R = R . (57) 4. F ulfillment of the graph consistency restriction (14) is preserv ed: 1 T Γ (14) = R /Q v T ⇒ 1 T Γ 0 (56) = 1 1 + cQ 2 /R ( 1 T Γ + c 1 T vv T ) (58) (14) = 1 1 + cQ 2 /R ( R/Q v T + cQ v T ) (59) = R/Q 1 + cQ 2 /R (1 + cQ 2 /R ) v T (60) = R/Q v T . (61) 5. Γ and Γ 0 define equiv alen t optimization problems. Let y b e a feasible solution. The constrain ts of the optimization problem are indep enden t of Γ 0 , and only the ob jective 14 Optimal Free Responses of GSF A and the Design of Training Graphs function is mo dified as follows: ∆ 0 y (18) = 2 − 2 R 0 y T Γ 0 y (62) (56 , 57) = 2 − 2 R (1 + cQ 2 /R ) y T Γy + c y T vv T y (63) (20) = 2 − 2 R (1 + cQ 2 /R ) y T Γy (64) (18) = 2 − 2 R (1 + cQ 2 /R ) R 2 (2 − ∆ y ) (65) = 1 (1 + cQ 2 /R ) ∆ y + 2 cQ 2 R . (66) Therefore, the ob jective function is only mo dified by a p ositive scaling factor and a constan t p ositive offset, pro ving that the optimal free solutions to the training graph remain stable, as well as their order. 6. In particular, a feature y with ∆ y = 2 preserves its delta v alue, i.e. ∆ y = 2 (65) ⇔ ∆ 0 y = 2. 3.4 Auxiliary Labels for Bo osting Estimation Accuracy When GSF A is applied repeatedly (e.g., cascaded or in a con v ergent hierarc hical GSF A net- w ork) one can pro vide additional auxiliary lab els deriv ed from the original one ` 1 to impro ve the estimation accuracy . Informally , even though a given GSF A no de might not b e able to extract ` 1 accurately , it migh t b e capable of appro ximating features f 2 ( ` 1 ) , f 3 ( ` 1 ) , . . . , f K ( ` 1 ). Since these features are derived from the lab el, they con tain information that (partially) determines it. Hence, a p osterior GSF A no de might b e able to disentangle these features more effectiv ely to recov er the original label. One can explicitly promote the app earance of these features b y learning also auxiliary lab els ` k = f k ( ` 1 ), for 2 ≤ k ≤ K . The functions f k can b e defined arbitrarily , one simple choice is to use ` k ( n ) = cos ` 1 ( n ) − min( ` 1 ) max( ` 1 ) − min( ` 1 ) π k , for 2 ≤ k ≤ K , (67) where max( ` 1 ) is the largest lab el v alue, and min( ` 1 ) is the smallest one. Notice that for k = 2 the argumen t of the cosine function ranges from 0 to π , for k = 3 from 0 to (3 / 2) π , etc. In this sense, these features are “higher-frequency” versions of ` 1 . The eigen v alues corresp onding to the auxiliary lab els must b e set smaller than those of the original lab el. Otherwise, the slow est features found migh t b e close to the auxiliary lab els rather than to the original one. F rom no w on, w e use the term tar get lab els to refer to the original and auxiliary lab els, if presen t. In terestingly , in regular SF A (or GSF A trained with the reordering graph) the inclusion of auxiliary lab els o ccurs automatically . The slo west free resp onse is a half p erio d of a cosine function, and the subsequen t free responses are the higher-frequency harmonics of the first one (see Section 4.2, particularly Figure 7). 15 Escalante-B. and Wiskott 3.5 Computational Complexit y of Explicit Label Learning The main dra wbac k of ELL is its computational efficiency compared to efficien t pre-defined training graphs, whic h is more mark ed for large N . W e analyse the efficiency of explicit lab el learning by considering its tw o main parts: The construction of the training graph and training GSF A with it. The graph construction requires O ( L 2 N + LN 2 ) op erations. The term L 2 N is due to the transformation of L target lab els into eigenv ectors, whic h migh t require a decorrelation step on L N -dimensional vectors. The term LN 2 is due to the computation of M , which in volv es L vector multiplications u j u T j . When training GSF A, three computations are particularly exp ensiv e. Firstly , the com- putation of C G , whic h tak es O ( N I 2 ) op erations. Secondly , the computation of ˙ C G , whic h can b e expressed as ˙ C G = 2 Q X Diag( v ) X T − 2 R XΓX T , where X = x 1 , . . . , x N , taking O ( N 2 I + N I 2 ) op erations. Thirdly , the solution to the generalized eigen v alue problem, whic h requires O ( I 3 ) op erations. Therefore, in general, training GSF A requires O ( N I 2 + N 2 I + I 3 ) op erations. Typically N > I to a void ov erfitting, so the computation of ˙ C G is the most exp ensiv e part. Ho wev er, when a pre-defined graph is used instead of an ELL graph, ˙ C G migh t b e computed more efficiently b y using optimized algorithms. If an efficient pre-defined graph is used (e.g. the serial graph), ˙ C G can b e computed in O ( N I 2 ) op erations (due to the regular structure of the graph), whic h is the complexit y of the same op eration using standard SF A on N I -dimensional samples. Moreov er, if the num b er of edges N e ≤ N ( N + 1) / 2 is small, one can use (8) to compute ˙ C G in O ( N e I 2 ) operations. Therefore, for these t wo sp ecial cases, training GSF A tak es O ( N I 2 + I 3 ) and O (( N e + N ) I 2 + I 3 ) op erations, resp ectiv ely . 4. Applications of Explicit Lab el Learning In this section, we present three applications of the prop osed metho d. First, we illustrate ho w to solve a regression problem with GSF A explicitly , learning a direct mapping from images to their lab els (see Figure 1.c). In the second application, w e analyse t w o pre-defined graphs by computing their optimal free resp onses. In the third application, w e use the ELL metho d in a new wa y to learn compact discriminative lab els for classification. 4.1 Explicit Estimation of Gender with GSF A W e consider the problem of gender estimation from artificial face images, whic h is treated here as a regression problem, because the gender parameter is defined as a real v alue b y the face mo delling softw are. Input data. The input data are 20,000 64 × 64 gra yscale images. Each image is generated using a new sub ject iden tit y , where the gender is sp ecified b y us, and the rest of the param- eters of the faces (e.g., age, racial comp osition) are random. The a verage pixel intensit y of eac h image is normalized by m ultiplying it by an appropriate factor. The resulting images sho w sub jects with a fixed p ose, no hair or accessories, fixed illumination, constan t a verage pixel intensit y , and a blac k background. See Figure 5 for some sample images. 60 different v alues of the gender parameter are used ( − 3 , − 2 . 9 , . . . , 2 . 9). 16 Optimal Free Responses of GSF A and the Design of Training Graphs Figure 5: Example of the images used, showing differen t v alues of the gender parameter. The images are randomly split into a training and a test set. The training set consists of 10,800 images, 180 images for eac h gender v alue, whereas the test set consists of 1,200 images, 20 images for eac h gender v alue. Besides the gender lab el, we also consider a second “color” lab el, which is the av erage pixel in tensit y of the image b efor e normalization. Due to normalization, this lab el cannot b e computed directly , but it can b e estimated from other cues, suc h as the sub ject’s apparent race and face size. In the following experiment w e consider only the gender label, but later w e use b oth lab els (gender and color) sim ultaneously . Net w ork used. F or efficiency reasons, hierarc hical GSF A (HGSF A) is used. W e teste an 8-lay er HGSF A netw ork with the structure describ ed in T able 1. The no des of the net work hav e non-o verlapping receptive fields and are comp osed of an expansion function ( x 1 , . . . , x n ) 7→ ( x 1 , . . . , x n , | x 1 | 0 . 8 , . . . , | x n | 0 . 8 ) follo w ed b y linear GSF A. This expansion only doubles the data dimensionalit y and is called 0.8Exp o (Escalante-B. and Wisk ott, 2011). The no des of the first lay er include a PCA pre-pro cessing step, in which 50 out of 64 comp onen ts are preserv ed. la yer n umber no de’s receptive input dim expanded dim output dim of nodes field (pixels) per node p er no de p er no de 1 8 × 8 8 × 8 64 100 40 2 4 × 8 16 × 8 80 160 40 3 4 × 4 16 × 16 80 160 40 4 2 × 4 32 × 16 80 160 40 5 2 × 2 32 × 32 80 160 40 6 1 × 2 64 × 32 80 160 40 7 1 × 1 64 × 64 80 160 40 8 1 × 1 64 × 64 40 80 6 T able 1: Structure of the GSF A hierarchical netw ork. The inputs to the no des in the first la yer are 8 × 8-pixel patches. The input to the no de in la yer 8 is the output of the no de in la yer 7. The inputs to all other no des come from t wo con tiguous (either v ertically or horizontally) no des in the previous lay er. T raining graphs for gender estimation. Several training graphs are constructed with the ELL metho d describ ed in Sections 3.2 – 3.4. The graphs are denoted ELL g - L , where L is 17 Escalante-B. and Wiskott the total n umber of target lab els considered, with L ∈ { 1 , 10 , 20 , 30 , 40 , 50 } . The first target lab el ` 1 ( n ) is the gender parameter, where 1 ≤ n ≤ 10,800. The remaining L − 1 lab els are auxiliary and computed using (67). F or comparison purp oses, the serial and reordering training graphs w ere also tested. Lab el estimations. W e used three mappings from the slow est features to the lab el estimation ˆ ` . The first mapping (only av ailable for the ELL graphs) is a linear scaling ˆ ` = ± y 1 σ ` + µ ` that inv erts the lab el normalization (40). Since the sign of y 1 is arbitrary , it is globally adjusted to b est fit the lab els. The second metho d is linear regression (LR). F or these tw o metho ds, final lab el estimation ˆ ` is clipp ed to the v alid lab el range [ − 3 , 2 . 9]. The third mapping is the Soft GC metho d, which pro vides a soft estimation based on the class probabilities estimated b y a Gaussian classifier (trained with 60 classes, Escalan te-B. and Wiskott, 2013). Results. T able 2 (left) shows the lab el estimation errors (RMSE) for the gender lab el. Dep ending on the mapping, the ELL g -10 and ELL g -40 graphs outp erform the rest. This supp orts the intuition that auxiliary lab els are useful. 50 target lab els p erform w orse than 40, probably in part because the output dimensionalit y of the intermediate no des in the net work is 40. Without the final clipping step LR was clearly more accurate than linear scaling (exp erimen t not shown), but b oth metho ds ha ve similar accuracy if clipping is enabled. F or all graphs, the explicitly supervised soft GC method pro vided better accuracy than the linear scaling method, although the difference is less than one migh t ha ve exp ected. Graph ELL g - L L scaling LR soft GC soft GC (1F) (1F) (1F) (3F) 1 0.376 0.380 0.364 0.365 10 0.364 0.365 0.353 0.356 20 0.372 0.374 0.356 0.357 30 0.367 0.368 0.350 0.349 40 0.368 0.367 0.346 0.345 50 0.376 0.375 0.351 0.350 Graph ELL g ,c - L L scaling LR soft GC soft GC (1F) (1F) (1F) (3F) 2 × 1 0.298 0.299 0.289 0.284 2 × 5 0.349 0.350 0.343 0.277 2 × 10 0.423 0.426 0.410 0.288 2 × 15 0.473 0.478 0.453 0.291 2 × 20 0.508 0.514 0.479 0.292 2 × 25 0.535 0.543 0.499 0.294 T able 2: Gender estimation errors (RMSE) using v arious graphs and either one (1F) or three (3F) features. F or the linear regression (LR) mapping, the lab el is estimated as ˆ ` 1 = ay 1 + b , with a and b fitted to the training data. Chance level (RMSE) is 1.731 if one uses the constant estimation ˆ ` 1 = − 0 . 05. All results on test data and a veraged ov er 10 runs. (Left) Error using training graphs for gender estimation only . (Righ t) Error using training graphs for the exp erimen t on simultaneous gender and color estimation. F or comparison, the serial graph results in RMSEs of 0.351 (soft GC, 1F) and 0.349 (soft GC, 3F), whereas the reordering graph results in RMSEs of 0.353 (soft GC, 1F) and 0.347 (soft GC, 3F). The accuracy of these t w o graphs app ears to b e similar; ho wev er, in more complex exp erimen ts the serial graph has typically b een more accurate (e.g., Escalan te-B. and Wiskott, 2013). The ELL g -40 graph is, therefore, sligh tly more accurate than the serial 18 Optimal Free Responses of GSF A and the Design of Training Graphs and reordering graphs but 25 times slo wer, taking ab out 250 min for training instead of ab out 10 min (single thread). Sim ultaneous learning of gender and color. W e construct a graph that codes gender and color sim ultaneously , learning lab els y 1 , . . . , y L , where y 1 , y 3 , . . . , y L − 1 are deriv ed from the gender lab el, and y 2 , y 4 , . . . , y L are deriv ed from the color lab el. These lab els are computed similarly to when learning gender only but using t wo differen t original lab els. W e use linearly decreasing eigenv alues. The resulting graphs are denoted ELL g ,c - L , where L is the total num b er of target lab els, with L = 2 × d , and 2( d − 1) is the n umber of auxiliary lab els used for gender and color. Graph ELL c - L L scaling LR soft GC soft GC (1F) (1F) (1F) (3F) 1 2 1.987 1.971 1.979 10 1.969 1.958 1.905 1.922 20 2.006 1.999 1.914 1.922 30 1.991 1.989 1.877 1.889 40 1.990 1.990 1.864 1.867 50 1.997 1.997 1.865 1.871 Graph ELL g ,c - L L LR soft GC LR soft GC (1F) (1F) (3F) (3F) 2 × 1 4.247 4.291 1.393 1.221 2 × 5 3.606 3.614 1.239 1.210 2 × 10 3.214 3.185 1.337 1.180 2 × 15 2.978 2.945 1.429 1.158 2 × 20 2.828 2.802 1.501 1.141 2 × 25 2.718 2.700 1.582 1.140 T able 3: Color estimation errors (RMSE) using v arious graphs and either one (1F) or three (3F) features. Chance lev el (RMSE) is 7.447. All results on test data and a v eraged o ver 10 runs. (Left) Error using training graphs that co de only color. (Righ t) Error using training graphs that sim ultaneously co de gender and color. The effect of co ding gender and color sim ultaneously on gender estimation is shown in T able 2, right (compare to T able 2, left). The ELL g ,c - L graphs yield higher accuracy than the ELL g - L graphs. The res ults on color estimation using the ELL g ,c - L graphs are shown in T able 3, right (compare to T able 3, left). The slo west feature extracted represen ts mostly gender. How ev er, it also con tains color information b ecause it allo ws color estimation better than the chance lev el. When 3 features are preserv ed, the ELL g ,c - L graphs yield higher accuracy than the ELL c - L graphs. Similar experimental results ha v e b een rep orted, e.g. by Guo and Mu (2014), who ha ve shown that age estimation impro ves when gender and race lab els are also considered. Learning lab el transformations. W e verify that the metho d can learn other lab els implicitly describ ed b y the data. More precisely , w e use GSF A to learn labels ( ` 1 ) 2 and ( ` 1 ) 3 , which are distorted versions of the original gender lab el ` 1 . The graphs constructed for this purp ose are denoted ELL g -40 ( ` 1 ) 2 and ELL g -40 ( ` 1 ) 3 , resp ectiv ely . Both of them include 39 auxiliary lab els b esides the main distorted lab el. T o b etter approximate the target lab els, more complex nonlinearities are used in some of the nodes of the hierarchical net works. The ( ` 1 ) 2 net work is iden tical to the ` 1 net work, except that in the top node the quadratic expansion is used instead of the 0.8Expo expansion. Similarly , the ( ` 1 ) 3 net work uses the quadratic expansion in the 7th la yer, and the 6th-degree p olynomial expansion in the top node. In b oth net w orks, the output dimension of the no de in the 7th la yer is set to 3 to a void o verfitting due to the expansion in the 8th lay er. 19 Escalante-B. and Wiskott The corresp onding label estimations are sho wn in Figure 6. F or comparison, also the ELL g -40 graph is included. The results pro v e that the ELL method can also b e used to learn distortions of the main lab el. Admittedly , the accuracy of the estimations (normalized b y the resp ectiv e c hance lev els) decreases ev en though w e increase the complexit y of the feature space. Figure 6: Plots (a) to (c) show the lab el estimations on test data when different distorted v ersions of ` 1 are learned. The linear scaling mapping was used. Therefore, the estimations are only generated from the slow est feature. Ground-truth v alues sho wn in thick er blac k. The RMSE is expressed in brac kets as a p ercen tage of the chance lev el. Plot (d) is analogous to (c) but sho ws training data. 4.2 Analysis of Pre-Defined T raining Graphs In this section, w e use the m ethod of Section 3.1 to extract the optimal free responses of three graphs (reordering, serial and ELL-4). The optimal free resp onses and their ∆ v alues (alternativ ely , the eigenv ectors u j and eigen v alues λ j ) fully c haracterize the prop erties of a training graph, and pro vide another represen tation of it that migh t be more useful in some scenarios. W e compute optimal free resp onses using (33)–(35) and their delta v alues using (39). Therefore, these results ha ve b een obtained analytically . W e plot them in Figure 7, whic h sho ws an arbitrary lab el to b e learned (top), and three different graphs that can b e used for this purp ose. Only N = 30 samples (ordered by increasing lab el) were used to ease visualization, but the plots b eha ve similarly for larger N . The employ ed graphs are as follo ws. The reordering graph has b een extended with tw o edge w eights γ 0 , 0 = 1 and γ N − 1 ,N − 1 = 1 to fulfill the consistency restriction (13), which is required by the metho d. These weigh ts in tro duce a constant scaling N / ( N + 2) of the delta v alues, without any further consequence. The serial graph (Section 2.3) has K = 15 groups of 2 samples each. The ELL-4 graph (Sections 3.2 – 3.4) is constructed with the original lab els ` 1 ( n ) = ` ( n ), and 3 auxiliary lab els computed using (67). The figure sho ws that the most remark able difference betw een the graphs is the n umber of optimal free resp onses with ∆ < 2 . 0, whic h is 14 for the reordering graph, 6 for the serial graph, and 4 for the ELL-4 graph, for the parameters ab ov e. F or arbitrary parameters, the reordering, serial and ELL- L graphs hav e b ( N − 1) / 2 c , b ( K − 1) / 2 c , and, dep ending on the eigen v alues, up to L ≤ N − 1 optimal free resp onses with ∆ < 2 . 0, resp ectively . 20 Optimal Free Responses of GSF A and the Design of Training Graphs Figure 7: An arbitrary lab el (top) and three graphs that can b e used to learn it. The fiv e slow est optimal free resp onses of eac h graph are plotted, as w ell as the delta v alues of all optimal free resp onses. The ELL-4 graph is almost fully connected, but here only the strongest 30% of the connections are displa yed. Samples hav e an index n from 0 to 29, and free resp onses ha ve an index j from 1 to 29. The free resp onses are also plotted against the original label. The p olarit y of the free resp onses w as adjusted once to make them negative for the first sample. 21 Escalante-B. and Wiskott Although the graphs differ considerably in their connectivity , their first four to five optimal free resp onses hav e a somewhat similar shap e. Since in all graphs the slow est free resp onse y 1 is increasing, a monotonic mapping w ould b e enough to approximate the label for an y of them. How ev er, for the serial graph the slo west response is constant within eac h group, which migh t lo w er accuracy due to a discretization error. The ELL-4 graph has b een tailored to learn a particular lab el, and therefore y 1 is exactly ` 1 (the original label) except for an offset and scaling. The analysis mak es clear that the serial and ELL-4 graphs are mor e sele ctive than the reordering graph regarding the features that they consider slo w. T o illustrate why this migh t b e an adv an tage, consider a scaled and noisy version ˆ y 1 of ` 1 . More concretely , ˆ y 1 ( n ) = √ 2 2 ` 1 ( n ) + √ 2 2 e ( n ), where e ( n ) is an i.i.d. zero-mean unit-v ariance noise signal. When the reordering graph is used, the feature ˆ y 1 has an av erage ∆-v alue of ab out 1 (i.e. h ∆ ˆ y 1 i ≈ 1), and therefore such a feature w ould app ear to be faster than the auxiliary feature y 6 , b ecause ∆ y 6 ≈ 0 . 38. Hence, a GSF A node trained with the reordering graph w ould fav or the extraction of y 6 o ver ˆ y 1 ( n ), ev en though ˆ y 1 ( n ) is more similar to the lab el. In contrast, the serial and ELL-4 graphs migh t fa v or the extraction of ˆ y 1 , because for these graphs ∆ y 6 is close to 2.0. 4.3 Compact Discriminativ e F eatures for Classification A w ell-known algorithm for sup ervised dimensionality reduction for classification is Fisher discriminan t analysis (FD A). According to the theory of FD A, if there are C classes, C − 1 features define a C − 1 dimensional subspace that b est separates the classes. In practice, one t ypically uses all these C − 1 features, b ecause all of them con tain discriminativ e information and con tribute to classification accuracy . The same holds for GSF A if the clustered training graph is used (GSF A+clustered), b ecause in this case the features learned are equiv alen t to those of FD A (Klampfl and Maass, 2010; Escalan te-B. and Wiskott, 2013). One can tak e adv antage of hierarc hical processing to do classification using the clustered graph (HGSF A+clustered). Ho wev er, when the n um b er of classes C is large (e.g. C ≥ 100) it might become exp ensiv e to preserve C − 1 features in each no de, b ecause the size of the input to subsequen t no des would b e a multiple of C − 1. This dimensionality would be further increased by the expansion function, resulting in a large training complexit y . F or instance, consider a 3-no de nonlinear netw ork for classification with tw o GSF A no des in the first la yer and one in the top. Supp ose the first tw o no des hav e output dimensionality C − 1 = 99 so that the input into the top node would be 198, and suppose that the top no de applies a quadratic expansion to its input data b efore linear GSF A. The expanded data w ould hav e dimensionalit y I 0 =19,701. The com bination of a large sample dimensionalit y I 0 and a large num b er of samples N (with N I 0 to a void ov erfitting) would result in considerable computational and memory costs. Therefore, if w e could co de the class information in the first lay er more compactly , we could reduce the output dimensionality of the first-la yer no des and reduce ov erfitting, aiming at increasing classification accuracy . In this section, w e use the theory of explicit learning with multiple lab els to compute compact features for classification using GSF A. W e classify images of C = 32 traffic signs from the German traffic sign recognition b enc hmark database (Houb en et al., 2013). 22 Optimal Free Responses of GSF A and the Design of Training Graphs The images are represen ted as 48 × 48-pixel color (RGB) images (see Figure 8). W e use only 32 out of 43 traffic signs with the most samples. F or the training data, we use the same n umber of samples for each class (traffic sign), namely 2,160 of them, making a total of 69,120 images. T o reach 2,160 samples p er class, images of some classes are used up to 6 times (since the database is unbalanced). The images used for training are distorted b y a random rotation r of − 3 . 15 ≤ r ≤ 3 . 15 degrees, horizon tal and vertical translations ∆ x , ∆ y with − 1 . 73 ≤ ∆ x , ∆ y ≤ 1 . 73 pixels, and a scaling factor s with 0 . 91 ≤ s ≤ 1 . 09. The purp ose of the distortion is to improv e generalization and pro vide in v ariances to small misalignmen ts. W e use the official test data, which ensures that the images originate from ph ysical signs different from the ones used for training. The test data consists of 9,030 undistorted images. Figure 8: The 32 traffic signs learned, one image p er class. W e used a simple (non-hierarchical) GSF A architecture, in whic h PCA is applied first to reduce the dimensionalit y to 120 principal comp onen ts. Afterw ards, quadratic GSF A is applied using differen t training graphs, described b elo w. Finally , since this is a classification problem, a nearest centroid classifier is used instead of linear scaling. The ELL method is used to construct t wo training graphs with binary target labels (i.e, a lab el is either 1 or − 1). The first one has 5 lab els (compact+5) and the second one has 31 (compact+31). The target lab els are defined in T able 4. Notice that the first 5 labels (for b oth graphs) suffice, in principle, to fully co de the class information. F or the compact+5 graph, identical eigenv alues ( λ 1 1 = λ 1 2 = λ 1 3 = λ 1 4 = λ 1 5 = 0 . 2) are used to express equal imp ortance of the target lab els. The compact+31 graph has b een included to show the effect of auxiliary lab els ` 6 , ` 7 , . . . , ` 31 . F or this graph, the first five eigen v alues ( λ 2 1 , λ 2 2 , . . . , λ 2 5 ) = (0 . 056 , 0 . 056 , . . . , 0 . 056) are identical, but the rest decrease linearly: ( λ 2 6 , λ 2 7 , . . . , λ 2 31 ) = (0 . 053 , 0 . 051 , . . . , 0 . 002), where only three decimal places are sho wn. Th us, the imp ortance given to the auxiliary lab els decreases from ` 6 to ` 31 . F or b oth graphs, we scale the eigenv alues to make their sum equal to 1. W e c hoose C = 2 5 classes, because p o w ers of tw o mak e it simple to obtain binary lab els with a weigh ted zero mean, weigh ted unit v ariance, and weigh ted decorrelation, as follo ws. The first five original lab els can b e computed as ` j ( c ) = 2( c − 1 2 5 − j mo d 2) − 1, where the 23 Escalante-B. and Wiskott c → 1 2 3 4 5 6 7 8 9 . . . 16 17 . . . 30 31 32 ` 1 ( c ) -1 -1 -1 -1 -1 -1 -1 -1 -1 . . . -1 1 . . . 1 1 1 ` 2 ( c ) -1 -1 -1 -1 -1 -1 -1 -1 1 . . . 1 -1 . . . 1 1 1 ` 3 ( c ) -1 -1 -1 -1 1 1 1 1 -1 . . . 1 -1 . . . 1 1 1 ` 4 ( c ) -1 -1 1 1 -1 -1 1 1 -1 . . . 1 -1 . . . -1 1 1 ` 5 ( c ) -1 1 -1 1 -1 1 -1 1 -1 . . . 1 -1 . . . 1 -1 1 ` 6 ( c ) -1 1 1 -1 1 -1 -1 1 1 . . . -1 1 . . . -1 -1 1 ` 7 ( c ) -1 -1 1 1 1 1 -1 -1 1 . . . 1 1 . . . 1 -1 -1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ` 30 ( c ) -1 1 -1 1 1 -1 1 -1 -1 . . . -1 -1 . . . -1 1 -1 ` 31 ( c ) -1 1 1 -1 -1 1 1 -1 -1 . . . -1 -1 . . . 1 1 -1 T able 4: T arget labels used to co de the class information, compactly expressed as a function of the class num b er c . The compact+5 graph is constructed with lab els ` 1 to ` 5 , whereas the compact+31 graph with ` 1 to ` 31 . The first five lab els can be seen as the original ones and the rest as auxiliary . division is in teger division and “mo d” is the modulo op eration. The auxiliary lab els are computed as the pro duct of t w o or more labels ` 1 to ` 5 , possibly m ultiplied b y a factor − 1 to mak e the lab el assigned to the first class negative. More concretely , ` 6 is the product of all original labels, ` 7 to ` 11 are all the pro ducts of four of them, ` 12 to ` 21 are all the pro ducts of three, and ` 22 to ` 31 are all the pro ducts of t wo (e.g., ` 6 = ` 1 ` 2 ` 3 ` 4 ` 5 , ` 7 = − ` 1 ` 2 ` 3 ` 4 , ` 8 = − ` 1 ` 2 ` 3 ` 5 , ` 30 = − ` 3 ` 5 , ` 31 = − ` 4 ` 5 ). F or b oth graphs, w e set v = 1 . The corresp onding eigen vectors are u j (43) = Q − 1 / 2 ` j , where Q (5) = N · 1 = 69,120 ( N is the num b er of training images). These eigenv ectors are also binary and allow for a fast computation of the co v ariance matrix in O ( LN I 2 + I 3 ) op erations, where L is the n umber of target lab els. The classification error is plotted in Figure 9, where the n um b er of slow features d given to a nearest centroid classifier ranges from 4 to 31. F or comparison, the clustered graph is also ev aluated. F or d = 5 features, the compact+5 graph results in the b est accuracy with an error rate of 11.67%, against 12.42% (compact+31) and 29.74% (clustered). Ho wev er, the error rate of the compact+5 graph increases if one preserv es more than 5 features, indicating that additional features con tain little or no discriminative information. F or 6 ≤ d ≤ 30, the compact+31 graph yields clearly b etter accuracy than the other graphs. Interestingly , for d = 31 = C − 1 features, the compact+31 and clustered graph give identical error rates of 2 . 89%, whic h is their top performance. In this case, the features extracted are differ ent but con tain the same information since they can b e mapp ed to each other linearly . In other w ords, the first 31 free resp onses of b oth graphs describ e the same subspace. Any single slo w feature from the compact+31 graph con tains ideally 1 bit of discriminativ e information (whic h migh t b e redundan t to the others). In con trast, the first features extracted by the clustered graph migh t sacrifice discriminativ e information to minimize within-class v ariance (e.g., a feature y ( c ) = ( C 2 ) 1 / 2 , − ( C 2 ) 1 / 2 , 0 , 0 , . . . , 0 has minimal (zero) within-class v ariance but pro vides little discriminativ e information, b ecause only the first t wo classes can be iden tified from it). Using d > 31 features do es not improv e accuracy in any case. 24 Optimal Free Responses of GSF A and the Design of Training Graphs Figure 9: Classification error when GSF A is trained with the compact+5, compact+31 and clustered graph (FDA). This error is a function of the graph and the num ber of slo w features d passed to the classifier. F or the clustered graph, dropping even a single feature might increase the error rate significantly . F or instance, the error rate of using 30 features computed with the clustered graph is worse than the error rate of 13 features computed with the compact+31 graph. P erformance on 9,030 test samples, av eraged ov er 10 runs (largest standard deviation 0.15%). One assumption of this method is that the feature space is complex enough to allow the extraction of features that approximate the binary lab els. If the feature space is p oor, the compact graphs migh t not bring an y adv an tage ov er the clustered one. The results suggest that if the num b er of features to b e preserved d < C − 1 is known, one might impro ve accuracy by creating a graph that uses exactly d target lab els. If the n umber of output features is unclear, a graph co ding sev eral auxiliary labels with decreasing eigen v alues, e.g. compact+( C − 1), might pro vide b etter robustness (see Figure 9). 5. Discussion In this article, w e propose exact lab el learning (ELL) for the construction of training graphs, in which the final lab el estimation is just a linear transformation of the slow est feature extracted. The metho d allows the direct solution of regression problems with GSF A, without ha ving to recur to a sup ervised p ost-processing step. In other words, giv en a new input sample (e.g. an input image) the first feature computed using an ELL graph directly pro vides an appro ximation of the lab el (or a linear transformation of it). In practice, ev en b etter results may b e ac hieved using more than one feature and sup ervised p ost-pro cessing. It is crucial to emphasize that GSF A optimizes feature slowness, whic h dep ends on the particular training graph used, and not label estimation accuracy . How ev er, when the ELL metho d is used, the training graphs define a slo wness ob jective that requires optimizing an output similarit y function, where the similarities are intimately related to the desired lab el similarities. As a result, the feature slowness and estimation accuracy ob jectiv es b ecome equiv alen t when F b ecomes unlimited. That is, the slow est p ossible features that can b e 25 Escalante-B. and Wiskott extracted (i.e. optimal free resp onses) are equal to a normalized v ersion of the lab el(s). In practice, F is finite to allow generalization from training to test data and, if the features extracted are slow enough (i.e. close to the optimal free resp onses), they are also go od solutions to the original regression problem. Sup ervised learning problems on high-dimensional data are of great practical imp or- tance, but they frequently result in systems with large computational demands. A common approac h is to apply feature extraction, dimensionalit y reduction, and a supervised learning algorithm. A promising alternative approach is hierarc hical GSF A (HGSF A), because its complexit y scales in some cases even linearly w.r.t. the input dimensionality and the num- b er of samples. F urthermore, when HGSF A is trained with an ELL graph, the resulting arc hitecture is simple and homogeneous, as shown in Figure 1.c. W e ha ve prov ed the usefulness of the ELL method b y sho wing three t yp es of applications that are relev an t in practice: ELL regression with multiple lab els, analysis of training graphs, and classification with compact discriminative features. The results sho w that enco ding auxiliary lab els deriv ed from the original one (e.g. “higher-frequency” transformations of it) impro ve p erformance. This is particularly rel- ev an t for cascaded or con v ergent hierarc hical GSF A net works. The auxiliary lab els con tain information that (partially) determines the original lab el. A GSF A no de that receives this information might b e able to extract the original lab el more accurately than without it. Multiple lab els can b e learned sim ultaneously , for instance to co de different asp ects of the input at once (e.g. ob ject color, size, shap e, orien tation). The use of m ultiple lab els is inspired by biological systems, where complemen tary information channels ha ve b een observ ed and migh t improv e feature robustness, for example under incomplete informa- tion (Kr ¨ uger et al., 2013). Learning gender and color simultaneously yielded clearly smaller estimation errors than when gender and color were estimated separately . This sho ws that m ultiple lab el learning is not only theoretically possible, but that co ding complemen tary information channels migh t b oost accuracy in practice. F or instance, an automatic system for face pro cessing migh t benefit from the simultaneous extraction of the sub ject’s iden tity , age, gender, race, p ose, and expression. The exp erimen ts on gender (and skin-color) estimation from artificial face images v erify that the ELL metho d works in practice. The complexity of training a single GSF A node with an ELL graph is O ( I N 2 + I 2 N + I 3 ) op erations, where I is the input dimensionality (p ossibly after a nonlinear expansion), and N > I is the n umber of samples. F or comparison, the serial graph has a complexity of O ( I 2 N + I 3 ). Th us, the main limitation of using ELL graphs is the training complexit y . The analytical and practical results sho w the strength of the serial graph when only a single lab el is av ailable. In this case, the ELL graph pro vided marginally better estimations than the serial one (an RMSE of 0.345 with the ELL g -40 graph vs. 0.349 with the serial graph, in b oth cases using 3 features and the soft GC p ost-pro cessing metho d), but the computation time was 25 times larger. Although the shape of the slow est feature extracted with the serial graph might b e less similar to the lab el, a monotonic transformation of the slow est feature learned b y a nonlinear supervised step (e.g. soft GC) migh t suffice to appro ximate it. Ho wev er, the results sho w that if tw o or more (intrinsically connected) lab els are av ail- able, the accuracy of using ELL graphs ma y further increase. Efficien t pre-defined graphs 26 Optimal Free Responses of GSF A and the Design of Training Graphs are not a v ailable in this case. In the gender estimation exp erimen t, the RMSE w as impro v ed to 0.277 b y join tly learning gender and skin (ELL g ,c -(2 × 5) graph, 3 features, soft GC). Hence, a particularly promising application for the ELL metho d is multiple lab el learning. V arious metho ds for mapping the slo west feature to a lab el were tested. The linear scaling method is in teresting from a theoretical point of view. Ho wev er, as one w ould expect, it pro vided worse accuracy for test data than the soft GC metho d, which is nonlinear and sup ervised. Therefore, the latter migh t b e preferred in practical applications. Moreov er, in this scenario, sup ervised p ost-pro cessing metho ds might b e computationally inexp ensiv e, b ecause their input is frequently low-dimensional (e.g., we used 1 to 3 slo w features for gender estimation). Although ELL was originally designed for regression, w e sho w that it can also be useful for classification when particular lab els are learned. The exp erimen t on traffic sign classi- fication sho ws the b enefit of using compact discriminativ e features, implemented here b y learning m ultiple binary lab els. The resulting system has a m uch smaller classification error than the clustered graph (equiv alen t to nonlinear FDA) when the n um b er of output dimen- sions is less than C − 1, where C is the n umber of classes. One can com bine the metho d with HGSF A for classification with many classes, co ding the discriminativ e information in muc h few er than C − 1 features and reducing the num b er of signals computed in the net work, whic h migh t also reduce o verfitting. Although ideally log 2 ( C ) binary target lab els suffice for p erfect classification, the exp erimen ts sho w that additional target lab els via auxiliary lab els impro ve classification accuracy in practice. In terestingly , the clustered graph for C classes (equiv alent to FDA) and the compact+( C − 1) graph are equiv alent if the latter is constructed with constan t p ositiv e eigen v alues λ 1 = · · · = λ C − 1 = 1 / ( C − 1). The reason for this equiv alence is that this compact+( C − 1) graph w ould only h av e within-class transitions, because transitions betw een differen t classes cancel out each other. Therefore, the clustered graph can b e seen as a sp ecial case of the compact+( C − 1) graph, with maxim um lab el redundancy ( C − 1 target labels) and giving equal imp ortance (eigenv alues) to all of them. F uture work in the scope of ELL might include the construction of training graphs that are efficient (like the serial one) but at the same time offer the v ersatility of the ELL graphs. F or example, up to now, efficient (pre-defined) training graphs can only learn a single target lab el (and its higher-frequency harmonics). Therefore, we are interested in designing efficient graphs that allo w learning multiple lab els. Another p ossible application of ELL is the generation of (partially) sparse feature repre- sen tations. F or instance, for C = 8 classes, one migh t learn features ` 1 ( c ) = (2 , − 2 , 0 , 0 , 0 , 0 , 0 , 0), ` 2 ( c ) = (0 , 0 , 2 , − 2 , 0 , 0 , 0 , 0), ` 3 ( c ) = (0 , 0 , 0 , 0 , 0 , 0 , 2 , − 2 , 0 , 0), ` 4 ( c ) = (0 , 0 , 0 , 0 , 0 , 0 , 2 , − 2), ` 5 ( c ) = (2 1 / 2 , 2 1 / 2 , − 2 1 / 2 , − 2 1 / 2 , 0 , 0 , 0 , 0), ` 6 ( c ) = (0 , 0 , 0 , 0 , 2 1 / 2 , 2 1 / 2 , − 2 1 / 2 , − 2 1 / 2 ), and ` 7 ( c ) = (1 , 1 , 1 , 1 , − 1 , − 1 , − 1 , − 1). These features hav e zero mean, unit v ariance, and are decorrelated. F urthermore, ` 1 to ` 4 mak e the smallest p ossible contribution to the L 1 norm, thus this construction is greedy (it might not minimize the L 1 norm globally). An op en research question is how to choose the auxiliary lab els. It is clear they should dep end on the original lab el(s), but it is unclear ho w to compute them to maximize estima- tion accuracy , how man y of them should b e co ded, and whic h eigenv alues should b e used. F or classification with C = 32 classes, line arly decreasing eigenv alues (for the auxiliary lab els) pro vided great results, but other eigen v alues might b e better if C is very large. 27 Escalante-B. and Wiskott Hierarc hical pro cessing and the slo wness principle are t wo p o w erful brain-inspired learn- ing principles. The strength of SF A originates from its theoretical foundations in the field of learning of in v ariances and the generality of the slo wness principle. F or practical sup ervised learning applications, HGSF A provides go o d accuracy and efficiency and still profits from strong theoretical foundations. An adv an tage of relying on suc h general principles is that the resulting algorithms are application independent and not confined to a particular prob- lem or input feature represen tation. Of course, fine tuning the net work parameters and the in tegration of problem-specific knowledge are alw ays p ossible for additional p erformance. The prop osed method explores the limits of HGSF A and is v aluable as a theoretical tool for the analysis and design of training graphs. How ev er, the results sho w that with certain adaptations (e.g. the use of sup ervised p ost-processing) it is also sufficiently robust to b e applied to practical computer vision and mac hine learning tasks. References M. Belkin and P . Niy ogi. Laplacian eigenmaps for dimensionalit y reduction and data representation. Neur al Comput. , 15(6):1373–1396, June 2003. ISSN 0899-7667. P . Berkes. Pattern recognition with Slow Feature Analysis. Cognitiv e Sciences EPrin t Arc hive (CogPrin ts), F ebruary 2005a. URL http://cogprints.org/4104/ . P . Berkes. Handwritten digit recognition with nonlinear Fisher discriminant analysis. In ICANN , v olume 3697 of LNCS , pages 285–287. Springer Berlin/Heidelberg, 2005b. A. N. Escalante-B. and L. Wiskott. Heuristic ev aluation of expansions for non-linear hierarchical Slo w Feature Analysis. In Pr o c. The 10th International Confer enc e on Machine L e arning and Applic ations , pages 133–138, Los Alamitos, CA, USA, 2011. A. N. Escalan te-B. and L. Wiskott. Ho w to solve classification and regression problems on high- dimensional data with a sup ervised extension of Slow Feature Analysis. Journal of Machine L e arning R ese ar ch , 14:3683–3719, Decem b er 2013. P . F¨ oldi´ ak. Learning inv ariance from transformation sequences. Neur al Computation , 3(2):194–200, 1991. G. Guo and G. Mu. A framew ork for joint estimation of age, gender and ethnicity on a large database. Image Vision Comput. , 32(10):761–770, 2014. X. He and P . Niyogi. Lo calit y Preserving Pro jections. In Neur al Information Pr o c essing Systems , v olume 16, pages 153–160, 2003. G. E. Hinton. Connectionist learning procedures. Artificial Intel ligenc e , 40(1-3):185–234, 1989. S. Houb en, J. Stallk amp, J. Salmen, M. Schlipsing, and C. Igel. Detection of traffic signs in real- w orld images: The German Traffic Sign Detection Benc hmark. In International Joint Confer enc e on Neur al Networks , n umber 1288, 2013. S. Klampfl and W. Maass. Replacing sup ervised classification learning by Slow Feature Analysis in spiking neural netw orks. In Pr o c. of NIPS 2009: A dvanc es in Neur al Information Pr o c essing Systems , v olume 22, pages 988–996. MIT Press, 2010. 28 Optimal Free Responses of GSF A and the Design of Training Graphs N. Kr ¨ uger, P . Janssen, S. Kalk an, M. Lapp e, A. Leonardis, J. Piater, A. Ro driguez-Sanc hez, and L. Wisk ott. Deep hierarc hies in the primate visual cortex: What can we learn for computer vision? IEEE T r ansactions on Pattern Analysis and Machine Intel ligenc e , 35(8):1847–1871, 2013. G. Mitc hison. Remo ving time v ariation with the anti-Hebbian differential synapse. Neur al Compu- tation , 3(3):312–320, 1991. L. Wiskott. Learning in v ariance manifolds. In Pr o c. of 5th Joint Symp osium on Neur al Computation, San Die go, CA, USA , v olume 8, pages 196–203. Univ. of California, 1998. L. Wiskott. Slow F eature Analysis: A theoretical analysis of optimal free resp onses. Neur al Com- putation , 15(9):2147–2177, 2003. L. Wisk ott and T. Sejno wski. Slow Feature Analysis: Unsupervised learning of inv ariances. Neur al Computation , 14(4):715–770, 2002. 29
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment